强化学习:
强化学习是机器学习的一种。它允许机器和软件代理在特定情况下自动确定理想的行为,以最大化其性能。代理商需要简单的奖励反馈来了解其行为;这就是增强信号。
有许多不同的算法可以解决此问题。实际上,强化学习是由特定类型的问题定义的,其所有解决方案都归类为强化学习算法。在该问题中,代理应该根据其当前状态决定要选择的最佳操作。重复此步骤后,该问题称为“马尔可夫决策过程” 。
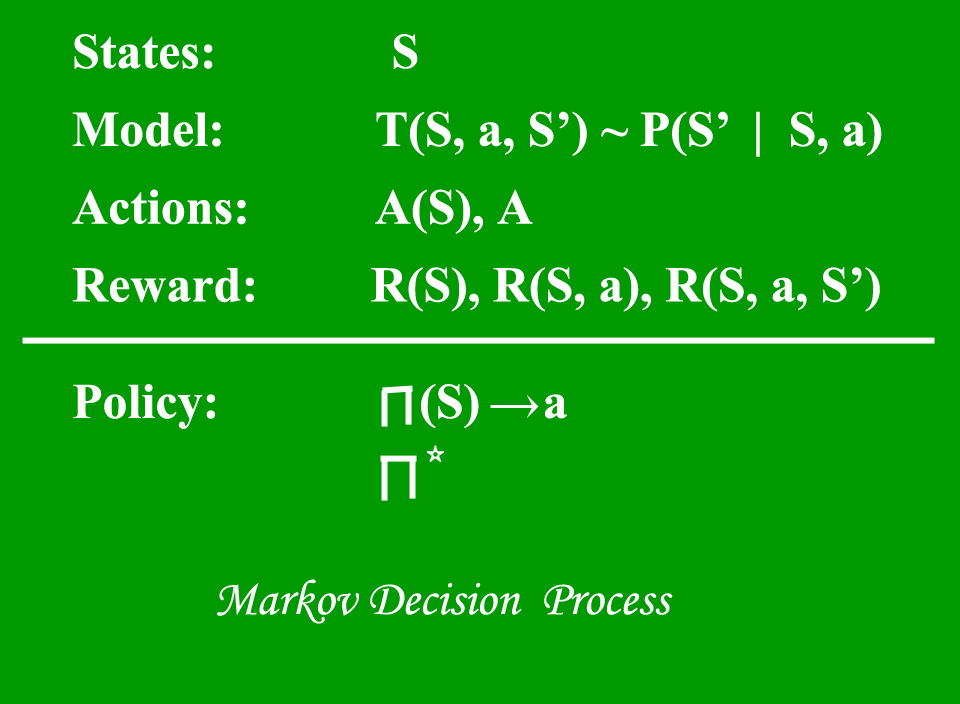
马尔可夫决策过程(MDP)模型包含:
- 一组可能的世界状态S。
- 一组模型。
- 一组可能的动作A。
- 实值奖励函数R(s,a)。
- 马尔可夫决策过程的一种政策解决方法。
什么是国家?
状态是一组令牌,代表代理可以处于的每个状态。
什么是模型?
模型(有时称为过渡模型)在状态下提供动作的效果。特别是,T(S,a,S’)定义了过渡T,其中处于状态S并采取动作“ a”将我们带到状态S’(S和S’可以相同)。对于随机动作(嘈杂,不确定的),我们还定义了概率P(S’| S,a),该概率表示如果在状态S中执行动作’a’时到达状态S’的概率。在一个状态中采取的行动的效果仅取决于该状态,而不取决于先前的历史记录。
什么是动作?
动作A是所有可能动作的集合。 A(多个)定义了在状态S下可以采取的一组操作。
什么是奖励?
奖励是实值奖励函数。 R(s)表示仅处于状态S的奖励。R(S,a)表示对处于状态S并采取动作“ a”的奖励。 R(S,a,S’)表示处于状态S,采取动作’a’并最终进入状态S’的奖励。
什么是政策?
政策是马尔可夫决策过程的一种解决方案。策略是从S到a的映射。它指示在状态S时要采取的动作“ a”。
让我们以网格世界为例:
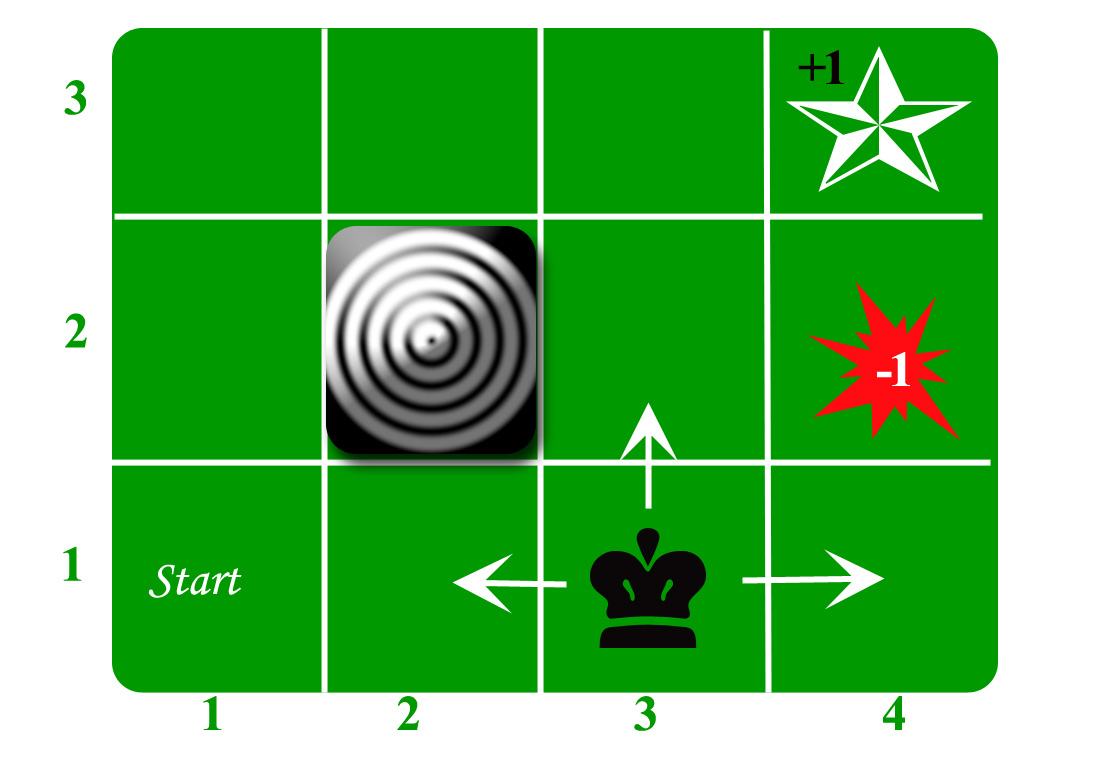
代理人生活在网格中。上面的示例是一个3 * 4的网格。网格具有START状态(网格编号1,1)。该代理的目的是在网格周围徘徊以最终到达“蓝色钻石”(网格编号4,3)。在任何情况下,代理都应避开防火网格(橙色,网格编号4,2)。同样,第2,2号网格也是一个封闭的网格,它的作用就像一堵墙,因此代理无法进入。
座席可以执行以下任一操作:上,下,左,右
墙壁阻碍了代理人的路径,即,如果在代理人本应采取的方向上有一堵墙,则代理人将停留在同一位置。因此,例如,如果业务代表在“开始”网格中说“左”,则他将停留在“开始”网格中。
首要目标:寻找从START到Diamond的最短序列。可以找到两个这样的序列:
- 正确正确正确正确
- UP UP RIGHT RIGHT RIGHT
让我们以第二个(后上右下右)进行后续讨论。
此举现在很吵。 80%的预期操作正确运行。动作剂花费20%的时间使它以直角移动。例如,如果代理说UP,则UP的概率为0.8,而LEFT的概率为0.1,RIGHT的概率为0.1(因为LEFT和RIGHT与UP成直角)。
代理人在每个步骤中都会收到奖励:-
- 每一步的小报酬(有时可以是负数,也可以称为惩罚,在上述示例中,进入大火可以获得-1的奖励)。
- 丰厚的回报来自最后(好或坏)。
- 目标是最大限度地提高奖励总和。
参考:http://reinforcementlearning.ai-depot.com/
http://artint.info/html/ArtInt_224.html