让我们考虑一下我们正在设计一个机器学习模型。如果一个模型以适当的方式概括了来自问题域的任何新输入数据,则该模型被认为是一个好的机器学习模型。这有助于我们对未来数据进行预测,该数据模型从未见过。
现在,假设我们想检查我们的机器学习模型对新数据的学习和泛化能力。为此,我们有过拟合和欠拟合,这是机器学习算法性能不佳的主要原因。
在进一步深入之前,让我们了解两个重要术语:
偏差 – 模型做出的假设,使函数更容易学习。
方差 – 如果您在训练数据上训练数据并获得非常低的误差,则在更改数据然后训练相同的先前模型时,您会遇到高误差,这就是方差。
欠拟合:
当统计模型或机器学习算法无法捕捉数据的潜在趋势时,就会被称为欠拟合。 (这就像试图让尺寸过小的裤子合身!)欠拟合会破坏我们机器学习模型的准确性。它的出现仅仅意味着我们的模型或算法不能很好地拟合数据。当我们拥有较少的数据来构建准确的模型以及尝试使用非线性数据构建线性模型时,通常会发生这种情况。在这种情况下,机器学习模型的规则过于简单和灵活,无法应用于如此少的数据,因此模型可能会做出很多错误的预测。可以通过使用更多数据并通过特征选择减少特征来避免欠拟合。
简而言之,欠拟合——高偏差和低方差
减少欠拟合的技术:
1. 增加模型复杂度
2.增加特征数量,进行特征工程
3. 从数据中去除噪声。
4.增加epoch数或增加训练时长以获得更好的结果。
过拟合:
当我们用大量数据对其进行训练时,统计模型被称为过度拟合(就像让自己穿上超大号裤子一样!) 。当模型接受如此多的数据训练时,它会开始从我们数据集中的噪声和不准确的数据条目中学习。然后模型没有正确分类数据,因为太多的细节和噪音。过拟合的原因是非参数和非线性方法,因为这些类型的机器学习算法在基于数据集构建模型方面具有更大的自由度,因此它们确实可以构建不切实际的模型。如果我们有线性数据,则避免过度拟合的解决方案是使用线性算法,或者如果我们使用决策树,则使用最大深度等参数。
简而言之,过度拟合——高方差和低偏差
例子:
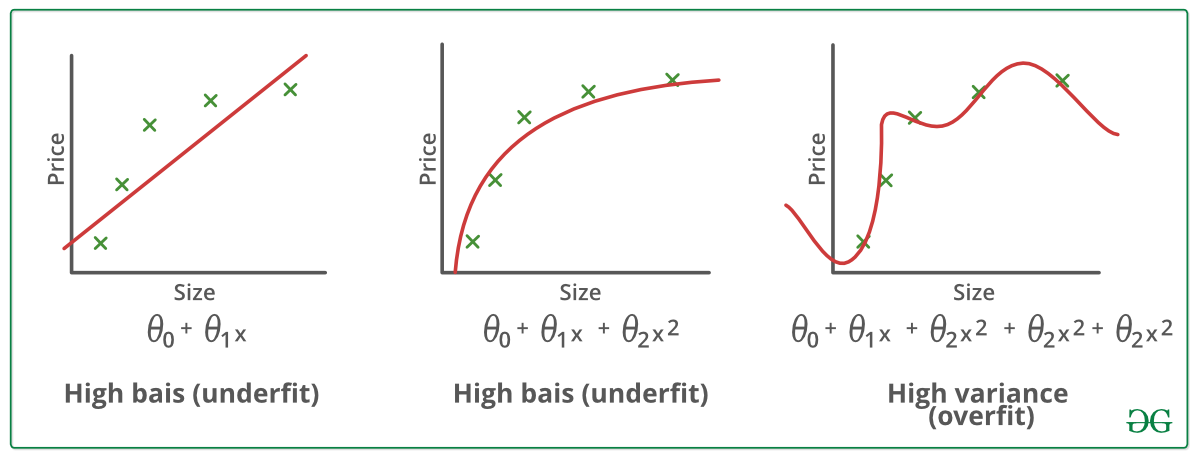

减少过拟合的技术:
1.增加训练数据。
2. 降低模型复杂度。
3. 在训练阶段提前停止(当损失开始增加时,注意训练期间的损失,停止训练)。
4.岭正则化和套索正则化
5. 对神经网络使用 dropout 来解决过拟合问题。
很好地拟合统计模型:
理想情况下,模型以 0 错误进行预测的情况被称为对数据有很好的拟合。这种情况可以在过度拟合和欠拟合之间的某个点上实现。为了理解它,我们将不得不随着时间的推移查看我们模型的性能,同时它正在从训练数据集中学习。
随着时间的推移,我们的模型会不断学习,因此模型在训练和测试数据上的误差会不断减少。如果学习时间过长,模型将更容易由于噪声和较少有用细节的存在而过度拟合。因此,我们模型的性能会下降。为了获得良好的拟合,我们将在误差开始增加之前的某个点处停止。在这一点上,据说该模型在训练数据集以及我们未见过的测试数据集方面具有良好的技能。
参考:
lasseschultebraucks.com/overfitting-underfitting-ml/
chunml.github.io/ChunML.github.io/tutorial/Underfit-Overfit/