给定一个字符串,找到最长的子字符串,即回文。
- 如果给定的字符串为“ forgeeksskeegfor”,则输出应为“ geeksskeeg”
- 如果给定的字符串是“ abaaba”,则输出应为“ abaaba”
- 如果给定的字符串是“ abababa”,则输出应为“ abababa”
- 如果给定的字符串为“ abcbabcbabcba”,则输出应为“ abcbabcbabcba”
我们已经讨论了集合1和集合2的朴素[O(n 3 )]和二次[O(n 2 )]方法。
在本文中,我们将讨论Manacher算法,该算法在线性时间内找到最长回文子串。
查找回文的一种方法(集合2)是从字符串的中心开始,然后一个个地比较两个方向上的字符。如果两侧(中心的左侧和右侧)的对应字符匹配,则它们将构成回文。
让我们考虑字符串“ abababa”。
在这里,字符串的中心是第四个字符(索引为3)b。如果我们在中心的左右两侧匹配字符,则所有字符匹配,因此字符串“ abababa”是回文。

这里的中心位置不仅是实际的字符串字符位置,而且还可以是两个字符之间的位置。
考虑长度相等的字符串“ abaaba”。该字符串是回文,分别位于第3个字符和第4个字符a和a之间。

要找到长度为N的字符串的最长回文子字符串,一种方法是取每个可能的2 * N + 1个中心(N个字符位置,两个字符位置之间为N-1,左右两端为2个位置),执行该字符在每个2 * N + 1个中心沿左右方向匹配,并跟踪LPS。这种方法需要O(N ^ 2)的时间,这就是我们在Set 2中所做的。
让我们考虑两个字符串“ abababa”和“ abaaba”,如下所示:


在这两个字符串,中心位置(第一字符串的位置7和第二字符串的位置6)的左侧和右侧是对称的。为什么?因为整个字符串是回文,在中心位置附近。
如果我们需要从左到右在每个2 * N + 1位置计算最长回文子串,那么回文的对称属性可以帮助避免一些不必要的计算(即字符比较)。如果在任何位置P处都存在一个长度为L的回文,那么我们可能不需要比较位置P + 1处左侧和右侧的所有字符。我们已经在P之前的位置计算了LPS,它们可以帮助避免在P位置之后进行某些比较。
在较晚的时间点使用来自先前位置的信息使Manacher的算法呈线性。在集合2中,没有重用先前的信息,因此是二次的。
Manacher的算法可能被认为很复杂,因此在这里我们将尽可能详细地讨论它。其中的某些部分可能需要多次阅读才能正确理解。
让我们看一下字符串“ abababa”。在上面的第三张图中,显示了15个中心位置。我们需要计算每个位置上最长回文字符串的长度。
- 在位置0,根本没有LPS(左侧没有要比较的字符),因此LPS的长度将为0。
- 在位置1,LPS为a,因此LPS的长度为1。
- 在位置2,根本没有LPS(左右字符a和b不匹配),因此LPS的长度将为0。
- 在位置3,LPS是aba,因此LPS的长度将是3。
- 在位置4,根本没有LPS(左右字符b和a不匹配),因此LPS的长度将为0。
- 在位置5,LPS是ababa,因此LPS的长度将是5。
…… 等等
我们将所有这些回文长度存储在一个数组中,例如L。然后,字符串S和LPS Length L如下所示:

同样,字符串“ abaaba”的LPS长度L如下所示:

在LPS阵列L中:
- 在奇数位置(实际字符位置)的LPS长度值将是奇数且大于或等于1(如果中心字符本身的左侧和右侧没有其他匹配项,则1将来自中心字符本身)
- 偶数位置(两个字符之间的位置,左右极位置)处的LPS长度值将等于且大于或等于0(左右不匹配时为0)
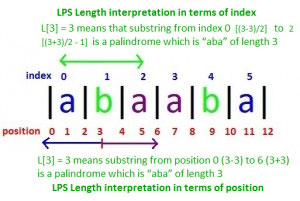
字符串的位置和索引在这里是两个不同的东西。对于长度为N的给定字符串S,索引将从0到N-1(总共N个索引),位置将从0到2 * N(总共2 * N + 1个位置)。
LPS长度值可以用两种方式解释,一种以指数表示,第二种以位置表示。在位置I(L [i] = d)处的LPS值d表示:
- 从位置id到i + d的子字符串是长度为d的回文(就位置而言)
- 从索引(id)/ 2到[(i + d)/ 2 – 1]的子字符串是长度为d的回文(就索引而言)
例如,在字符串“ abaaba”中,L [3] = 3表示从位置0(3-3)到6(3 + 3)的子字符串是回文,长度为3的“ aba”,这也意味着从索引0开始的子字符串[(3-3)/ 2]至2 [(3 + 3)/ 2 – 1]是回文,长度为3。
现在的主要任务是有效地计算LPS阵列。一旦计算出此数组,字符串S的LPS将以最大LPS长度值的位置为中心。
我们将在第2部分中看到它。