本文讨论了为信息检索(IR)系统构建反向索引。但是,在现实的IR系统中,我们不仅会遇到单字查询(例如“狗”,“计算机”或“ alex”),还会遇到短语查询(例如“冬天来了”,“纽约” ”或“凯文在哪里”)。要处理此类查询,使用倒排索引是不够的。
为了更好地理解动机,请考虑用户查询“圣玛丽学校”。现在,倒排索引将为我们提供独立包含术语“圣”,“玛丽”和“学校”的文档列表。但是,我们实际需要的是文件,其中“圣玛丽学校”的整个短语都逐字出现。为了成功回答此类查询,我们需要一个文档索引,该文档还应存储术语的位置。
张贴清单
对于倒排索引,过帐列表是该术语出现的文档列表。它通常按文档ID排序,并以链接列表的形式存储。
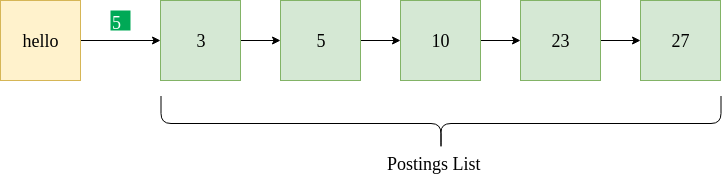
上图显示了术语“ hello”的示例发布列表。它指示“ hello”出现在文档ID为3、5、10、23和27的文档中。它还指定了文档频率5(以绿色突出显示)。给定的是示例Python数据格式,其中包含字典和用于存储发布列表的链接列表。
{"hello" : [5, [3, 5, 10, 23, 27] ] }
在位置索引的情况下,该术语在特定文档中出现的位置也与docID一起存储。
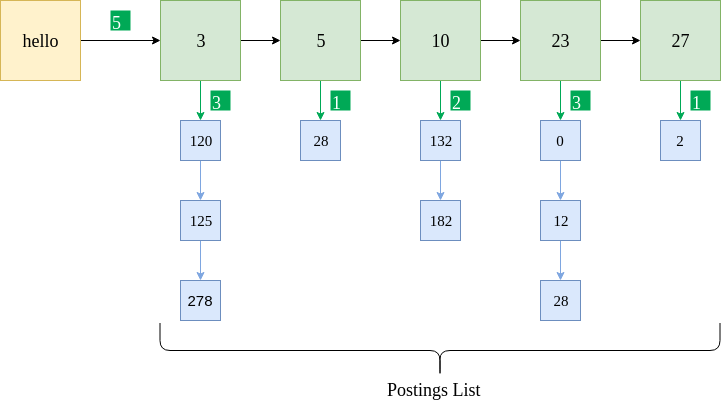
上图显示了为位置索引实施的相同过帐列表。蓝色框表示术语“ hello”在相应文档中的位置。例如,“ hello”出现在文档5中的三个位置:120、125和278。此外,该术语的出现频率也存储在每个文档中。给出的是相同的示例Python数据格式。
{"hello" : [5, [ {3 : [3, [120, 125, 278]]}, {5 : [1, [28] ] }, {10 : [2, [132, 182]]}, {23 : [3, [0, 12, 28]]}, {27 : [1, [2]]} ] }
为了简单起见,也可以在各个文档中省略术语“频率”(如示例代码中所做的那样)。数据格式如下所示。
{"hello" : [5, {3 : [120, 125, 278]}, {5 : [28]}, {10 : [132, 182]}, {23 : [0, 12, 28]}, {27 : [2]} ] }
建立位置索引的步骤
- 提取文档。
- 删除停用词,阻止生成的词。
- 如果字典中已经存在该单词,则添加文档及其出现的相应位置。否则,创建一个新条目。
- 还要更新每个文档的单词频率以及否。出现在其中的文件数量。
代码
为了实现位置索引,我们使用了一个名为“ 20个新闻组”的样本数据集。
# importing libraries
import numpy as np
import os
import nltk
from nltk.stem import PorterStemmer
from nltk.tokenize import TweetTokenizer
from natsort import natsorted
import string
def read_file(filename):
with open(filename, 'r', encoding ="ascii", errors ="surrogateescape") as f:
stuff = f.read()
f.close()
