假设有一组数据点需要根据它们的相似性分为几个部分或群集。在机器学习中,这称为
有几种可用于聚类的方法,例如:
- K均值聚类
- 层次聚类
- 高斯混合模型
等等。
在本文中,将讨论高斯混合模型。
正态分布或高斯分布
在现实生活中,许多数据集都可以通过高斯分布(单变量或多变量)建模。因此,假设聚类来自不同的高斯分布是非常自然和直观的。换句话说,尝试将数据集建模为几种高斯分布的混合。这是该模型的核心思想。
在一个维度上,高斯分布的概率密度函数由下式给出:
![]()
在哪里![]() 和
和![]() 分别是分布的均值和方差。
分别是分布的均值和方差。
对于多元(让我们说d变量)高斯分布,概率密度函数由下式给出:
![]()
这里![]() 是广告维矢量,表示分布的均值,
是广告维矢量,表示分布的均值, ![]() 是d X d协方差矩阵。
是d X d协方差矩阵。
高斯混合模型
假设有K个群集(为简单起见,这里假定群集的数目是已知的,它是K)。所以![]() 和
和![]() 还为每个k估计。如果只有一个分布,则可以通过最大似然法进行估计。但是由于有K个这样的簇,并且概率密度定义为所有这些K分布的密度的线性函数,即
还为每个k估计。如果只有一个分布,则可以通过最大似然法进行估计。但是由于有K个这样的簇,并且概率密度定义为所有这些K分布的密度的线性函数,即
![]()
在哪里![]() 是第k个分布的混合系数。
是第k个分布的混合系数。
为了通过最大对数似然法估计参数,请计算p(X | ![]() ,
, ![]() ,
, ![]() )。
)。

现在定义一个随机变量![]() 这样
这样![]() = p(k | X)。
= p(k | X)。
根据贝叶斯定理,

现在,为了使对数似然函数最大,其对数的导数为![]() 关于
关于![]() ,
, ![]() 和
和![]() 应该为零。因此等于
应该为零。因此等于![]() 关于
关于![]() 归零并重新排列条款,
归零并重新排列条款,

同样对![]() 和
和![]() 分别可以获得以下表达式。
分别可以获得以下表达式。
![]()
和![]()
笔记: ![]() 表示第k个聚类中的采样点总数。在这里,假设总共有N个样本,每个包含d个特征的样本都用表示
表示第k个聚类中的采样点总数。在这里,假设总共有N个样本,每个包含d个特征的样本都用表示![]() 。
。
因此可以清楚地看到,不能以封闭形式估计参数。这就是期望最大化算法的优势所在。
期望最大化(EM)算法
期望最大化(EM)算法是一种迭代方法,可在数据不完整或缺少一些数据点或具有一些隐藏变量时为模型参数找到最大似然估计。 EM为丢失的数据点选择一些随机值,并估计一组新的数据。然后,通过填充缺失点,将这些新值递归用于估计更好的第一个数据,直到这些值固定为止。
这是EM算法的两个基本步骤,即E步骤或期望步骤或估计步骤以及M步骤或最大化步骤。
- 估算步骤:
- 初始化
 ,
,  和
和 某些随机值或K表示聚类结果或分层聚类结果。
某些随机值或K表示聚类结果或分层聚类结果。 - 然后对于那些给定的参数值,估计潜在变量的值(即
 )
)
- 初始化
- 最大化步骤:
- 更新参数值(即
 ,
,  和
和 )使用ML方法进行计算。
)使用ML方法进行计算。
- 更新参数值(即
算法:
- 初始化均值
 ,协方差矩阵
,协方差矩阵 和混合系数
和混合系数 通过一些随机值。 (或其他值)
通过一些随机值。 (或其他值) - 计算
 所有k的值。
所有k的值。 - 再次使用当前估计所有参数
 价值观。
价值观。 - 计算对数似然函数。
- 提出一些收敛准则
- 如果对数似然值收敛到某个值(或者所有参数收敛到某个值),则停止,否则返回步骤2 。
例子:
在此示例中,采用IRIS数据集。在Python,有一个GaussianMixture类来实现GMM。
注意:此代码可能无法在在线编译器中运行。请使用离线IDE。
- 从数据集包中加载虹膜数据集。为了简单起见,仅采用前两列(即分别为隔片长度和隔片宽度)。
- 现在绘制数据集。
import numpy as np import pandas as pd import matplotlib.pyplot as plt from pandas import DataFrame from sklearn import datasets from sklearn.mixture import GaussianMixture # load the iris dataset iris = datasets.load_iris() # select first two columns X = iris.data[:, :2] # turn it into a dataframe d = pd.DataFrame(X) # plot the data plt.scatter(d[0], d[1])
- 现在,将数据混合为3个高斯分布。
- 然后进行聚类,即为每个观察值分配一个标签。还找到对数似然函数收敛所需的迭代次数和收敛的对数似然值。
gmm = GaussianMixture(n_components = 3) # Fit the GMM model for the dataset # which expresses the dataset as a # mixture of 3 Gaussian Distribution gmm.fit(d) # Assign a label to each sample labels = gmm.predict(d) d['labels']= labels d0 = d[d['labels']== 0] d1 = d[d['labels']== 1] d2 = d[d['labels']== 2] # plot three clusters in same plot plt.scatter(d0[0], d0[1], c ='r') plt.scatter(d1[0], d1[1], c ='yellow') plt.scatter(d2[0], d2[1], c ='g')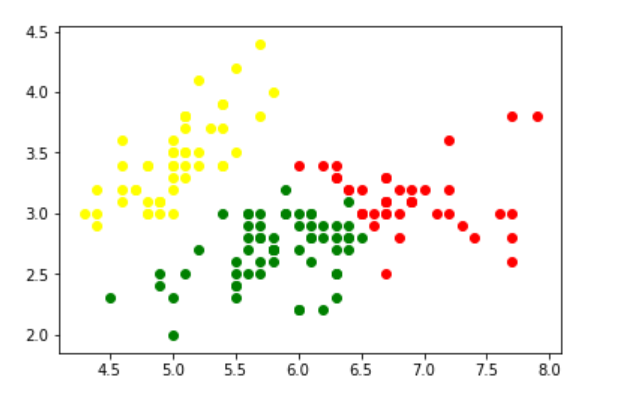
- 打印收敛的对数似然值,然后选择否。模型收敛所需的迭代次数
# print the converged log-likelihood value print(gmm.lower_bound_) # print the number of iterations needed # for the log-likelihood value to converge print(gmm.n_iter_)
- 因此,它需要进行7次迭代才能使对数似然性收敛。如果执行更多的迭代,则无法观察到对数似然值的明显变化。