R 编程中的决策树
决策树是有用的监督机器学习算法,能够执行回归和分类任务。它以节点和分支为特征,其中每个属性的测试在节点上表示,该过程的结果在分支上表示,类标签在叶节点上表示。因此,它使用基于用于计算其可能结果的各种决策的树状模型。这些类型的基于树的算法是最广泛使用的算法之一,因为这些算法易于解释和使用。除此之外,该算法开发的预测模型被发现具有良好的稳定性和良好的准确性,因此非常受欢迎
决策树的类型
- 决策树桩:用于生成仅具有单个拆分的决策树,因此也称为单级决策树。由于其简单性,它在大多数情况下以低预测性能而闻名。
- M5:以其精确的分类准确性和对增强决策树和噪声过多的小数据集的良好工作能力而闻名。
- ID3(Iterative Dichroatiser 3):核心和广泛使用的决策树算法之一,通过给定数据集使用自上而下的贪婪搜索方法,并选择最佳属性对给定数据集进行分类
- C4.5:也称为统计分类器,这种类型的决策树源自其父 ID3。这会根据一堆预测变量生成决策。
- C5.0:作为C4.5的继承者,它大致有两种模型,即基本树模型和基于规则的模型,其节点只能预测分类目标。
- CHAID:扩展为卡方自动交互检测器,该算法主要研究合并变量以通过构建预测模型来证明因变量的结果
- MARS:扩展为多元自适应回归样条,该算法创建了一系列分段线性模型,用于模拟变量之间的不规则性和相互作用,它们以更高效地处理数值数据的能力而闻名。
- 条件推理树:这是一种决策树,它使用条件推理框架递归地分离响应变量,它以其灵活性和强大的基础而闻名。
- CART:扩展为分类和回归树,如果目标变量的值是连续的,则预测它们的值,否则如果它们是分类的,则识别必要的类。
可以看出,决策树的类型很多,但根据目标变量的类型,它们分为两大类,它们是:
- 分类变量决策树:这是指目标变量具有有限值并属于特定组的决策树。
- 连续变量决策树:这是指其目标变量可以从各种数据类型中获取值的决策树。
R 编程语言中的决策树
让我们考虑一下医疗公司想要预测一个人如果接触到病毒是否会死亡的场景。决定这一结果的重要因素是他的免疫系统强度,但该公司没有此信息。由于这是一个重要的变量,因此可以构建决策树来根据人的睡眠周期、皮质醇水平、补充剂摄入量、食物摄入的营养物质等因素来预测免疫强度,这些因素都是连续变量。
R中决策树的工作
- 分区:指将数据集拆分为子集的过程。进行战略拆分的决定极大地影响了树的准确性。树使用许多算法将节点拆分为子节点,这导致节点相对于目标变量的清晰度总体提高。为此使用了各种算法,例如卡方和基尼指数,并选择了效率最高的算法。
- 修剪:这是指将分支节点变成叶子节点的过程,从而导致树的分支缩短。这个想法背后的本质是通过更简单的树来避免过度拟合,因为大多数复杂的分类树可能很好地拟合训练数据,但在分类新值方面做得很差。
- 树的选择:此过程的主要目标是选择适合数据的最小树,原因将在修剪部分讨论。
在 R 中选择树时要考虑的重要因素
- 熵:
主要用于确定给定样品的均匀度。如果样本是完全均匀的,则熵为 0,如果是均匀划分的,则熵为 1。熵越高,从该信息中得出结论就越困难。 - 信息增益:
统计属性,用于衡量基于目标分类的训练示例的分离程度。构建决策树的主要思想是找到一个返回最小熵和最高信息增益的属性。它基本上是总熵减少的一种度量,它是通过根据给定的属性值计算数据集拆分前的熵与拆分后的平均熵之间的总差异来计算的。
R – 决策树示例
现在让我们借助一个示例来研究这个概念,在这种情况下,它是使用最广泛的“阅读技能”数据集,通过可视化决策树并检查其准确性。
导入所需的库并加载数据集 readingSkills 并执行 head(readingSkills)
R
library(datasets)
library(caTools)
library(party)
library(dplyr)
library(magrittr)
data("readingSkills")
head(readingSkills)R
sample_data = sample.split(readingSkills, SplitRatio = 0.8)
train_data <- subset(readingSkills, sample_data == TRUE)
test_data <- subset(readingSkills, sample_data == FALSE)R
model<- ctree(nativeSpeaker ~ ., train_data)
plot(model)R
# testing the people who are native speakers
# and those who are not
predict_model<-predict(ctree_, test_data)
# creates a table to count how many are classified
# as native speakers and how many are not
m_at <- table(test_data$nativeSpeaker, predict_model)
m_atR
ac_Test < - sum(diag(table_mat)) / sum(table_mat)
print(paste('Accuracy for test is found to be', ac_Test))输出:
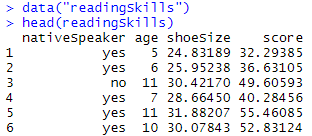
如您所见,有 4 列 nativeSpeaker、age、shoeSize 和 score。因此,基本上我们将使用其他标准来确定一个人是否是母语人士,并查看在此过程中开发的决策树模型的准确性。
将数据集拆分为 4:1 的比例用于训练和测试数据
R
sample_data = sample.split(readingSkills, SplitRatio = 0.8)
train_data <- subset(readingSkills, sample_data == TRUE)
test_data <- subset(readingSkills, sample_data == FALSE)
将数据分成训练集和测试集是评估数据挖掘模型的重要部分。因此,它分为训练集和测试集。使用训练集处理模型后,您可以通过针对测试集进行预测来测试模型。因为测试集中的数据已经包含您要预测的属性的已知值,所以很容易确定模型的猜测是否正确。
使用 ctree 创建决策树模型并绘制模型
R
model<- ctree(nativeSpeaker ~ ., train_data)
plot(model)
在 R 中创建决策树的基本语法是:
ctree(formula, data)其中,公式描述了预测变量和响应变量,数据是使用的数据集。在这种情况下,nativeSpeaker 是响应变量,其他预测变量由 表示,因此当我们绘制模型时,我们得到以下输出。
输出:
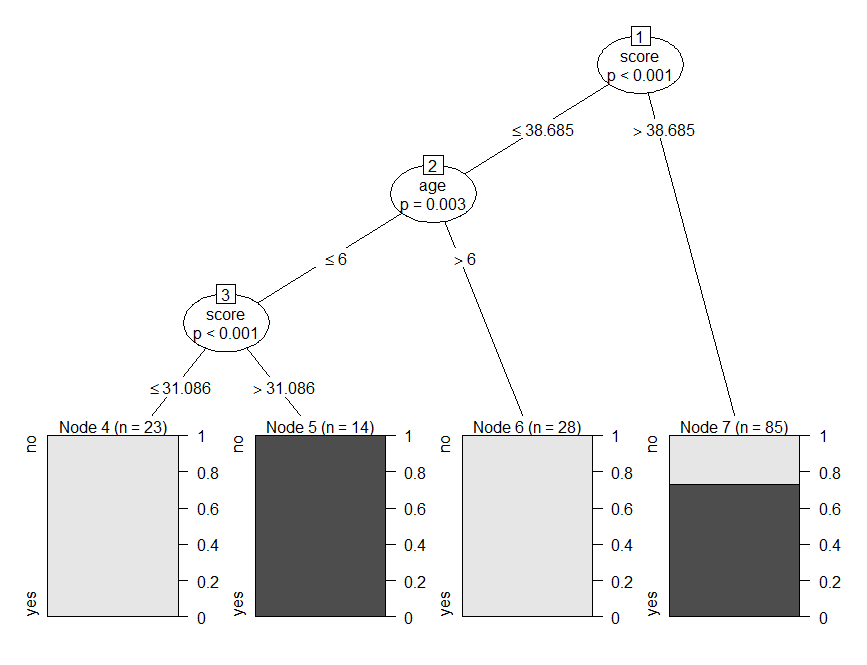
从树上可以看出,分数小于等于31.08且年龄小于等于6的人不是母语者,同样标准下分数大于31.086的人,成为母语人士。
做出预测
R
# testing the people who are native speakers
# and those who are not
predict_model<-predict(ctree_, test_data)
# creates a table to count how many are classified
# as native speakers and how many are not
m_at <- table(test_data$nativeSpeaker, predict_model)
m_at
输出
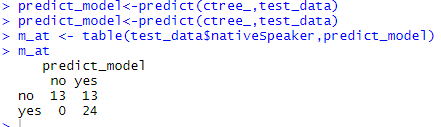
该模型正确地预测了 13 个人为非母语人士,但将另外 13 人分类为非母语人士,并且通过类比,该模型错误地将所有乘客都误分类为母语人士,而实际上他们并非如此。
确定所开发模型的准确性
R
ac_Test < - sum(diag(table_mat)) / sum(table_mat)
print(paste('Accuracy for test is found to be', ac_Test))
输出:

这里计算了来自混淆矩阵的准确度测试,发现为 0.74。因此,发现该模型的预测准确率为 74%。
推理
因此,决策树是非常有用的算法,因为它们不仅用于根据预期值选择备选方案,还用于优先级分类和预测。我们有责任确定在适当的应用程序中使用此类模型的准确性。
决策树的优势
- 易于理解和解释。
- 不需要数据规范化
- 不利于数据扩展的需要
- 与其他主要算法相比,预处理阶段需要更少的工作,因此在某种程度上优化了给定的问题
决策树的缺点
- 需要更长的时间来训练模型
- 它具有相当高的复杂性并且需要更多时间来处理数据
- 当用户输入参数的减少非常小时,它会导致树的终止
- 计算有时会变得非常复杂