Pandas Groupby:在Python汇总、聚合和分组数据
GroupBy是一个非常简单的概念。我们可以创建一组类别并将函数应用于这些类别。这是一个简单的概念,但它是一种极其有价值的技术,广泛用于数据科学。在实际的数据科学项目中,您将处理大量数据并反复尝试,因此为了效率,我们使用 Groupby 概念。 Groupby 概念非常重要,因为它能够有效地汇总、聚合和分组数据。
总结
汇总包括计数、描述数据帧中存在的所有数据。我们可以使用 describe() 方法总结数据框中存在的数据。此方法用于从数据框中获取最小值、最大值、总和、计数值以及该特定列的数据类型。
- describe():该方法详细说明了数据的类型及其属性。
句法:
dataframe_name.describe()
- unique():此方法用于从给定列中获取所有唯一值。
句法:
dataframe[‘column_name].unique()
- nunique():这个方法类似于unique,但它会返回唯一值的计数。
句法:
dataframe_name[‘column_name].nunique()
- info():该命令用于获取数据类型和列信息
句法:
dataframe.info()
- 列:此命令用于显示数据框中存在的所有列名称
句法:
dataframe.columns
例子:
我们将在此示例中分析学生分数数据。
Python3
# importing pandas as pd for using data frame
import pandas as pd
# creating dataframe with student details
dataframe = pd.DataFrame({'id': [7058, 4511, 7014, 7033],
'name': ['sravan', 'manoj', 'aditya', 'bhanu'],
'Maths_marks': [99, 97, 88, 90],
'Chemistry_marks': [89, 99, 99, 90],
'telugu_marks': [99, 97, 88, 80],
'hindi_marks': [99, 97, 56, 67],
'social_marks': [79, 97, 78, 90], })
# display dataframe
dataframePython3
# describing the data frame
print(dataframe.describe())
print("-----------------------------")
# finding unique values
print(dataframe['Maths_marks'].unique())
print("-----------------------------")
# counting unique values
print(dataframe['Maths_marks'].nunique())
print("-----------------------------")
# display the columns in the data frame
print(dataframe.columns)
print("-----------------------------")
# information about dataframe
print(dataframe.info())Python3
# importing pandas as pd for using data frame
import pandas as pd
# creating dataframe with student details
dataframe = pd.DataFrame({'id': [7058, 4511, 7014, 7033],
'name': ['sravan', 'manoj', 'aditya', 'bhanu'],
'Maths_marks': [99, 97, 88, 90],
'Chemistry_marks': [89, 99, 99, 90],
'telugu_marks': [99, 97, 88, 80],
'hindi_marks': [99, 97, 56, 67],
'social_marks': [79, 97, 78, 90], })
# display dataframe
dataframePython3
# getting all minimum values from
# all columns in a dataframe
print(dataframe.min())
print("-----------------------------------------")
# minimum value from a particular
# column in a data frame
print(dataframe['Maths_marks'].min())
print("-----------------------------------------")
# computing maximum values
print(dataframe.max())
print("-----------------------------------------")
# computing sum
print(dataframe.sum())
print("-----------------------------------------")
# finding count
print(dataframe.count())
print("-----------------------------------------")
# computing standard deviation
print(dataframe.std())
print("-----------------------------------------")
# computing variance
print(dataframe.var())Python3
# importing pandas as pd for using data frame
import pandas as pd
# creating dataframe with student details
dataframe = pd.DataFrame({'id': [7058, 4511, 7014, 7033],
'name': ['sravan', 'manoj', 'aditya', 'bhanu'],
'Maths_marks': [99, 97, 88, 90],
'Chemistry_marks': [89, 99, 99, 90],
'telugu_marks': [99, 97, 88, 80],
'hindi_marks': [99, 97, 56, 67],
'social_marks': [79, 97, 78, 90], })
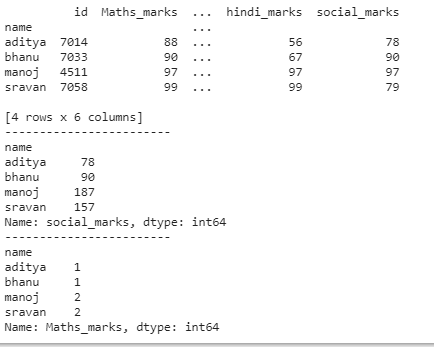
# group by name
print(dataframe.groupby('name').first())
print("---------------------------------")
# group by name with soxial_marks sum
print(dataframe.groupby('name')['social_marks'].sum())
print("---------------------------------")
# group by name with maths_marks count
print(dataframe.groupby('name')['Maths_marks'].count())
print("---------------------------------")
# group by name with maths_marks
print(dataframe.groupby('name')['Maths_marks'])Python3
# importing pandas as pd for using data frame
import pandas as pd
# creating dataframe with student details
dataframe = pd.DataFrame({'id': [7058, 4511, 7014, 7033],
'name': ['sravan', 'manoj', 'aditya', 'bhanu'],
'Maths_marks': [99, 97, 88, 90],
'Chemistry_marks': [89, 99, 99, 90],
'telugu_marks': [99, 97, 88, 80],
'hindi_marks': [99, 97, 56, 67],
'social_marks': [79, 97, 78, 90], })
# group by name
print(dataframe.groupby('name').first())
print("------------------------")
# group by name with soxial_marks sum
print(dataframe.groupby('name')['social_marks'].sum())
print("------------------------")
# group by name with maths_marks count
print(dataframe.groupby('name')['Maths_marks'].count())输出:

蟒蛇3
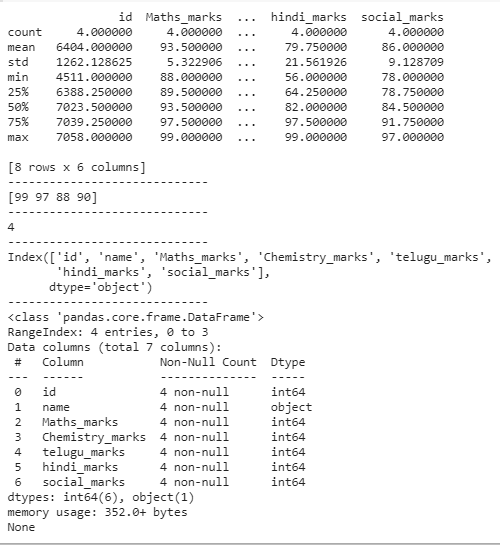
# describing the data frame
print(dataframe.describe())
print("-----------------------------")
# finding unique values
print(dataframe['Maths_marks'].unique())
print("-----------------------------")
# counting unique values
print(dataframe['Maths_marks'].nunique())
print("-----------------------------")
# display the columns in the data frame
print(dataframe.columns)
print("-----------------------------")
# information about dataframe
print(dataframe.info())
输出:
聚合
聚合用于获取数据框中所有列或数据框中特定列的均值、平均值、方差和标准差。
- sum():它返回数据帧的总和
句法:
dataframe[‘column].sum()
- mean():它返回数据框中特定列的平均值
句法:
dataframe[‘column].mean()
- std():它返回该列的标准偏差。
句法:
dataframe[‘column].std()
- var():它返回该列的方差
dataframe[‘column’].var()
- min():返回列中的最小值
句法:
dataframe[‘column’].min()
- 最大():它 返回列中的最大值
句法:
dataframe[‘column’].max()
例子:
在下面的程序中,我们将汇总数据。
蟒蛇3
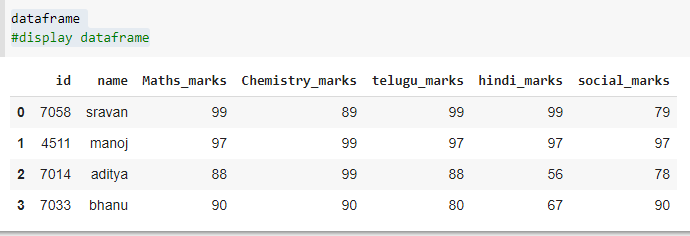
# importing pandas as pd for using data frame
import pandas as pd
# creating dataframe with student details
dataframe = pd.DataFrame({'id': [7058, 4511, 7014, 7033],
'name': ['sravan', 'manoj', 'aditya', 'bhanu'],
'Maths_marks': [99, 97, 88, 90],
'Chemistry_marks': [89, 99, 99, 90],
'telugu_marks': [99, 97, 88, 80],
'hindi_marks': [99, 97, 56, 67],
'social_marks': [79, 97, 78, 90], })
# display dataframe
dataframe
输出:
蟒蛇3
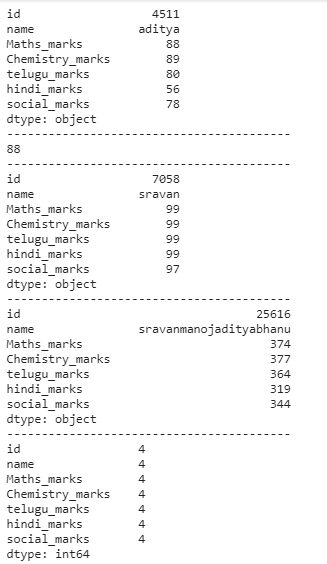
# getting all minimum values from
# all columns in a dataframe
print(dataframe.min())
print("-----------------------------------------")
# minimum value from a particular
# column in a data frame
print(dataframe['Maths_marks'].min())
print("-----------------------------------------")
# computing maximum values
print(dataframe.max())
print("-----------------------------------------")
# computing sum
print(dataframe.sum())
print("-----------------------------------------")
# finding count
print(dataframe.count())
print("-----------------------------------------")
# computing standard deviation
print(dataframe.std())
print("-----------------------------------------")
# computing variance
print(dataframe.var())
输出:

分组
它用于使用 groupby() 方法对数据框中的一列或多列进行分组。 Groupby主要是指一个涉及以下一个或多个步骤的过程,它们分别是:
- 拆分:这是我们通过对数据集应用某些条件将数据拆分为组的过程。
- 应用:这是一个我们独立地对每个组应用一个函数的过程
- 合并:是我们在应用groupby后合并不同数据集并产生数据结构的过程
示例 1:
蟒蛇3
# importing pandas as pd for using data frame
import pandas as pd
# creating dataframe with student details
dataframe = pd.DataFrame({'id': [7058, 4511, 7014, 7033],
'name': ['sravan', 'manoj', 'aditya', 'bhanu'],
'Maths_marks': [99, 97, 88, 90],
'Chemistry_marks': [89, 99, 99, 90],
'telugu_marks': [99, 97, 88, 80],
'hindi_marks': [99, 97, 56, 67],
'social_marks': [79, 97, 78, 90], })
# group by name
print(dataframe.groupby('name').first())
print("---------------------------------")
# group by name with soxial_marks sum
print(dataframe.groupby('name')['social_marks'].sum())
print("---------------------------------")
# group by name with maths_marks count
print(dataframe.groupby('name')['Maths_marks'].count())
print("---------------------------------")
# group by name with maths_marks
print(dataframe.groupby('name')['Maths_marks'])
输出:
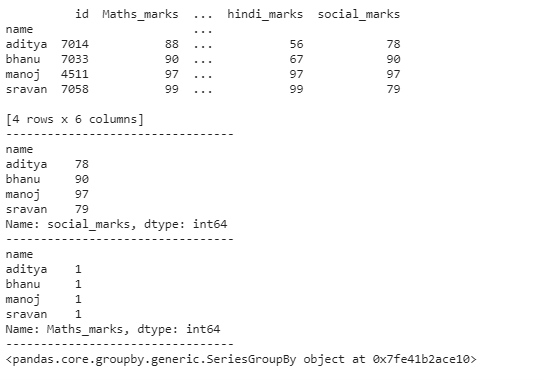
示例 2:
蟒蛇3
# importing pandas as pd for using data frame
import pandas as pd
# creating dataframe with student details
dataframe = pd.DataFrame({'id': [7058, 4511, 7014, 7033],
'name': ['sravan', 'manoj', 'aditya', 'bhanu'],
'Maths_marks': [99, 97, 88, 90],
'Chemistry_marks': [89, 99, 99, 90],
'telugu_marks': [99, 97, 88, 80],
'hindi_marks': [99, 97, 56, 67],
'social_marks': [79, 97, 78, 90], })
# group by name
print(dataframe.groupby('name').first())
print("------------------------")
# group by name with soxial_marks sum
print(dataframe.groupby('name')['social_marks'].sum())
print("------------------------")
# group by name with maths_marks count
print(dataframe.groupby('name')['Maths_marks'].count())
输出: