- 决策树算法属于监督学习类别。它们可用于解决回归和分类问题。
- 决策树使用树表示来解决以下问题:每个叶节点对应一个类标签,并且属性在树的内部节点上表示。
- 我们可以使用决策树来表示离散属性上的任何布尔函数。
以下是我们在使用决策树时所做的一些假设:
- 在开始时,我们将整个培训集作为基础。
- 特征值最好是分类的。如果值是连续的,则在构建模型之前将其离散化。
- 根据属性值,记录是递归分布的。
- 我们使用统计方法对作为根或内部节点的属性进行排序。
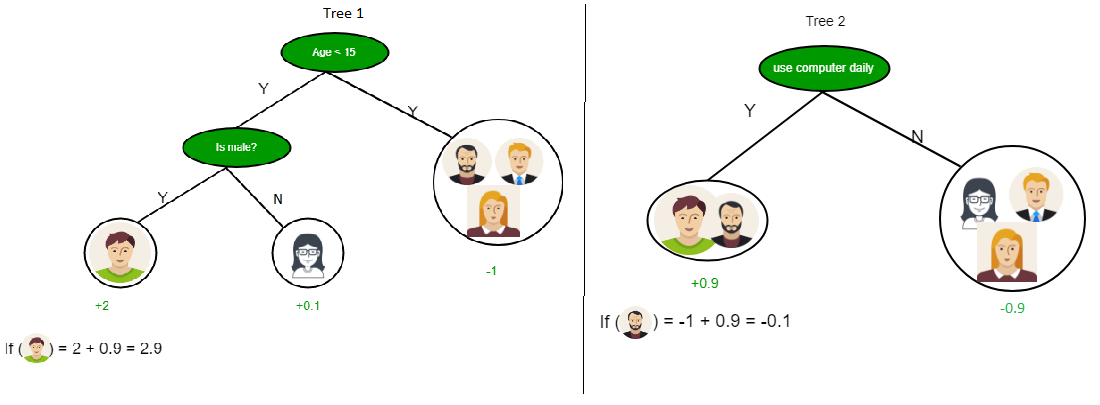
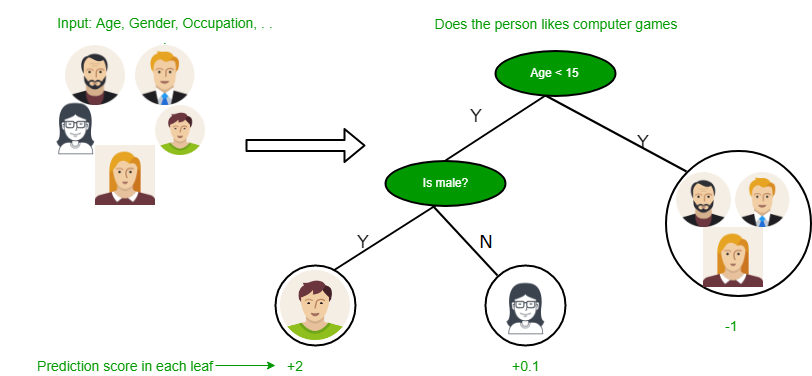
从上图可以看到,决策树在乘积和形式下工作,该形式也称为“相异范式” 。在上图中,我们预测人们日常生活中将使用计算机。
在决策树中,主要挑战是识别每个级别中根节点的属性。此过程称为属性选择。我们有两种流行的属性选择措施:
- 信息增益
- 基尼指数
1.信息获取
当我们使用决策树中的节点将训练实例划分为较小的子集时,熵会发生变化。信息增益是熵变化的量度。
定义:假设S是一组实例,A是一个属性,S v是具有A = v的S的子集,而值(A)是A的所有可能值的集合,则![]()
熵
熵是对随机变量不确定性的度量,它表征了任意示例集合的不纯性。熵越高,信息内容越多。
定义:假设S是一组实例,A是一个属性,S v是具有A = v的S的子集,而值(A)是A的所有可能值的集合,则![]()
例子:
对于集合X = {a,a,a,b,b,b,b,b}总实例:8个b实例:5个a实例:3 ![]() =-[0.375 *(-1.415)+ 0.625 *(-0.678)] =-(-0.53-0.424)= 0.954
=-[0.375 *(-1.415)+ 0.625 *(-0.678)] =-(-0.53-0.424)= 0.954
使用信息增益构建决策树
要点:
- 从与根节点关联的所有训练实例开始
- 使用信息增益来选择使用哪个属性标记每个节点
- 注意:根到叶路径不应两次包含相同的离散属性
- 在训练实例的子集上递归构造每个子树,训练实例的子集将沿着树中的该路径分类。
边境案件:
- 如果所有正面或负面训练实例都保留,则相应地将该节点标记为“是”或“否”
- 如果没有剩余属性,则使用该节点上剩下的训练实例的多数票进行标记
- 如果没有剩余实例,则以父母的训练实例的多数票标记
例子:
现在,让我们使用信息增益为以下数据绘制决策树。
| X | Y | Z | C |
|---|---|---|---|
| 1 | 1 | 1 | I |
| 1 | 1 | 0 | I |
| 0 | 0 | 1 | II |
| 1 | 0 | 0 | II |
在这里,我们有3个功能部件和2个输出类。
使用信息增益构建决策树。我们将采用每个功能并计算每个功能的信息。 
在功能X上分割
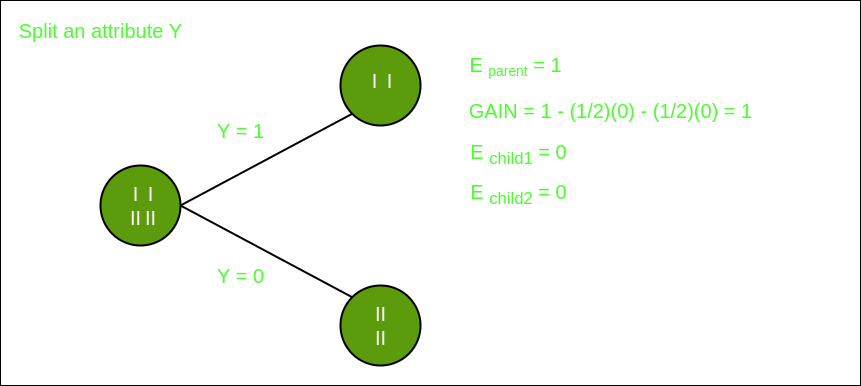
在特征Y上分割
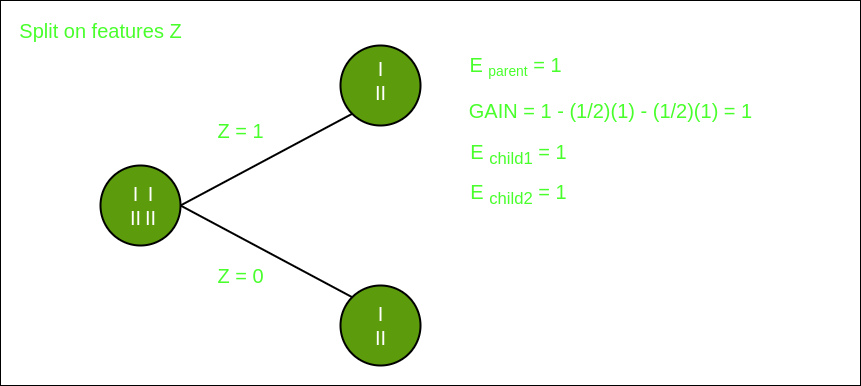
在功能Z上分割
从上面的图像中,我们可以看到,当对特征Y进行分割时,信息增益最大。因此,对于最适合特征的根节点是特征Y。现在我们可以看到,按特征Y分割数据集时,子级包含目标变量的纯子集。因此,我们不需要进一步拆分数据集。
以上数据集的最终树如下所示: 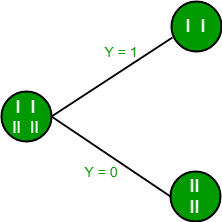
2.基尼系数
- 基尼系数(Gini Index)是一种度量标准,用于衡量随机选择的元素被错误识别的频率。
- 这意味着应首选具有较低Gini索引的属性。
- Sklearn支持基尼指数的“基尼”标准,默认情况下,它采用“基尼”值。
- 基尼指数的计算公式如下。

例子:
让我们考虑下图中的数据集,并使用gini索引绘制决策树。Index A B C D E 1 4.8 3.4 1.9 0.2 positive 2 5 3 1.6 1.2 positive 3 5 3.4 1.6 0.2 positive 4 5.2 3.5 1.5 0.2 positive 5 5.2 3.4 1.4 0.2 positive 6 4.7 3.2 1.6 0.2 positive 7 4.8 3.1 1.6 0.2 positive 8 5.4 3.4 1.5 0.4 positive 9 7 3.2 4.7 1.4 negative 10 6.4 3.2 4.7 1.5 negative 11 6.9 3.1 4.9 1.5 negative 12 5.5 2.3 4 1.3 negative 13 6.5 2.8 4.6 1.5 negative 14 5.7 2.8 4.5 1.3 negative 15 6.3 3.3 4.7 1.6 negative 16 4.9 2.4 3.3 1 negative 在上面的数据集中,有5个属性,其中属性E是包含2个(正和负)类的预测特征。两种课程的比例相等。
在基尼系数中,我们必须选择一些随机值来对每个属性进行分类。此数据集的这些值为:A B C D >= 5 >= 3.0 >= 4.2 >= 1.4 < 5 < 3.0 < 4.2 < 1.4计算变量A的基尼系数:
值> = 5:12
属性A> = 5且类别=正:
属性A> = 5且类=否:
基尼(5,7)= 1 –![\left [ \left ( \frac{5}{12} \right )^{2} + \left ( \frac{7}{12} \right )^{2}\right ] = 0.4860](https://mangdo-1254073825.cos.ap-chengdu.myqcloud.com//front_eng_imgs/geeksforgeeks2021/Decision%20Tree%20Introduction%20with%20example_12.jpg "由QuickLaTeX.com渲染")
值<5:4
属性A <5和类别=正:
属性A <5&class =否:
基尼(3,1)= 1 –![\left [ \left ( \frac{3}{4} \right )^{2} + \left ( \frac{1}{4} \right )^{2}\right ] = 0.375](https://mangdo-1254073825.cos.ap-chengdu.myqcloud.com//front_eng_imgs/geeksforgeeks2021/Decision%20Tree%20Introduction%20with%20example_15.jpg "由QuickLaTeX.com渲染")
通过加权并求和每个基尼系数:
计算变量B的基尼系数:
值> = 3:12
属性B> = 3且类别=正:
属性B> = 5且类=否:
基尼(5,7)= 1 –![\left [ \left ( \frac{8}{12} \right )^{2} + \left ( \frac{4}{12} \right )^{2}\right ] = 0.4460](https://mangdo-1254073825.cos.ap-chengdu.myqcloud.com//front_eng_imgs/geeksforgeeks2021/Decision%20Tree%20Introduction%20with%20example_19.jpg "由QuickLaTeX.com渲染")
值<3:4
属性A <3&class =正:
属性A <3&class =否:
基尼(3,1)= 1 –![\left [ \left ( \frac{0}{4} \right )^{2} + \left ( \frac{4}{4} \right )^{2}\right ] = 1](https://mangdo-1254073825.cos.ap-chengdu.myqcloud.com//front_eng_imgs/geeksforgeeks2021/Decision%20Tree%20Introduction%20with%20example_22.jpg "由QuickLaTeX.com渲染")
通过加权并求和每个基尼系数:
使用相同的方法,我们可以计算C和D属性的基尼系数。
Positive Negative For A|>= 5.0 5 7 |<5 3 1 Ginin Index of A = 0.45825Positive Negative For B|>= 3.0 8 4 |< 3.0 0 4 Gini Index of B= 0.3345Positive Negative For C|>= 4.2 0 6 |< 4.2 8 2 Gini Index of C= 0.2Positive Negative For D|>= 1.4 0 5 |< 1.4 8 3 Gini Index of D= 0.273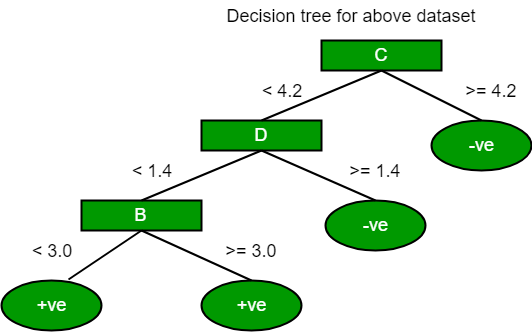
决策树算法最著名的类型是:
1.迭代二分法器3(ID3):此算法使用信息增益来确定要使用哪个属性对数据的当前子集进行分类。对于树的每个级别,递归地为剩余数据计算信息增益。
2. C4.5:此算法是ID3算法的后继算法。该算法使用信息增益或增益比来确定分类属性。它是ID3算法的直接改进,因为它可以处理连续的和缺失的属性值。
3.分类和回归树(CART):这是一种动态学习算法,可以根据因变量生成回归树和分类树。
参考: dataaspirant