# Remove header and footer.
stuff = remove_header_footer(stuff)
return stuff
def remove_header_footer(final_string):
new_final_string = ""
tokens = final_string.split('\n\n')
# Remove tokens[0] and tokens[-1]
for token in tokens[1:-1]:
new_final_string += token+" "
return new_final_string
def preprocessing(final_string):
# Tokenize.
tokenizer = TweetTokenizer()
token_list = tokenizer.tokenize(final_string)
# Remove punctuations.
table = str.maketrans('', '', '\t')
token_list = [word.translate(table) for word in token_list]
punctuations = (string.punctuation).replace("'", "")
trans_table = str.maketrans('', '', punctuations)
stripped_words = [word.translate(trans_table) for word in token_list]
token_list = [str for str in stripped_words if str]
# Change to lowercase.
token_list =[word.lower() for word in token_list]
return token_list
# In this example, we create the positional index for only 1 folder.
folder_names = ["comp.graphics"]
# Initialize the stemmer.
stemmer = PorterStemmer()
# Initialize the file no.
fileno = 0
# Initialize the dictionary.
pos_index = {}
# Initialize the file mapping (fileno -> file name).
file_map = {}
for folder_name in folder_names:
# Open files.
file_names = natsorted(os.listdir("20_newsgroups/" + folder_name))
# For every file.
for file_name in file_names:
# Read file contents.
stuff = read_file("20_newsgroups/" + folder_name + "/" + file_name)
# This is the list of words in order of the text.
# We need to preserve the order because we require positions.
# 'preprocessing' function does some basic punctuation removal,
# stopword removal etc.
final_token_list = preprocessing(stuff)
# For position and term in the tokens.
for pos, term in enumerate(final_token_list):
# First stem the term.
term = stemmer.stem(term)
# If term already exists in the positional index dictionary.
if term in pos_index:
# Increment total freq by 1.
pos_index[term][0] = pos_index[term][0] + 1
# Check if the term has existed in that DocID before.
if fileno in pos_index[term][1]:
pos_index[term][1][fileno].append(pos)
else:
pos_index[term][1][fileno] = [pos]
# If term does not exist in the positional index dictionary
# (first encounter).
else:
# Initialize the list.
pos_index[term] = []
# The total frequency is 1.
pos_index[term].append(1)
# The postings list is initially empty.
pos_index[term].append({})
# Add doc ID to postings list.
pos_index[term][1][fileno] = [pos]
# Map the file no. to the file name.
file_map[fileno] = "20_newsgroups/" + folder_name + "/" + file_name
# Increment the file no. counter for document ID mapping
fileno += 1
# Sample positional index to test the code.
sample_pos_idx = pos_index["andrew"]
print("Positional Index")
print(sample_pos_idx)
file_list = sample_pos_idx[1]
print("Filename, [Positions]")
for fileno, positions in file_list.items():
print(file_map[fileno], positions)
输出:
Positional Index
[10, {215: [2081], 539: [66], 591: [879], 616: [462, 473], 680: [135], 691: [2081], 714: [4], 809: [333], 979: [0]}]
Filename, [Positions]
20_newsgroups/comp.graphics/38376 [2081]
20_newsgroups/comp.graphics/38701 [66]
20_newsgroups/comp.graphics/38753 [879]
20_newsgroups/comp.graphics/38778 [462, 473]
20_newsgroups/comp.graphics/38842 [135]
20_newsgroups/comp.graphics/38853 [2081]
20_newsgroups/comp.graphics/38876 [4]
20_newsgroups/comp.graphics/38971 [333]
20_newsgroups/comp.graphics/39663 [0]