使用深度学习预测葡萄酒类型
我们对大数据集使用深度学习,但为了理解深度学习的概念,我们使用葡萄酒质量的小数据集。您可以从免费提供的 UCI 机器学习存储库中找到葡萄酒质量数据集。本文的目的是入门深度学习库,如 Keras 等,熟悉神经网络的基础。
关于数据集:
在我们开始加载数据之前,了解您的数据非常重要。数据集由数据中包含的 12 个变量组成。其中少数如下——
- 固定酸度:总酸度分为两类:挥发性酸和非挥发性或固定酸。该变量的值在数据集中以gm/dm3表示。
- 挥发性酸度:挥发性酸度是酒变成醋的过程。在该数据集中,挥发性酸度以 gm/dm3 表示。
- 柠檬酸:柠檬酸是葡萄酒中的一种固定酸。它在数据集中以 g/dm3 表示。
- 残糖:残糖是发酵停止或停止后剩余的糖。它在数据集中以 g/dm3 表示。
- 氯化物:它可能是葡萄酒中咸味的重要因素。该变量的值在数据集中用 gm/dm3 表示。
- 游离二氧化硫:添加到葡萄酒中的二氧化硫部分。该变量的值在数据集中用 gm/dm3 表示。
- 总二氧化硫:它是结合二氧化硫和游离二氧化硫的总和。该变量的值在数据集中以 gm/dm3 表示。
第 1 步:了解您的数据。
加载数据。
Python3
# Import Required Libraries
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
# Read in white wine data
white = pd.read_csv("http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-white.csv", sep =';')
# Read in red wine data
red = pd.read_csv("http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv", sep =';')Python3
# First rows of `red`
red.head()Python3
# Last rows of `white`
white.tail()Python3
# Take a sample of five rows of `red`
red.sample(5)Python3
# Describe `white`
white.describe()Python3
# Double check for null values in `red`
pd.isnull(red)Python3
# Create Histogram
fig, ax = plt.subplots(1, 2)
ax[0].hist(red.alcohol, 10, facecolor ='red',
alpha = 0.5, label ="Red wine")
ax[1].hist(white.alcohol, 10, facecolor ='white',
ec ="black", lw = 0.5, alpha = 0.5,
label ="White wine")
fig.subplots_adjust(left = 0, right = 1, bottom = 0,
top = 0.5, hspace = 0.05, wspace = 1)
ax[0].set_ylim([0, 1000])
ax[0].set_xlabel("Alcohol in % Vol")
ax[0].set_ylabel("Frequency")
ax[1].set_ylim([0, 1000])
ax[1].set_xlabel("Alcohol in % Vol")
ax[1].set_ylabel("Frequency")
fig.suptitle("Distribution of Alcohol in % Vol")
plt.show()Python3
# Add `type` column to `red` with price one
red['type'] = 1
# Add `type` column to `white` with price zero
white['type'] = 0
# Append `white` to `red`
wines = red.append(white, ignore_index = True)
# Import `train_test_split` from `sklearn.model_selection`
from sklearn.model_selection import train_test_split
X = wines.ix[:, 0:11]
y = np.ravel(wines.type)
# Splitting the data set for training and validating
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 0.34, random_state = 45)Python3
# Import `Sequential` from `keras.models`
from keras.models import Sequential
# Import `Dense` from `keras.layers`
from keras.layers import Dense
# Initialize the constructor
model = Sequential()
# Add an input layer
model.add(Dense(12, activation ='relu', input_shape =(11, )))
# Add one hidden layer
model.add(Dense(9, activation ='relu'))
# Add an output layer
model.add(Dense(1, activation ='sigmoid'))
# Model output shape
model.output_shape
# Model summary
model.summary()
# Model config
model.get_config()
# List all weight tensors
model.get_weights()
model.compile(loss ='binary_crossentropy',
optimizer ='adam', metrics =['accuracy'])Python3
# Training Model
model.fit(X_train, y_train, epochs = 3,
batch_size = 1, verbose = 1)
# Predicting the Value
y_pred = model.predict(X_test)
print(y_pred)
`red` 的第一行。
Python3
# First rows of `red`
red.head()
输出:

`white` 的最后几行。
Python3
# Last rows of `white`
white.tail()
输出:

取五行“红色”的样本。
Python3
# Take a sample of five rows of `red`
red.sample(5)
输出:

数据说明——
Python3
# Describe `white`
white.describe()
输出:

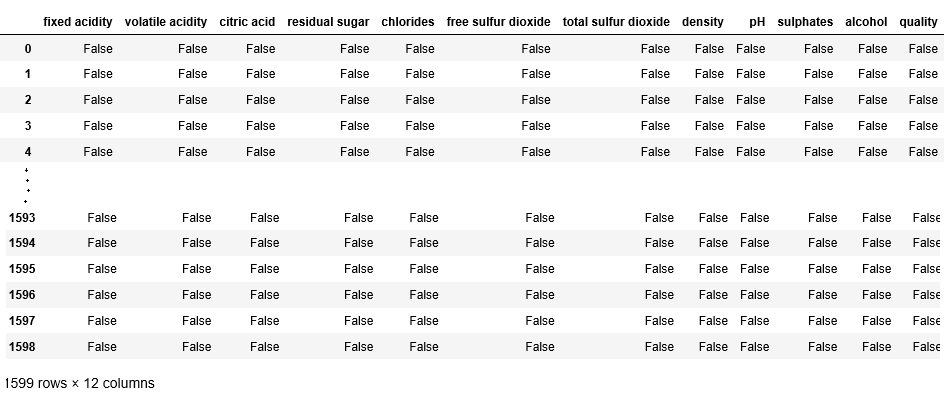
检查 `red` 中的空值。
Python3
# Double check for null values in `red`
pd.isnull(red)
输出:
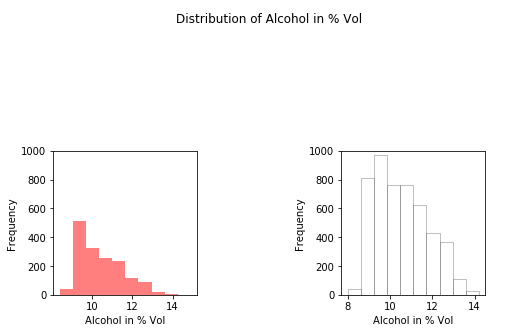
步骤#2:酒精的分配。
创建直方图。
Python3
# Create Histogram
fig, ax = plt.subplots(1, 2)
ax[0].hist(red.alcohol, 10, facecolor ='red',
alpha = 0.5, label ="Red wine")
ax[1].hist(white.alcohol, 10, facecolor ='white',
ec ="black", lw = 0.5, alpha = 0.5,
label ="White wine")
fig.subplots_adjust(left = 0, right = 1, bottom = 0,
top = 0.5, hspace = 0.05, wspace = 1)
ax[0].set_ylim([0, 1000])
ax[0].set_xlabel("Alcohol in % Vol")
ax[0].set_ylabel("Frequency")
ax[1].set_ylim([0, 1000])
ax[1].set_xlabel("Alcohol in % Vol")
ax[1].set_ylabel("Frequency")
fig.suptitle("Distribution of Alcohol in % Vol")
plt.show()
输出:
拆分数据集以进行训练和验证。
Python3
# Add `type` column to `red` with price one
red['type'] = 1
# Add `type` column to `white` with price zero
white['type'] = 0
# Append `white` to `red`
wines = red.append(white, ignore_index = True)
# Import `train_test_split` from `sklearn.model_selection`
from sklearn.model_selection import train_test_split
X = wines.ix[:, 0:11]
y = np.ravel(wines.type)
# Splitting the data set for training and validating
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 0.34, random_state = 45)
步骤#3:网络结构
Python3
# Import `Sequential` from `keras.models`
from keras.models import Sequential
# Import `Dense` from `keras.layers`
from keras.layers import Dense
# Initialize the constructor
model = Sequential()
# Add an input layer
model.add(Dense(12, activation ='relu', input_shape =(11, )))
# Add one hidden layer
model.add(Dense(9, activation ='relu'))
# Add an output layer
model.add(Dense(1, activation ='sigmoid'))
# Model output shape
model.output_shape
# Model summary
model.summary()
# Model config
model.get_config()
# List all weight tensors
model.get_weights()
model.compile(loss ='binary_crossentropy',
optimizer ='adam', metrics =['accuracy'])
输出:

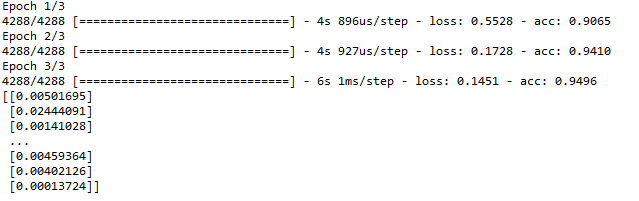
第 4 步:训练和预测
Python3
# Training Model
model.fit(X_train, y_train, epochs = 3,
batch_size = 1, verbose = 1)
# Predicting the Value
y_pred = model.predict(X_test)
print(y_pred)
输出: