让我们考虑一下,我们正在设计一个机器学习模型。如果模型以适当的方式概括了来自问题域的任何新输入数据,则该模型被认为是一种很好的机器学习模型。这有助于我们对数据模型从未见过的未来数据做出预测。
现在,假设我们想检查一下我们的机器学习模型对新数据的学习和推广情况。为此,我们有过度拟合和不足拟合的原因,这主要是造成机器学习算法性能不佳的原因。
在进一步潜水之前,让我们了解两个重要术语:
偏差–模型使函数更易于学习的假设。
方差–如果您在训练数据上训练数据并获得非常低的误差,则在更改数据后再训练先前的相同模型时,您会遇到高误差,这就是方差。
拟合不足:
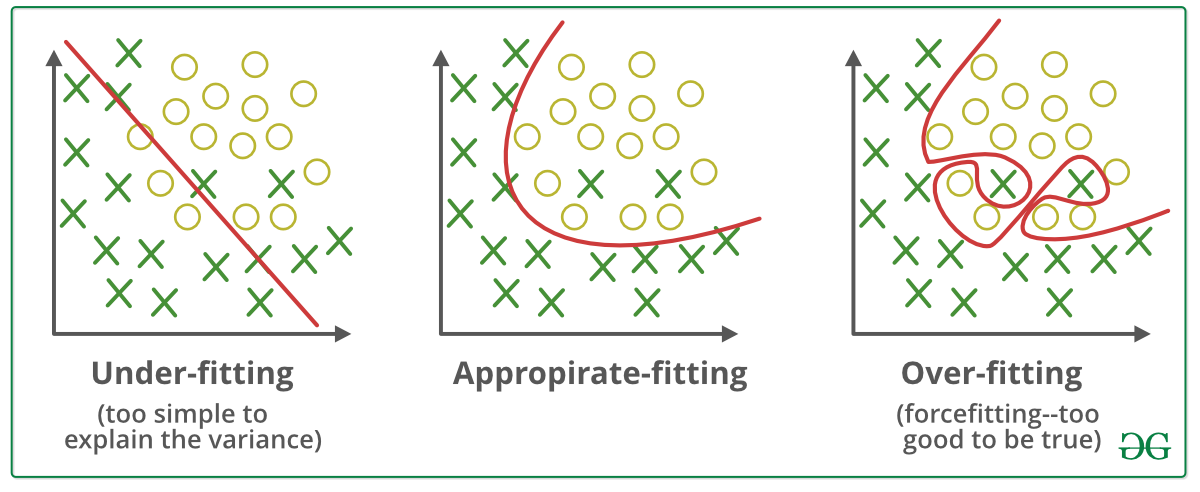
当统计模型或机器学习算法无法捕获数据的潜在趋势时,则称该模型不合适。 (这就像试图穿上小号的裤子一样!)穿着不足会破坏我们的机器学习模型的准确性。它的出现仅意味着我们的模型或算法不足以很好地拟合数据。当我们使用较少的数据来构建准确的模型时,以及尝试使用非线性数据来构建线性模型时,通常会发生这种情况。在这种情况下,机器学习模型的规则过于简单和灵活,无法应用于此类最小数据,因此该模型可能会做出很多错误的预测。可以通过使用更多数据来避免拟合不足,还可以通过特征选择来减少特征。
简而言之,欠拟合–高偏差和低方差
减少不合身的技巧:
1.增加模型复杂度
2.增加功能数量,执行功能工程
3.去除数据中的噪音。
4.增加时期数或增加训练时间以获得更好的效果。
过度拟合:
当我们使用大量数据训练该统计模型时,该模型被认为是过拟合的(就像将自己拟合为超大号裤子一样!) 。当一个模型接受了如此多的数据训练后,它便开始从噪声和我们数据集中不准确的数据条目中学习。然后,由于过多的细节和噪音,该模型无法正确地对数据进行分类。过度拟合的原因是非参数和非线性方法,因为这些类型的机器学习算法在基于数据集构建模型时具有更大的自由度,因此它们实际上可以构建不切实际的模型。避免过度拟合的解决方案是,如果我们具有线性数据,则使用线性算法;如果使用决策树,则使用诸如最大深度之类的参数。
简而言之,过度拟合–高方差和低偏差
例子:

减少过度拟合的技术:
1.增加训练数据。
2.降低模型复杂度。
3.在训练阶段中尽早停止训练(一旦损失开始增加,就应注意训练期间的损失)。
4.岭正则化和套索正则化
5.使用辍学神经网络来解决过度拟合问题。
非常适合统计模型:
理想情况下,模型预测误差为0的情况被认为非常适合数据。这种情况可以在过拟合和欠拟合之间实现。为了理解它,我们必须随着时间的流逝来观察我们模型的性能,而它是从训练数据集中学习的。
随着时间的流逝,我们的模型将继续学习,因此该模型在训练和测试数据上的误差将不断减少。如果学习时间过长,由于存在噪音和有用的细节较少,该模型将更容易过度拟合。因此,我们模型的性能将下降。为了获得良好的拟合度,我们将在误差开始增加之前的某个位置停止。在这一点上,该模型在训练数据集以及我们看不见的测试数据集方面具有良好的技能。
参考:
lasseschultebraucks.com/overfitting-underfitting-ml/
chunml.github.io/ChunML.github.io/tutorial/Underfit-Overfit/