- 朴素贝叶斯分类器
- 朴素贝叶斯分类器(1)
- Python朴素贝叶斯分类器(1)
- Python朴素贝叶斯分类器
- R编程中的朴素贝叶斯分类器(1)
- R编程中的朴素贝叶斯分类器
- 大数据分析-朴素贝叶斯分类器
- 大数据分析-朴素贝叶斯分类器(1)
- 用 WEKA 构建朴素贝叶斯分类器
- 用 WEKA 构建朴素贝叶斯分类器(1)
- Scikit学习-使用朴素贝叶斯进行分类
- Scikit学习-使用朴素贝叶斯进行分类(1)
- 分类算法-朴素贝叶斯
- 分类算法-朴素贝叶斯(1)
- 基于规则的分类器——机器学习
- 基于规则的分类器——机器学习(1)
- 特征重要性朴素贝叶斯python(1)
- 特征重要性朴素贝叶斯python代码示例
- 机器学习中的 P 值
- 机器学习中的 P 值(1)
- C++中的机器学习
- C++中的机器学习(1)
- 机器学习 (1)
- 将多项式朴素贝叶斯应用于NLP问题
- 将多项式朴素贝叶斯应用于NLP问题(1)
- 毫升 |使用Python实现朴素贝叶斯从头开始(1)
- 毫升 |使用Python实现朴素贝叶斯从头开始
- 机器学习 python (1)
- 机器学习 python 代码示例
📅 最后修改于: 2020-09-28 03:08:27 🧑 作者: Mango
朴素贝叶斯分类器算法
- 朴素贝叶斯算法是一种基于贝叶斯定理的监督学习算法,用于解决分类问题。
- 它主要用于包含高维训练数据集的文本分类中。
- 朴素贝叶斯分类器是最简单,最有效的分类算法之一,可帮助构建可以进行快速预测的快速机器学习模型。
- 它是一个概率分类器,这意味着它基于物体的概率进行预测 。
- 朴素贝叶斯算法的一些流行示例是垃圾邮件过滤,情感分析和文章分类 。
为什么叫朴素贝叶斯?
朴素贝叶斯算法由两个词朴素和贝叶斯组成,可以描述为:
- 朴素 :之所以称为朴素,是因为它假设某个特征的出现与其他特征的出现无关。例如,如果根据颜色,形状和口味识别出水果,则将红色,球形和甜美的水果识别为苹果。因此,每个功能单独地有助于识别它是一个苹果,而不会彼此依赖。
- 贝叶斯 :之所以称为贝叶斯,是因为它取决于贝叶斯定理的原理。
贝叶斯定理:
- 贝叶斯定理也称为贝叶斯 定律或贝叶斯定律 ,用于确定具有先验知识的假设的概率。这取决于条件概率。
- 贝叶斯定理的公式为:

哪里,
P(A | B)是后验概率:关于观察到的事件B的假设A的概率。
P(B | A)是似然概率:假设假设的概率为真时,证据的概率。
P(A)是先验概率:在观察证据之前假设的概率。
P(B)是边际概率:证据概率。
朴素贝叶斯分类器的工作:
可以通过以下示例了解朴素贝叶斯分类器的工作方式:
假设我们有一个天气数据集和相应的目标变量“ Play”。因此,使用该数据集,我们需要根据天气情况决定是否应该在特定的一天玩游戏。因此,要解决此问题,我们需要执行以下步骤:
- 将给定的数据集转换为频率表。
- 通过查找给定特征的概率来生成似然表。
- 现在,使用贝叶斯定理来计算后验概率。
问题:如果天气晴朗,那么播放器应该播放还是不播放?
