- 机器学习中的欠拟合和过拟合(1)
- 机器学习中的欠拟合和过拟合
- python中的拟合函数(1)
- python代码示例中的拟合函数
- 对象拟合 css (1)
- 对象拟合 css 代码示例
- 拟合函数 tensorflow - 任何代码示例
- 机器学习中的不足和过度拟合(1)
- 机器学习中的不足和过度拟合
- 在网格 css 中拟合图像(1)
- Python - 高斯拟合(1)
- Python - 高斯拟合
- 在网格 css 代码示例中拟合图像
- Tailwind CSS 对象拟合
- Tailwind CSS 对象拟合(1)
- statsmodels 拟合值 - Python (1)
- statsmodels 拟合值 - Python 代码示例
- plt 最佳拟合线 - Python (1)
- plt 最佳拟合线 - Python 代码示例
- 对数刻度拟合 python (1)
- 测试过度欠拟合 (1)
- 对数刻度拟合 python 代码示例
- 回归分析和使用 C++ 的最佳拟合线
- 测试过度欠拟合 - 任何代码示例
- 语义 UI 图标拟合变体
- 语义 UI 图标拟合变体(1)
- 如何将 Gamma 分布拟合到 R 中的数据集(1)
- 如何将 Gamma 分布拟合到 R 中的数据集
- 统计-拟合优度(1)
📅 最后修改于: 2020-09-29 04:45:09 🧑 作者: Mango
机器学习中的过度拟合和不足拟合
过度拟合和欠拟合是机器学习中发生的两个主要问题,它们降低了机器学习模型的性能。
每个机器学习模型的主要目标是很好地概括。在这里,泛化定义了ML模型通过调整给定的未知输入集来提供合适输出的能力。这意味着在对数据集进行训练之后,它可以产生可靠且准确的输出。因此,欠拟合和过拟合是需要检查模型性能的两个术语以及模型是否泛化得很好。
在了解过拟合和欠拟合之前,让我们了解一些基本术语,这些术语将有助于更好地理解此主题:
- 信号:它是指数据的真实基础模式,可帮助机器学习模型从数据中学习。
- 噪声:噪声是不必要且无关的数据,会降低模型的性能。
- 偏差:偏差是由于过度简化了机器学习算法而引入模型的预测误差。或者是预测值与实际值之差。
- 差异:如果机器学习模型在训练数据集上表现良好,但在测试数据集上表现不佳,那么就会发生差异。
过度拟合
当我们的机器学习模型试图覆盖给定数据集中存在的所有数据点或超过所需数据点时,就会发生过度拟合。因此,模型开始缓存噪声和数据集中存在的不准确值,所有这些因素都会降低模型的效率和准确性。过拟合模型具有低偏差和高方差。
我们为模型提供训练的次数增加了发生过度拟合的机会。这意味着我们训练模型的次数越多,发生过拟合模型的机会就越多。
过度拟合是监督学习中发生的主要问题。
示例:可以通过下面的线性回归输出图来了解过拟合的概念:
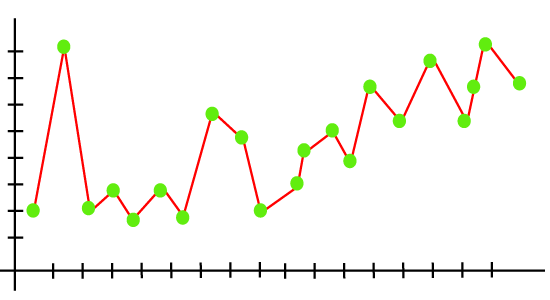
从上图可以看出,该模型试图覆盖散点图中存在的所有数据点。它可能看起来很有效,但实际上并非如此。因为回归模型的目标是找到最佳拟合线,但是这里我们没有任何最佳拟合,因此,它将生成预测误差。
如何避免模型过拟合
过拟合和欠拟合都会导致机器学习模型的性能下降。但是主要原因是过度拟合,因此有一些方法可以减少模型中过度拟合的发生。
- 交叉验证
- 训练更多数据
- 删除功能
- 尽早停止训练
- 正则化
- 组装
不合身
当我们的机器学习模型无法捕获数据的潜在趋势时,就会发生拟合不足。为避免模型过度拟合,可以在早期停止提供训练数据,因此模型可能无法从训练数据中学到足够的知识。结果,它可能无法找到数据中主导趋势的最佳拟合。
在欠拟合的情况下,该模型无法从训练数据中学到足够的知识,因此会降低准确性并产生不可靠的预测。
拟合不足的模型具有高偏差和低方差。
示例:我们可以使用以下线性回归模型的输出来了解拟合不足:
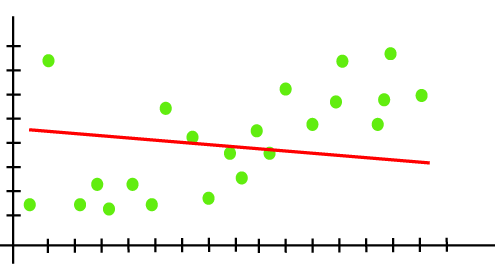
从上图可以看出,该模型无法捕获图中存在的数据点。
如何避免拟合不足:
- 通过增加模型的训练时间。
- 通过增加功能数量。
贴合度
“拟合优度”一词取自统计数据,并且采用机器学习模型的目标来获得拟合优度。在统计建模中,它定义结果或预测值与数据集的真实值的接近程度。
拟合良好的模型介于欠拟合模型和过度拟合模型之间,理想情况下,它的预测误差为0,但在实践中很难实现。
当我们训练模型一段时间时,训练数据中的错误会减少,而测试数据也会发生同样的情况。但是,如果我们长时间训练模型,则模型的性能可能会由于过度拟合而降低,因为模型还会学习数据集中存在的噪声。测试数据集中的错误开始增加,因此,恰好在错误出现之前,该点才是好点,我们可以在此处停止以获得良好的模型。
还有另外两种方法可以使我们对模型有所了解,它们是用于估计模型准确性和验证数据集的重采样方法。