使用深度学习的 IPL 分数预测
自 2008 年 IPL 诞生以来,它吸引了全球各地的观众。高度的不确定性和最后一刻的咬指甲促使球迷观看比赛。在很短的时间内,IPL 已成为板球创收最高的联盟。在板球比赛中,我们经常会看到比分线显示了球队根据当前比赛情况获胜的概率。这种预测通常是在数据分析的帮助下完成的。在机器学习没有进步之前,预测通常是基于直觉或一些基本算法。上图清楚地告诉您,在有限的板球比赛中,将跑动率作为单一因素来预测最终比分是多么糟糕。

作为板球迷,可视化板球的统计数据令人着迷。我们浏览了各种博客,发现了可用于预先预测 IPL 比赛得分的模式。
为什么是深度学习?
我们人类无法轻易从大量数据中识别模式,因此在这里,机器学习和深度学习发挥了作用。它了解球员和球队之前对阵对方球队的表现,并相应地训练模型。仅使用机器学习算法可提供中等准确性,因此我们使用深度学习,其性能比我们以前的模型好得多,并考虑了可以提供准确结果的属性。
使用的工具:
- Jupyter Notebook / Google colab
- 视觉工作室
使用的技术:
- 机器学习。
- 深度学习
- Flask(前端集成)。
- 好吧,为了项目的顺利运行,我们使用了一些库,如 NumPy、Pandas、Scikit-learn、TensorFlow 和 Matplotlib。
模型架构
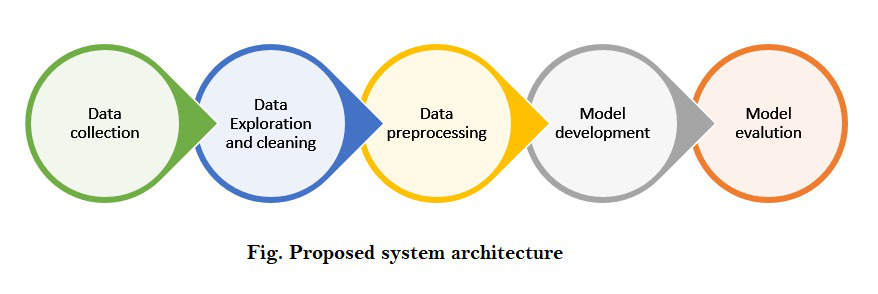
分步实施:
首先,让我们导入所有必要的库:
Python3
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import preprocessingPython3
ipl = pd.read_csv('ipl_dataset.csv')
ipl.head()Python3
data = pd.read_csv('IPL Player Stats - 2016 till 2019.csv')
data.head()Python3
ipl= ipl.drop(['Unnamed: 0','extras','match_id', 'runs_off_bat'],axis = 1)
new_ipl = pd.merge(ipl,data,left_on='striker',right_on='Player',how='left')
new_ipl.drop(['wicket_type', 'player_dismissed'],axis=1,inplace=True)
new_ipl.columnsPython3
str_cols = new_ipl.columns[new_ipl.dtypes==object]
new_ipl[str_cols] = new_ipl[str_cols].fillna('.')Python3
listf = []
for c in new_ipl.columns:
if new_ipl.dtype==object:
print(c,"->" ,new_ipl.dtype)
listf.append(c)Python3
a1 = new_ipl['venue'].unique()
a2 = new_ipl['batting_team'].unique()
a3 = new_ipl['bowling_team'].unique()
a4 = new_ipl['striker'].unique()
a5 = new_ipl['bowler'].unique()
def labelEncoding(data):
dataset = pd.DataFrame(new_ipl)
feature_dict ={}
for feature in dataset:
if dataset[feature].dtype==object:
le = preprocessing.LabelEncoder()
fs = dataset[feature].unique()
le.fit(fs)
dataset[feature] = le.transform(dataset[feature])
feature_dict[feature] = le
return dataset
labelEncoding(new_ipl)Python3
ip_dataset = new_ipl[['venue','innings', 'batting_team',
'bowling_team', 'striker', 'non_striker',
'bowler']]
b1 = ip_dataset['venue'].unique()
b2 = ip_dataset['batting_team'].unique()
b3 = ip_dataset['bowling_team'].unique()
b4 = ip_dataset['striker'].unique()
b5 = ip_dataset['bowler'].unique()
new_ipl.fillna(0,inplace=True)
features={}
for i in range(len(a1)):
features[a1[i]]=b1[i]
for i in range(len(a2)):
features[a2[i]]=b2[i]
for i in range(len(a3)):
features[a3[i]]=b3[i]
for i in range(len(a4)):
features[a4[i]]=b4[i]
for i in range(len(a5)):
features[a5[i]]=b5[i]
featuresPython3
X = new_ipl[['venue', 'innings','batting_team',
'bowling_team', 'striker','bowler']].values
y = new_ipl['y'].values
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=42)Python3
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)Python3
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Dropout
from tensorflow.keras.callbacks import EarlyStoppingPython3
model = Sequential()
model.add(Dense(43, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(22, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(11, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mse')Python3
model.fit(x=X_train, y=y_train, epochs=400,
validation_data=(X_test,y_test),
callbacks=[early_stop] )Python3
model_losses = pd.DataFrame(model.history.history)
model_losses.plot()Python3
predictions = model.predict(X_test)
sample = pd.DataFrame(predictions,columns=['Predict'])
sample['Actual']=y_test
sample.head(10)Python3
from sklearn.metrics import mean_absolute_error,mean_squared_error
mean_absolute_error(y_test,predictions)Python3
np.sqrt(mean_squared_error(y_test,predictions))第 1 步:理解数据集!
在处理板球数据时,Cricsheet 被认为是收集数据的合适平台,因此我们从 https://cricsheet.org/downloads/ipl.zip 获取数据。它包含从 2007 年到 2021 年的数据。为了提高模型的准确性,我们使用 IPL 玩家的统计数据来分析他们的表现。该数据集包含 2016 年至 2019 年每个 IPL 播放器的详细信息。
第 2 步:数据清理和格式化
我们使用.read_csv()方法将两个数据集导入到使用Pandas的数据框中,并显示每个数据集的前 5 行。我们对数据集进行了一些更改,例如添加了一个名为“y”的新列,该列在该特定局的前 6 场比赛中得分。
蟒蛇3
ipl = pd.read_csv('ipl_dataset.csv')
ipl.head()
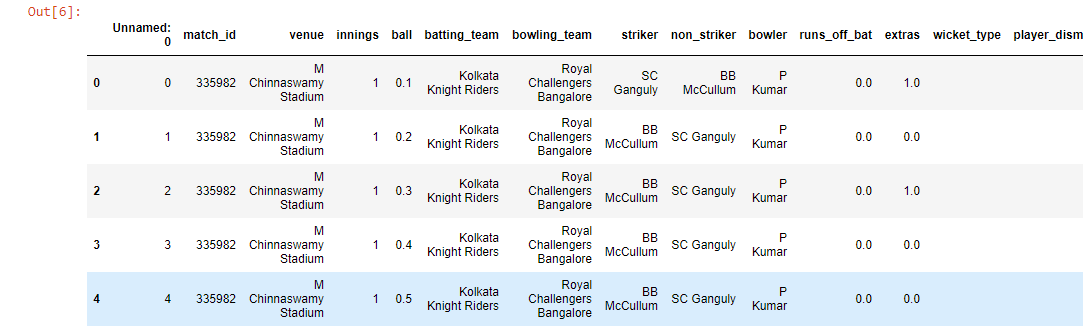
蟒蛇3
data = pd.read_csv('IPL Player Stats - 2016 till 2019.csv')
data.head()
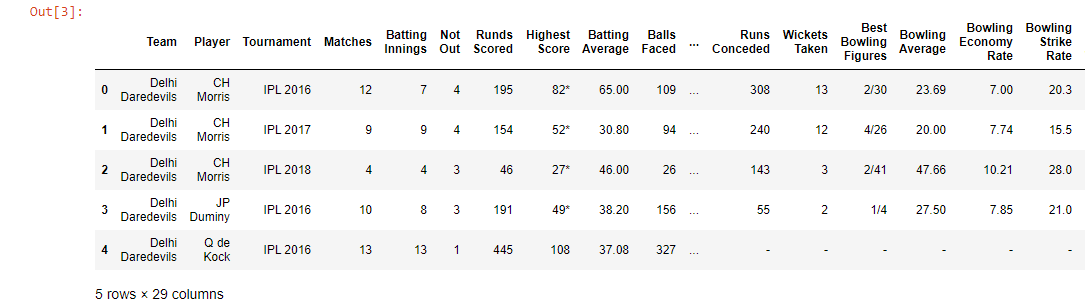
现在,我们将合并两个数据集。
蟒蛇3
ipl= ipl.drop(['Unnamed: 0','extras','match_id', 'runs_off_bat'],axis = 1)
new_ipl = pd.merge(ipl,data,left_on='striker',right_on='Player',how='left')
new_ipl.drop(['wicket_type', 'player_dismissed'],axis=1,inplace=True)
new_ipl.columns
合并列并删除新的不需要的列后,我们还剩下以下列。这是修改后的数据集。

有多种方法可以在我们的数据集中填充空值。在这里,我只是将 nan 的分类值替换为 '.'
蟒蛇3
str_cols = new_ipl.columns[new_ipl.dtypes==object]
new_ipl[str_cols] = new_ipl[str_cols].fillna('.')
步骤 3:将分类数据编码为数值。
对于能够帮助模型进行预测的列,这些值应该对计算机有意义。由于他们(仍然)没有能力理解和从文本中得出推论,我们需要将字符串编码为数字分类值。虽然我们可以选择手动完成该过程,但Scikit-learn 库为我们提供了使用LabelEncoder的选项。
蟒蛇3
listf = []
for c in new_ipl.columns:
if new_ipl.dtype==object:
print(c,"->" ,new_ipl.dtype)
listf.append(c)

蟒蛇3
a1 = new_ipl['venue'].unique()
a2 = new_ipl['batting_team'].unique()
a3 = new_ipl['bowling_team'].unique()
a4 = new_ipl['striker'].unique()
a5 = new_ipl['bowler'].unique()
def labelEncoding(data):
dataset = pd.DataFrame(new_ipl)
feature_dict ={}
for feature in dataset:
if dataset[feature].dtype==object:
le = preprocessing.LabelEncoder()
fs = dataset[feature].unique()
le.fit(fs)
dataset[feature] = le.transform(dataset[feature])
feature_dict[feature] = le
return dataset
labelEncoding(new_ipl)
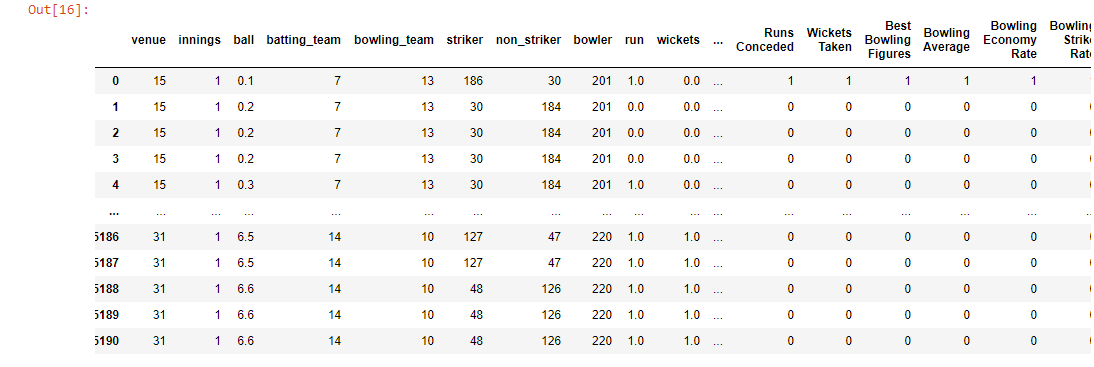
蟒蛇3
ip_dataset = new_ipl[['venue','innings', 'batting_team',
'bowling_team', 'striker', 'non_striker',
'bowler']]
b1 = ip_dataset['venue'].unique()
b2 = ip_dataset['batting_team'].unique()
b3 = ip_dataset['bowling_team'].unique()
b4 = ip_dataset['striker'].unique()
b5 = ip_dataset['bowler'].unique()
new_ipl.fillna(0,inplace=True)
features={}
for i in range(len(a1)):
features[a1[i]]=b1[i]
for i in range(len(a2)):
features[a2[i]]=b2[i]
for i in range(len(a3)):
features[a3[i]]=b3[i]
for i in range(len(a4)):
features[a4[i]]=b4[i]
for i in range(len(a5)):
features[a5[i]]=b5[i]
features
第 4 步:特征工程和选择
我们的数据集包含多个列,但我们无法从用户那里获取这么多输入,因此我们将选定数量的特征作为输入并将它们划分为 X 和 y。然后,在使用机器学习算法之前,我们将我们的数据分为训练集和测试集。
蟒蛇3
X = new_ipl[['venue', 'innings','batting_team',
'bowling_team', 'striker','bowler']].values
y = new_ipl['y'].values
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=42)
通过我们的模型比较这些大数值将很困难,因此在处理数据之前先缩放数据始终是更好的选择。这里我们使用sklearn.preprocessing 中的MinMaxScaler ,这是处理深度学习时推荐的。
蟒蛇3
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
注意:我们无法拟合 X_test,因为它是要预测的数据。
第 5 步:构建、训练和测试模型
这是我们项目中最令人兴奋的部分,构建我们的模型!首先,我们会从tensorflow.keras.models导入顺序此外,我们将我们将使用多个层从tensorflow.keras.layers进口密集和辍学。
蟒蛇3
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Dropout
from tensorflow.keras.callbacks import EarlyStopping
EarlyStopping 用于避免过度拟合。提前停止的主要作用是,当 'val_loss' 比 'loss' 增加时,它停止计算损失。 Val_loss 曲线应始终低于 val 曲线。当发现 'val_loss' 和 'loss' 之间的差异变得恒定时,它停止训练。
蟒蛇3
model = Sequential()
model.add(Dense(43, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(22, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(11, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mse')
在这里,我们创建了 2 个隐藏层并减少了神经元的数量,因为我们希望最终输出为 1。然后在编译我们的模型时,我们使用了adam 优化器和损失作为均方误差。现在,让我们开始用 epochs=400 训练我们的模型。
蟒蛇3
model.fit(x=X_train, y=y_train, epochs=400,
validation_data=(X_test,y_test),
callbacks=[early_stop] )
由于大量的样本和时期,这将需要一些时间,并将输出每个样本的“loss”和“val_loss”,如下所示。

训练完成后,让我们可视化模型的损失。
蟒蛇3
model_losses = pd.DataFrame(model.history.history)
model_losses.plot()
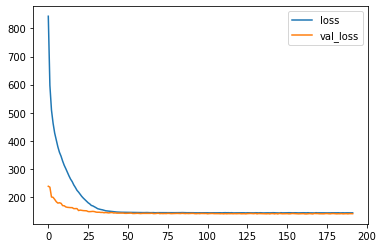
正如我们所看到的,我们的模型具有绝对完美的行为!
第 6 步:预测!
在这里,我们来到项目的最后一部分,我们将在其中预测 X_test。然后我们将创建一个数据框,向我们显示实际值和预测值。
蟒蛇3
predictions = model.predict(X_test)
sample = pd.DataFrame(predictions,columns=['Predict'])
sample['Actual']=y_test
sample.head(10)
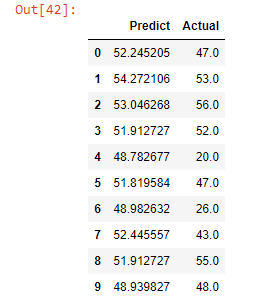
正如我们所看到的,我们的模型预测得很好。它给了我们几乎相似的分数。要了解更准确的实际和预测的分数之间的差异,性能指标将使用mean_absolute_error和mean_squared_error从sklearn.metrics告诉我们错误率
看看我们的前端:

cricster.com
性能指标!
蟒蛇3
from sklearn.metrics import mean_absolute_error,mean_squared_error
mean_absolute_error(y_test,predictions)
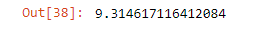
蟒蛇3
np.sqrt(mean_squared_error(y_test,predictions))

让我们来看看我们的模型! 🙂
队员:
- 什拉瓦尼·拉杰古鲁
- 羽衣甘蓝
- 普鲁斯维拉·贾达夫
Github 链接: https : //github.com/hrush25/IPL_score_prediction.git