使用 SQLAlchemy 将 Pandas 连接到数据库
在本文中,我们将讨论如何使用 SQLAlchemy 将 pandas 连接到数据库并执行数据库操作。
第一步是使用 SQLAlchemy 的 create_engine()函数与现有数据库建立连接。
Syntax:
from sqlalchemy import create_engine
engine = create_engine(dialect+driver://username:password@host:port/database)
Explanation:
- dialect – Name of the DBMS
- driver – Name of the DB API that moves information between SQLAlchemy and the database.
- Username, Password – DB User credentials
- host: port – Specify the type of host and port number.
- Database – Database name
使用 SQLAlchemy 将 Pandas 连接到数据库
Syntax: pandas.DataFrame.to_sql(table_name, engine_name, if_exists, index)
Explanation:
- table_name – Name in which the table has to be stored
- engine_name – Name of the engine which is connected to the database
- if_exists – By default, pandas throws an error if the table_name already exists. Use ‘REPLACE’ to replace this dataset with the old one or “APPEND” to add the data to the existing table.
- index – (bool), Adds index column to the table that identifies each row uniquely.
对于这个例子,我们可以使用 PostgreSQL 数据库,这是最简单的方法之一,但是对于 SQLAlchemy 支持的所有其他数据库,该过程是相同的。您可以在此处下载示例数据集。
让我们首先导入必要的数据集。现在,让我们建立与 PostgreSQL 数据库的连接,并使用 psycopg2 驱动程序使其与Python交互。接下来,我们将使用 to_sql()函数加载要推送到 SQLite 数据库的数据帧,如图所示。
Python3
# import necessary packages
import pandas
import psycopg2
from sqlalchemy import create_engine
# establish connection with the database
engine = create_engine(
"dialect+driver//username:password@hostname:portnumber/databasename")
# read the pandas dataframe
data = pandas.read_csv("path to dataset")
# connect the pandas dataframe with postgresql table
data.to_sql('loan_data', engine, if_exists='replace')Python3
# import necessary packages
import pandas as pd
import psycopg2
from sqlalchemy import create_engine
# establish connection with the database
engine = create_engine(
"dialect+driver//username:password@hostname:portnumber/databasename")
# read the postgresql table
table_df = pd.read_sql_table(
"loan_data",
con=engine,
columns=['Loan_ID',
'Gender',
'Married',
'Dependents',
'Education',
'Self_Employed',
'ApplicantIncome',
'CoapplicantIncome',
'LoanAmount',
'Loan_Amount_Term',
'Credit_History',
'Property_Area',
'Loan_Status'],
)
# print the postgresql table loaded as
# pandas dataframe
print(table_df)Python3
# import necessary packages
import pandas as pd
import psycopg2
from sqlalchemy import create_engine
# establish connection with the database
engine = create_engine(
"dialect+driver//username:password@hostname:portnumber/databasename")
# read table data using sql query
sql_df = pd.read_sql(
"SELECT * FROM loan_data",
con=engine
)
print(sql_df)输出:
这将在 PostgreSQL 数据库中创建一个名为 loan_data 的表。
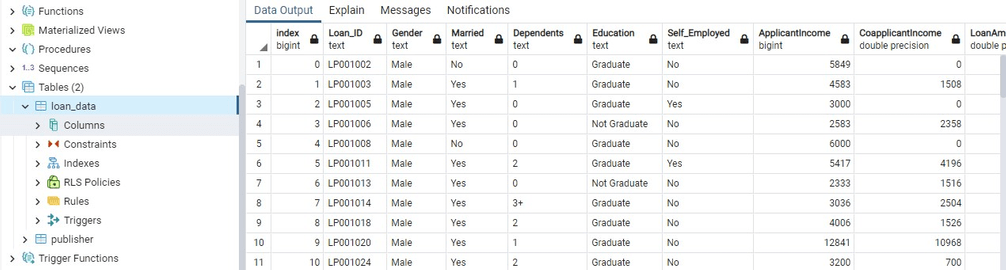
将表连接到 PostgreSQL 数据库
将 PostgreSQL 表转换为 pandas 数据框
就像我们上面所做的那样,我们也可以使用 read_sql_table()函数将 PostgreSQL 表转换为 pandas 数据帧,如下所示。在这里,让我们阅读下图的loan_data表。
Syntax: pandas.DataFrame.read_sql_table(table_name, con = engine_name, columns)
Explanation:
- table_name – Name in which the table has to be stored
- con – Name of the engine which is connected to the database
- columns – list of columns that has to be read from the SQL table
Python3
# import necessary packages
import pandas as pd
import psycopg2
from sqlalchemy import create_engine
# establish connection with the database
engine = create_engine(
"dialect+driver//username:password@hostname:portnumber/databasename")
# read the postgresql table
table_df = pd.read_sql_table(
"loan_data",
con=engine,
columns=['Loan_ID',
'Gender',
'Married',
'Dependents',
'Education',
'Self_Employed',
'ApplicantIncome',
'CoapplicantIncome',
'LoanAmount',
'Loan_Amount_Term',
'Credit_History',
'Property_Area',
'Loan_Status'],
)
# print the postgresql table loaded as
# pandas dataframe
print(table_df)
输出:
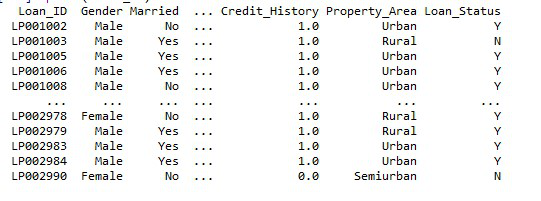
使用 SQLAlchemy 将 Postgresql 表读取为数据框
传递 SQL 查询以查询表数据
我们还可以将 SQL 查询传递给 read_sql_table函数以读取 PostgreSQL 数据库中的只读特定列或记录。程序还是一样的。 SQL 语法与从 SQL 表中查询数据的常规语法相同。下面的例子展示了如何使用 SQL 查询获取loan_data 表的所有记录。
Python3
# import necessary packages
import pandas as pd
import psycopg2
from sqlalchemy import create_engine
# establish connection with the database
engine = create_engine(
"dialect+driver//username:password@hostname:portnumber/databasename")
# read table data using sql query
sql_df = pd.read_sql(
"SELECT * FROM loan_data",
con=engine
)
print(sql_df)
输出:
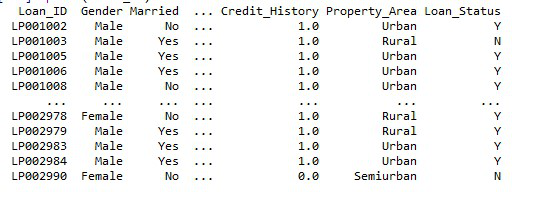
使用 SQLAlchemy 将 Postgresql 表读取为数据框