使用 Pandas 进行分组和聚合
在本文中,我们将看到使用 Pandas 进行分组和聚合。分组和聚合将有助于使用各种功能轻松实现数据分析。这些方法将帮助我们进行分组和汇总我们的数据,并使复杂的分析变得相对容易。
创建各种主题标记的示例数据集。
Python
# import module
import pandas as pd
# Creating our dataset
df = pd.DataFrame([[9, 4, 8, 9],
[8, 10, 7, 6],
[7, 6, 8, 5]],
columns=['Maths', 'English',
'Science', 'History'])
# display dataset
print(df)Python
df.sum()Python
df.describe()Python
df.agg(['sum', 'min', 'max'])Python
df.groupby(by=['Maths'])Python
a = df.groupby('Maths')
a.first()Python
b = df.groupby(['Maths', 'Science'])
b.first()Python
# import module
import numpy as np
import pandas as pd
# reading csv file
dataset = pd.read_csv("diamonds.csv")
# printing first 5 rows
print(dataset.head(5))Python
dataset.groupby('cut').sum()Python
dataset.groupby(['cut', 'color']).agg('min')Python
# dictionary having key as group name of price and
# value as list of aggregation function
# we want to perform on group price
agg_functions = {
'price':
['sum', 'mean', 'median', 'min', 'max', 'prod']
}
dataset.groupby(['color']).agg(agg_functions)输出:

Pandas 中的聚合
pandas 中的聚合提供了各种函数,可以对我们的数据集执行数学或逻辑运算并返回该函数的摘要。聚合可用于获取数据集中列的摘要,例如从数据集的特定列中获取总和、最小值、最大值等。用于聚合的函数是agg(),参数就是我们要执行的函数。
聚合中使用的一些函数是:
Function Description:
- sum() :Compute sum of column values
- min() :Compute min of column values
- max() :Compute max of column values
- mean() :Compute mean of column
- size() :Compute column sizes
- describe() :Generates descriptive statistics
- first() :Compute first of group values
- last() :Compute last of group values
- count() :Compute count of column values
- std() :Standard deviation of column
- var() :Compute variance of column
- sem() :Standard error of the mean of column
例子:
- sum()函数用于计算每个值的总和。
Python
df.sum()
输出:

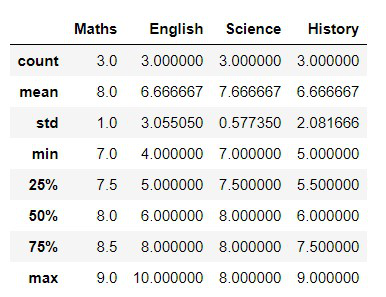
- describe()函数用于获取我们数据集的摘要
Python
df.describe()
输出:
- 我们使用 agg()函数计算数据集中每列的总和、最小值和最大值。
Python
df.agg(['sum', 'min', 'max'])
输出:

在 Pandas 中分组
分组用于使用我们数据集中的某些标准对数据进行分组。它用作拆分-应用-组合策略。
- 根据某些标准将数据分组。
- 对每个组独立应用一个函数。
- 将结果组合成数据结构。
例子:
我们使用 groupby()函数根据“数学”值对数据进行分组。它返回对象作为结果。
Python
df.groupby(by=['Maths'])
输出:
应用 groupby()函数对“数学”值上的数据进行分组。要查看已形成组的结果,请使用 first()函数。
Python
a = df.groupby('Maths')
a.first()
输出:
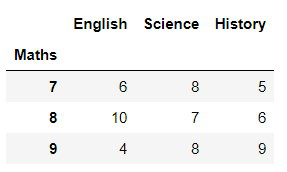
每个团队中基于“数学”的第一个分组我们根据“科学”分组
Python
b = df.groupby(['Maths', 'Science'])
b.first()
输出:

在数据集上实现
这里我们使用的是钻石信息数据集。
Python
# import module
import numpy as np
import pandas as pd
# reading csv file
dataset = pd.read_csv("diamonds.csv")
# printing first 5 rows
print(dataset.head(5))
输出:

- 我们使用 cut 进行分组并获得所有列的总和。
Python
dataset.groupby('cut').sum()
输出:

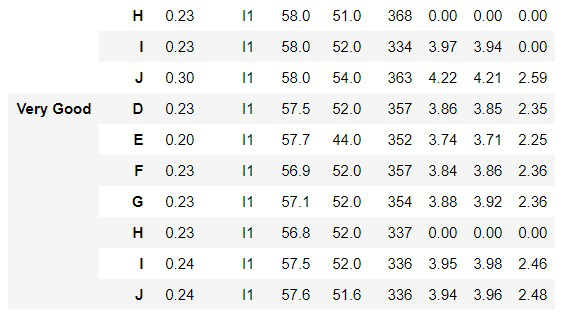
- 在这里,我们使用剪切和颜色进行分组,并为所有其他组获取最小值。
Python
dataset.groupby(['cut', 'color']).agg('min')
输出:

- 在这里,我们使用颜色进行分组并获取价格组的总和、均值、最小值等汇总值。
Python
# dictionary having key as group name of price and
# value as list of aggregation function
# we want to perform on group price
agg_functions = {
'price':
['sum', 'mean', 'median', 'min', 'max', 'prod']
}
dataset.groupby(['color']).agg(agg_functions)
输出:
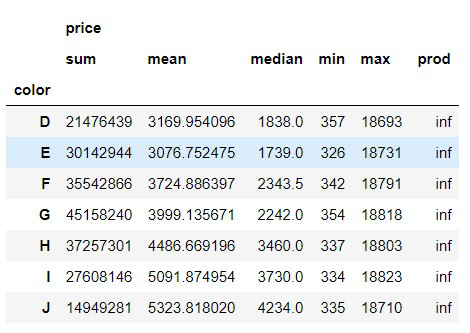
我们可以看到在 prod(product ie multiplication) 列中所有值都是 inf,inf 是数学上无穷大的数值计算的结果。