解决方案:要解决此问题,请首先考虑以下数据集:
| Outlook | Play | |
|---|---|---|
| 0 | Rainy | Yes |
| 1 | Sunny | Yes |
| 2 | Overcast | Yes |
| 3 | Overcast | Yes |
| 4 | Sunny | No |
| 5 | Rainy | Yes |
| 6 | Sunny | Yes |
| 7 | Overcast | Yes |
| 8 | Rainy | No |
| 9 | Sunny | No |
| 10 | Sunny | Yes |
| 11 | Rainy | No |
| 12 | Overcast | Yes |
| 13 | Overcast | Yes |
天气情况频率表:
| Weather | Yes | No |
| Overcast | 5 | 0 |
| Rainy | 2 | 2 |
| Sunny | 3 | 2 |
| Total | 10 | 5 |
可能性表天气状况:
| Weather | No | Yes | |
| Overcast | 0 | 5 | 5/14= 0.35 |
| Rainy | 2 | 2 | 4/14=0.29 |
| Sunny | 2 | 3 | 5/14=0.35 |
| All | 4/14=0.29 | 10/14=0.71 |
应用贝叶斯定理:
P(是|晴天)= P(是晴天)* P(是)/ P(晴天)
P(晴天|是)= 3/10 = 0.3
P(晴天)= 0.35
P(是)= 0.71
因此P(是|晴天)= 0.3 * 0.71 / 0.35 = 0.60
P(否|晴天)= P(晴天|否)* P(否)/ P(晴天)
P(晴天|否)= 2/4 = 0.5
P(否)= 0.29
P(晴天)= 0.35
因此P(否|晴天)= 0.5 * 0.29 / 0.35 = 0.41
因此,从上面的计算中我们可以看出,P(是|晴天)> P(否|晴天)
因此,在晴天,玩家可以玩游戏。
朴素贝叶斯分类器的优点:
- 朴素贝叶斯是预测一类数据集的快速简便的机器学习算法之一。
- 它可以用于二进制以及多类分类。
- 与其他算法相比,它在多类别预测中表现良好。
- 这是用于文本分类问题的最受欢迎的选择。
朴素贝叶斯分类器的缺点:
- 朴素贝叶斯假设所有功能都是独立的或不相关的,因此它无法学习功能之间的关系。
朴素贝叶斯分类器的应用:
- 它用于信用计分 。
- 它用于医学数据分类 。
- 它可以用于实时预测,因为朴素贝叶斯分类器是一个渴望学习的人。
- 它用于文本分类,例如垃圾邮件过滤和情感分析 。
朴素贝叶斯模型的类型:
朴素贝叶斯模型分为以下三种:
- 高斯 :高斯模型假设特征服从正态分布。这意味着,如果预测变量采用连续值而不是离散值,则该模型将假定这些值是从高斯分布中采样的。
- 多项式 :当数据是多项分布时,使用“朴素贝叶斯”多项式分类器。它主要用于文档分类问题,表示特定文档属于哪个类别,例如体育,政治,教育等。
分类器使用单词的频率作为预测变量。 - Bernoulli :Bernoulli分类器的工作方式类似于多项式分类器,但是预测变量是独立的布尔变量。例如文档中是否存在特定单词。该模型还以文档分类任务而闻名。
朴素贝叶斯算法的Python实现:
现在,我们将使用Python实现朴素贝叶斯算法。因此,为此,我们将使用在其他分类模型中使用的“ user_data”数据集。因此,我们可以轻松地将朴素贝叶斯模型与其他模型进行比较。
实施步骤:
- 数据预处理步骤
- 使朴素贝叶斯适应训练组
- 预测测试结果
- 测试结果的准确性(创建混淆矩阵)
- 可视化测试集结果。
1)数据预处理步骤:
在此步骤中,我们将预处理/准备数据,以便我们可以在代码中有效地使用它。这与我们在数据预处理中所做的相似。下面给出了此代码:
Importing the libraries
import numpy as nm
import matplotlib.pyplot as mtp
import pandas as pd
# Importing the dataset
dataset = pd.read_csv('user_data.csv')
x = dataset.iloc[:, [2, 3]].values
y = dataset.iloc[:, 4].values
# Splitting the dataset into the Training set and Test set
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.25, random_state = 0)
# Feature Scaling
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
x_train = sc.fit_transform(x_train)
x_test = sc.transform(x_test)
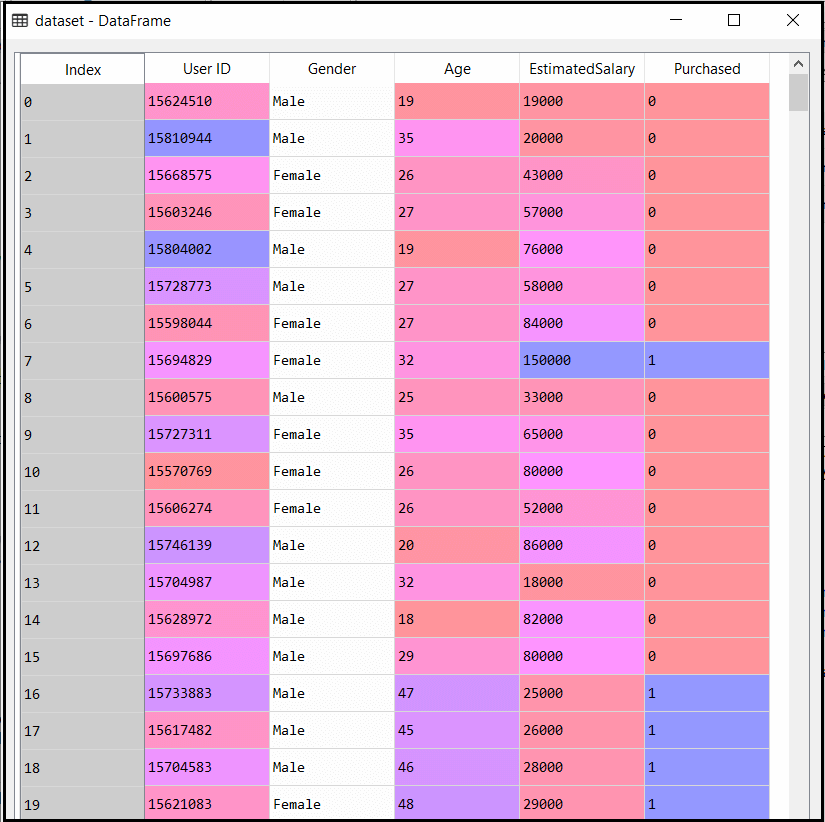
在上面的代码中,我们使用“ dataset = pd.read_csv(‘user_data.csv’)”将数据集加载到程序中。加载的数据集分为训练集和测试集,然后缩放了特征变量。
数据集的输出为:
2)使朴素贝叶斯适合训练集:
在预处理步骤之后,现在我们将朴素贝叶斯模型拟合到Training set。下面是它的代码:
# Fitting Naive Bayes to the Training set
from sklearn.naive_bayes import GaussianNB
classifier = GaussianNB()
classifier.fit(x_train, y_train)
在上面的代码中,我们使用了GaussianNB分类器将其拟合到训练数据集。我们还可以根据需要使用其他分类器。
输出:
Out[6]: GaussianNB(priors=None, var_smoothing=1e-09)
3)测试集结果的预测:
现在我们将预测测试集的结果。为此,我们将创建一个新的预测变量y_pred,并将使用预测函数进行预测。
# Predicting the Test set results
y_pred = classifier.predict(x_test)
输出:
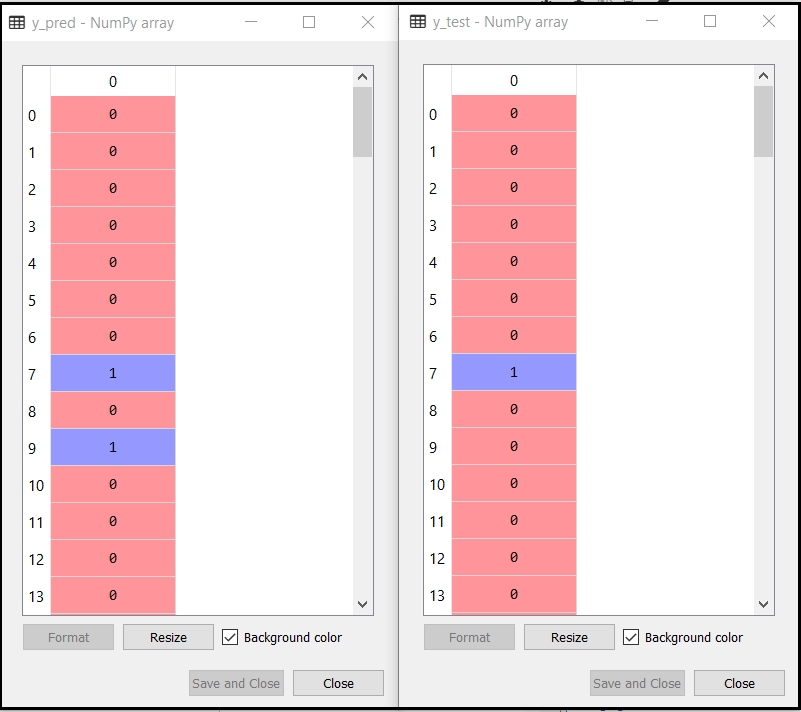
上面的输出显示了预测向量y_pred和实向量y_test的结果。我们可以看到,某些预测与实际值不同,这是不正确的预测。
4)创建混淆矩阵:
现在,我们将使用混淆矩阵检查朴素贝叶斯分类器的准确性。下面是它的代码:
# Making the Confusion Matrix
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
输出:
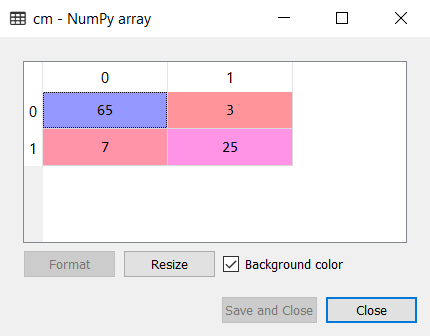
从上面的混淆矩阵输出中可以看到,有7 + 3 = 10个错误的预测,而65 + 25 = 90个正确的预测。
5)可视化训练集结果:
接下来,我们将使用朴素贝叶斯分类器可视化训练集结果。下面是它的代码:
# Visualising the Training set results
from matplotlib.colors import ListedColormap
x_set, y_set = x_train, y_train
X1, X2 = nm.meshgrid(nm.arange(start = x_set[:, 0].min() - 1, stop = x_set[:, 0].max() + 1, step = 0.01),
nm.arange(start = x_set[:, 1].min() - 1, stop = x_set[:, 1].max() + 1, step = 0.01))
mtp.contourf(X1, X2, classifier.predict(nm.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('purple', 'green')))
mtp.xlim(X1.min(), X1.max())
mtp.ylim(X2.min(), X2.max())
for i, j in enumerate(nm.unique(y_set)):
mtp.scatter(x_set[y_set == j, 0], x_set[y_set == j, 1],
c = ListedColormap(('purple', 'green'))(i), label = j)
mtp.title('Naive Bayes (Training set)')
mtp.xlabel('Age')
mtp.ylabel('Estimated Salary')
mtp.legend()
mtp.show()
输出:
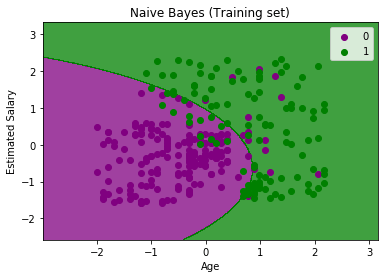
在上面的输出中,我们可以看到朴素贝叶斯分类器已将数据点与精细边界隔离。这是高斯曲线,因为我们在代码中使用了高斯NB分类器。
6)可视化测试设置结果:
# Visualising the Test set results
from matplotlib.colors import ListedColormap
x_set, y_set = x_test, y_test
X1, X2 = nm.meshgrid(nm.arange(start = x_set[:, 0].min() - 1, stop = x_set[:, 0].max() + 1, step = 0.01),
nm.arange(start = x_set[:, 1].min() - 1, stop = x_set[:, 1].max() + 1, step = 0.01))
mtp.contourf(X1, X2, classifier.predict(nm.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('purple', 'green')))
mtp.xlim(X1.min(), X1.max())
mtp.ylim(X2.min(), X2.max())
for i, j in enumerate(nm.unique(y_set)):
mtp.scatter(x_set[y_set == j, 0], x_set[y_set == j, 1],
c = ListedColormap(('purple', 'green'))(i), label = j)
mtp.title('Naive Bayes (test set)')
mtp.xlabel('Age')
mtp.ylabel('Estimated Salary')
mtp.legend()
mtp.show()
输出:
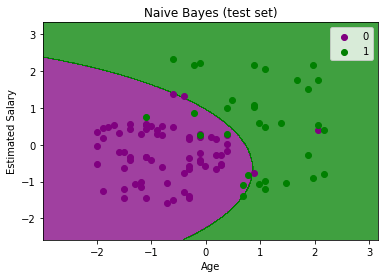
上面的输出是测试集数据的最终输出。如我们所见,分类器创建了高斯曲线以划分“已购买”和“未购买”变量。我们在混淆矩阵中计算出了一些错误的预测。但这仍然是一个很好的分类器。