使用Python在车站之间获取火车
假设您想使用印度铁路旅行,并想寻找指定车站之间的火车。手动执行此操作可能会非常忙碌。因此,在本文中,我们将编写一个脚本,该脚本将自动从 railyatri 获取数据,并在指定车站之间告诉列车名称及其代码。
需要的模块
- bs4 : Beautiful Soup(bs4) 是一个Python库,用于从 HTML 和 XML 文件中提取数据。这个模块没有内置于Python中。要安装此类型,请在终端中输入以下命令。
pip install bs4
- requests : Request 允许您非常轻松地发送 HTTP/1.1 请求。这个模块也没有内置于Python中。要安装此类型,请在终端中输入以下命令。
pip install requests
让我们看看脚本的逐步执行。
第一步:导入所有依赖
Python3
# import module
import requests
from bs4 import BeautifulSoupPython3
# user define function
# Scrape the data
def getdata(url):
r = requests.get(url)
return r.textPython3
# input by geek
from_Station_code = "NDLS"
from_Station_name = "DELHI"
To_station_code = "PNBE"
To_station_name = "PATNA"
# url
url = "https://www.railyatri.in/booking/trains-between-stations?from_code="+from_Station_code+"&from_name="+from_Station_name+"+JN+&journey_date=+Wed&src=tbs&to_code=" + \
To_station_code+"&to_name="+To_station_name + \
"+JN+&user_id=-1603228437&user_token=355740&utm_source=dwebsearch_tbs_search_trains"
# pass the url
# into getdata function
htmldata = getdata(url)
soup = BeautifulSoup(htmldata, 'html.parser')
# display html code
print(soup)Python3
# find the Html tag
# with find()
# and convert into string
data_str = ""
for item in soup.find_all("div", class_="col-xs-12 TrainSearchSection"):
data_str = data_str + item.get_text()
result = data_str.split("\n")
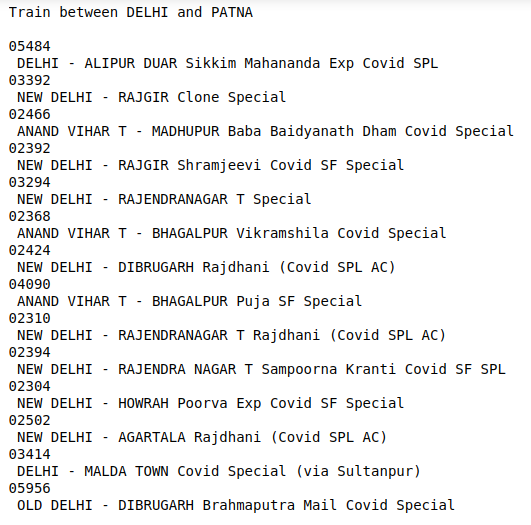
print("Train between "+from_Station_name+" and "+To_station_name)
print("")
# Display the result
for item in result:
if item != "":
print(item)Python3
# import module
import requests
from bs4 import BeautifulSoup
# user define function
# Scrape the data
def getdata(url):
r = requests.get(url)
return r.text
# input by geek
from_Station_code = "GAYA"
from_Station_name = "GAYA"
To_station_code = "PNBE"
To_station_name = "PATNA"
# url
url = "https://www.railyatri.in/booking/trains-between-stations?from_code="+from_Station_code+"&from_name="+from_Station_name+"+JN+&journey_date=+Wed&src=tbs&to_code=" + \
To_station_code+"&to_name="+To_station_name + \
"+JN+&user_id=-1603228437&user_token=355740&utm_source=dwebsearch_tbs_search_trains"
# pass the url
# into getdata function
htmldata = getdata(url)
soup = BeautifulSoup(htmldata, 'html.parser')
# find the Html tag
# with find()
# and convert into string
data_str = ""
for item in soup.find_all("div", class_="col-xs-12 TrainSearchSection"):
data_str = data_str + item.get_text()
result = data_str.split("\n")
print("Train between "+from_Station_name+" and "+To_station_name)
print("")
# Display the result
for item in result:
if item != "":
print(item)第 2 步:创建 URL 获取函数
蟒蛇3
# user define function
# Scrape the data
def getdata(url):
r = requests.get(url)
return r.text
第 3 步:现在将电台名称和电台代码合并到 URL 中,并将 URL 传递到 getdata()函数并将该数据转换为 HTML 代码。
蟒蛇3
# input by geek
from_Station_code = "NDLS"
from_Station_name = "DELHI"
To_station_code = "PNBE"
To_station_name = "PATNA"
# url
url = "https://www.railyatri.in/booking/trains-between-stations?from_code="+from_Station_code+"&from_name="+from_Station_name+"+JN+&journey_date=+Wed&src=tbs&to_code=" + \
To_station_code+"&to_name="+To_station_name + \
"+JN+&user_id=-1603228437&user_token=355740&utm_source=dwebsearch_tbs_search_trains"
# pass the url
# into getdata function
htmldata = getdata(url)
soup = BeautifulSoup(htmldata, 'html.parser')
# display html code
print(soup)
输出:
第 4 步:现在从 HTML 代码中找到所需的标签并遍历结果。
蟒蛇3
# find the Html tag
# with find()
# and convert into string
data_str = ""
for item in soup.find_all("div", class_="col-xs-12 TrainSearchSection"):
data_str = data_str + item.get_text()
result = data_str.split("\n")
print("Train between "+from_Station_name+" and "+To_station_name)
print("")
# Display the result
for item in result:
if item != "":
print(item)
输出:
全面实施。
蟒蛇3
# import module
import requests
from bs4 import BeautifulSoup
# user define function
# Scrape the data
def getdata(url):
r = requests.get(url)
return r.text
# input by geek
from_Station_code = "GAYA"
from_Station_name = "GAYA"
To_station_code = "PNBE"
To_station_name = "PATNA"
# url
url = "https://www.railyatri.in/booking/trains-between-stations?from_code="+from_Station_code+"&from_name="+from_Station_name+"+JN+&journey_date=+Wed&src=tbs&to_code=" + \
To_station_code+"&to_name="+To_station_name + \
"+JN+&user_id=-1603228437&user_token=355740&utm_source=dwebsearch_tbs_search_trains"
# pass the url
# into getdata function
htmldata = getdata(url)
soup = BeautifulSoup(htmldata, 'html.parser')
# find the Html tag
# with find()
# and convert into string
data_str = ""
for item in soup.find_all("div", class_="col-xs-12 TrainSearchSection"):
data_str = data_str + item.get_text()
result = data_str.split("\n")
print("Train between "+from_Station_name+" and "+To_station_name)
print("")
# Display the result
for item in result:
if item != "":
print(item)
输出:
