使用 Pandas groupby 连接多行中的字符串
Pandas Dataframe.groupby()方法用于根据某些标准将数据分组。分组的抽象定义是提供标签到组名的映射。
要使用Dataframe.groupby()连接多行中的字符串,请执行以下步骤:
- 使用需要连接其属性的 Dataframe.groupby() 方法对数据进行分组。
- 使用 join函数连接字符串,并使用lambda语句转换该列的值。
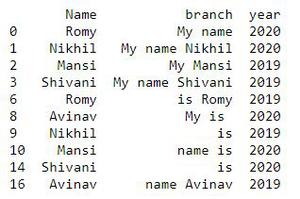
我们将使用具有 2 列的 CSV 文件,文件内容如下图所示:
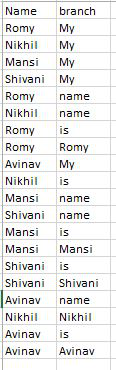
示例 1:我们将连接分支列中具有相同名称的数据。
Python3
# import pandas library
import pandas as pd
# read csv file
df = pd.read_csv("Book2.csv")
# concatenate the string
df['branch'] = df.groupby(['Name'])['branch'].transform(lambda x : ' '.join(x))
# drop duplicate data
df = df.drop_duplicates()
# show the dataframe
print(df)Python3
# import pandas library
import pandas as pd
# read a csv file
df = pd.read_csv("Book1.csv")
# concatenate the string
df['branch'] = df.groupby(['Name', 'year'])['branch'].transform(
lambda x: ' '.join(x))
# drop duplicate data
df = df.drop_duplicates()
# show the dataframe
df输出:

示例 2:我们也可以在多个列上执行 Pandas groupby。
我们将使用具有 3 列的 CSV 文件,文件内容如下图所示:
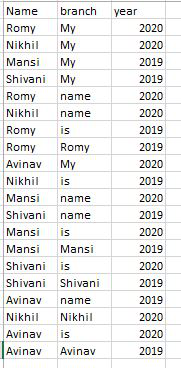
在名称和年份列上应用 groupby
Python3
# import pandas library
import pandas as pd
# read a csv file
df = pd.read_csv("Book1.csv")
# concatenate the string
df['branch'] = df.groupby(['Name', 'year'])['branch'].transform(
lambda x: ' '.join(x))
# drop duplicate data
df = df.drop_duplicates()
# show the dataframe
df
输出: