先决条件:决策树,DecisionTreeClassifier,sklearn,numpy,pandas
决策树是最强大和最受欢迎的算法之一。决策树算法属于监督学习算法的范畴。它既适用于连续变量,也适用于分类输出变量。
在本文中,我们将在UCI上显示的天平秤重量和距离数据库上实现决策树算法。
数据集说明:
Title : Balance Scale Weight & Distance Database
Number of Instances: 625 (49 balanced, 288 left, 288 right)
Number of Attributes: 4 (numeric) + class name = 5
Attribute Information:
Class Name (Target variable): 3L [balance scale tip to the left]B [balance scale be balanced]R [balance scale tip to the right]Left-Weight: 5 (1, 2, 3, 4, 5)Left-Distance: 5 (1, 2, 3, 4, 5)Right-Weight: 5 (1, 2, 3, 4, 5)Right-Distance: 5 (1, 2, 3, 4, 5)
Missing Attribute Values: None
Class Distribution:46.08 percent are L07.84 percent are B46.08 percent are R
You can find more details of the dataset here.使用的Python软件包:
- sklearn:
- 在Python,sklearn是一个机器学习包,其中包含许多ML算法。
- 在这里,我们使用其一些模块,例如train_test_split,DecisionTreeClassifier和precision_score。
- NumPy:
- 它是一个数字Python模块,提供快速的数学函数进行计算。
- 它用于读取numpy数组中的数据并用于操作目的。
- 熊猫:
- 用于读取和写入不同的文件。
- 使用数据框可以轻松完成数据操作。
软件包的安装:
在Python,sklearn是一个软件包,其中包含实现机器学习算法所需的所有软件包。您可以按照以下命令安装sklearn软件包。
使用pip:
pip install -U scikit-learn使用上述命令之前,请确保已安装scipy和numpy软件包。
如果您没有点子。您可以使用安装
python get-pip.py使用conda:
conda install scikit-learn我们在使用决策树时所做的假设:
- 在开始时,我们将整个培训集作为基础。
- 对于信息获取,属性被认为是分类的;对于基尼系数,属性被认为是连续的。
- 根据属性值,记录是递归分布的。
- 我们使用统计方法对作为根或内部节点的属性进行排序。
伪代码:
- 找到最佳属性并将其放在树的根节点上。
- 现在,将数据集的训练集拆分为子集。在制作子集时,请确保训练数据集的每个子集应具有相同的属性值。
- 通过在每个子集上重复1和2,找到所有分支中的叶节点。
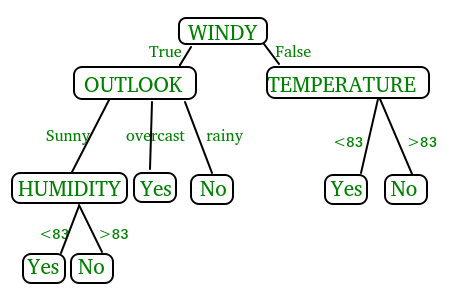
在实施决策树时,我们将经历以下两个阶段:
- 建筑阶段
- 预处理数据集。
- 使用Python sklearn包从训练中分离数据集并进行测试。
- 训练分类器。
- 运作阶段
- 作出预测。
- 计算精度。
资料汇入:
- 为了导入和处理数据,我们使用Python提供的pandas包。
- 在这里,我们使用的URL直接从UCI站点获取数据集,而无需下载数据集。当您尝试在系统上运行此代码时,请确保系统应具有活动的Internet连接。
- 由于数据集以“,”分隔,因此我们必须将sep参数的值传递为“,”。
- 另一件事是要注意的是,数据集不包含标题,因此我们将Header参数的值传递为none。如果我们不传递header参数,那么它将把数据集的第一行作为header。
数据切片:
- 在训练模型之前,我们必须将数据集分为训练和测试数据集。
- 为了分割数据集进行训练和测试,我们使用了sklearn模块train_test_split
- 首先,我们必须将目标变量与数据集中的属性分开。
X = balance_data.values[:, 1:5] Y = balance_data.values[:,0] - 上面是分隔数据集的代码行。变量X包含属性,而变量Y包含数据集的目标变量。
- 下一步是拆分数据集以进行培训和测试。
X_train, X_test, y_train, y_test = train_test_split( X, Y, test_size = 0.3, random_state = 100) - 上面的线分割了数据集以进行训练和测试。由于我们在训练和测试之间以70:30的比例拆分数据集,因此我们将test_size参数的值传递为0.3。
- random_state变量是用于随机采样的伪随机数生成器状态。
代码中使用的术语:
这两种方法的基尼系数和信息增益均用于从数据集的n个属性中选择将哪个属性放置在根节点或内部节点上。
基尼指数
- 基尼系数(Gini Index)是一种度量标准,用于衡量随机选择的元素被错误识别的频率。
- 这意味着应使用具有较低基尼系数的属性。
- Sklearn支持基尼系数的“基尼”标准,默认情况下,它采用“基尼”值。
熵

- 熵是对随机变量不确定性的度量,它表征了任意示例集合的不纯性。熵越高,信息内容越多。
信息增益

- 当我们使用决策树中的节点将训练实例划分为较小的子集时,熵通常会发生变化。信息增益是熵变化的量度。
- Sklearn支持信息增益的“熵”标准,如果要在sklearn中使用信息增益方法,则必须明确提及它。
准确度得分
- 准确性分数用于计算训练的分类器的准确性。
混淆矩阵
- 混淆矩阵用于了解测试数据集上经过训练的分类器行为或验证数据集。
以下是决策树的Python代码。
# Run this program on your local python # interpreter, provided you have installed # the required libraries. # Importing the required packages import numpy as np import pandas as pd from sklearn.metrics import confusion_matrix from sklearn.cross_validation import train_test_split from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score from sklearn.metrics import classification_report # Function importing Dataset def importdata(): balance_data = pd.read_csv( 'https://archive.ics.uci.edu/ml/machine-learning-'+ 'databases/balance-scale/balance-scale.data', sep= ',', header = None) # Printing the dataswet shape print ("Dataset Length: ", len(balance_data)) print ("Dataset Shape: ", balance_data.shape) # Printing the dataset obseravtions print ("Dataset: ",balance_data.head()) return balance_data # Function to split the dataset def splitdataset(balance_data): # Separating the target variable X = balance_data.values[:, 1:5] Y = balance_data.values[:, 0] # Splitting the dataset into train and test X_train, X_test, y_train, y_test = train_test_split( X, Y, test_size = 0.3, random_state = 100) return X, Y, X_train, X_test, y_train, y_test # Function to perform training with giniIndex. def train_using_gini(X_train, X_test, y_train): # Creating the classifier object clf_gini = DecisionTreeClassifier(criterion = "gini", random_state = 100,max_depth=3, min_samples_leaf=5) # Performing training clf_gini.fit(X_train, y_train) return clf_gini # Function to perform training with entropy. def tarin_using_entropy(X_train, X_test, y_train): # Decision tree with entropy clf_entropy = DecisionTreeClassifier( criterion = "entropy", random_state = 100, max_depth = 3, min_samples_leaf = 5) # Performing training clf_entropy.fit(X_train, y_train) return clf_entropy # Function to make predictions def prediction(X_test, clf_object): # Predicton on test with giniIndex y_pred = clf_object.predict(X_test) print("Predicted values:") print(y_pred) return y_pred # Function to calculate accuracy def cal_accuracy(y_test, y_pred): print("Confusion Matrix: ", confusion_matrix(y_test, y_pred)) print ("Accuracy : ", accuracy_score(y_test,y_pred)*100) print("Report : ", classification_report(y_test, y_pred)) # Driver code def main(): # Building Phase data = importdata() X, Y, X_train, X_test, y_train, y_test = splitdataset(data) clf_gini = train_using_gini(X_train, X_test, y_train) clf_entropy = tarin_using_entropy(X_train, X_test, y_train) # Operational Phase print("Results Using Gini Index:") # Prediction using gini y_pred_gini = prediction(X_test, clf_gini) cal_accuracy(y_test, y_pred_gini) print("Results Using Entropy:") # Prediction using entropy y_pred_entropy = prediction(X_test, clf_entropy) cal_accuracy(y_test, y_pred_entropy) # Calling main function if __name__=="__main__": main()Data Infomation: Dataset Length: 625 Dataset Shape: (625, 5) Dataset: 0 1 2 3 4 0 B 1 1 1 1 1 R 1 1 1 2 2 R 1 1 1 3 3 R 1 1 1 4 4 R 1 1 1 5 Results Using Gini Index: Predicted values: ['R' 'L' 'R' 'R' 'R' 'L' 'R' 'L' 'L' 'L' 'R' 'L' 'L' 'L' 'R' 'L' 'R' 'L' 'L' 'R' 'L' 'R' 'L' 'L' 'R' 'L' 'L' 'L' 'R' 'L' 'L' 'L' 'R' 'L' 'L' 'L' 'L' 'R' 'L' 'L' 'R' 'L' 'R' 'L' 'R' 'R' 'L' 'L' 'R' 'L' 'R' 'R' 'L' 'R' 'R' 'L' 'R' 'R' 'L' 'L' 'R' 'R' 'L' 'L' 'L' 'L' 'L' 'R' 'R' 'L' 'L' 'R' 'R' 'L' 'R' 'L' 'R' 'R' 'R' 'L' 'R' 'L' 'L' 'L' 'L' 'R' 'R' 'L' 'R' 'L' 'R' 'R' 'L' 'L' 'L' 'R' 'R' 'L' 'L' 'L' 'R' 'L' 'R' 'R' 'R' 'R' 'R' 'R' 'R' 'L' 'R' 'L' 'R' 'R' 'L' 'R' 'R' 'R' 'R' 'R' 'L' 'R' 'L' 'L' 'L' 'L' 'L' 'L' 'L' 'R' 'R' 'R' 'R' 'L' 'R' 'R' 'R' 'L' 'L' 'R' 'L' 'R' 'L' 'R' 'L' 'L' 'R' 'L' 'L' 'R' 'L' 'R' 'L' 'R' 'R' 'R' 'L' 'R' 'R' 'R' 'R' 'R' 'L' 'L' 'R' 'R' 'R' 'R' 'L' 'R' 'R' 'R' 'L' 'R' 'L' 'L' 'L' 'L' 'R' 'R' 'L' 'R' 'R' 'L' 'L' 'R' 'R' 'R'] Confusion Matrix: [[ 0 6 7] [ 0 67 18] [ 0 19 71]] Accuracy : 73.4042553191 Report : precision recall f1-score support B 0.00 0.00 0.00 13 L 0.73 0.79 0.76 85 R 0.74 0.79 0.76 90 avg/total 0.68 0.73 0.71 188 Results Using Entropy: Predicted values: ['R' 'L' 'R' 'L' 'R' 'L' 'R' 'L' 'R' 'R' 'R' 'R' 'L' 'L' 'R' 'L' 'R' 'L' 'L' 'R' 'L' 'R' 'L' 'L' 'R' 'L' 'R' 'L' 'R' 'L' 'R' 'L' 'R' 'L' 'L' 'L' 'L' 'L' 'R' 'L' 'R' 'L' 'R' 'L' 'R' 'R' 'L' 'L' 'R' 'L' 'L' 'R' 'L' 'L' 'R' 'L' 'R' 'R' 'L' 'R' 'R' 'R' 'L' 'L' 'R' 'L' 'L' 'R' 'L' 'L' 'L' 'R' 'R' 'L' 'R' 'L' 'R' 'R' 'R' 'L' 'R' 'L' 'L' 'L' 'L' 'R' 'R' 'L' 'R' 'L' 'R' 'R' 'L' 'L' 'L' 'R' 'R' 'L' 'L' 'L' 'R' 'L' 'L' 'R' 'R' 'R' 'R' 'R' 'R' 'L' 'R' 'L' 'R' 'R' 'L' 'R' 'R' 'L' 'R' 'R' 'L' 'R' 'R' 'R' 'L' 'L' 'L' 'L' 'L' 'R' 'R' 'R' 'R' 'L' 'R' 'R' 'R' 'L' 'L' 'R' 'L' 'R' 'L' 'R' 'L' 'R' 'R' 'L' 'L' 'R' 'L' 'R' 'R' 'R' 'R' 'R' 'L' 'R' 'R' 'R' 'R' 'R' 'R' 'L' 'R' 'L' 'R' 'R' 'L' 'R' 'L' 'R' 'L' 'R' 'L' 'L' 'L' 'L' 'L' 'R' 'R' 'R' 'L' 'L' 'L' 'R' 'R' 'R'] Confusion Matrix: [[ 0 6 7] [ 0 63 22] [ 0 20 70]] Accuracy : 70.7446808511 Report : precision recall f1-score support B 0.00 0.00 0.00 13 L 0.71 0.74 0.72 85 R 0.71 0.78 0.74 90 avg / total 0.66 0.71 0.68 188