使用 Pandas 选择包含特定文本的行
在使用 pandas 数据框预处理数据时,可能需要查找包含特定文本的行。在本文中,我们将讨论在 pandas 的数据帧的列或行中查找包含特定文本的行的方法。
使用中的数据集:job Age_Range Salary Credit-Rating Savings Buys_Hone Own Middle-aged High Fair 10000 Yes Govt Young Low Fair 15000 No Private Senior Average Excellent 20000 Yes Own Middle-aged High Fair 13000 No Own Young Low Excellent 17000 Yes Private Senior Average Fair 18000 No Govt Young Average Fair 11000 No Private Middle-aged Low Excellent 9000 No Govt Senior High Excellent 14000 Yes
方法 1:使用 contains()
使用字符串的 contains()函数来过滤行。我们根据数据框的“信用评级”列过滤行,方法是将其转换为字符串,然后是字符串类的 contains 方法。 contains() 方法接受一个参数并在调用它的对象中找到模式。
例子:
Python3
# importing pandas as pd
import pandas as pd
# reading csv file
df = pd.read_csv("Assignment.csv")
# filtering the rows where Credit-Rating is Fair
df = df[df['Credit-Rating'].str.contains('Fair')]
print(df)Python3
# importing pandas as pd
import pandas as pd
# reading csv file
df = pd.read_csv("Assignment.csv")
# filtering the rows where Age_Range contains Young
for x in df.itertuples():
if x[2].find('Young') != -1:
print(x)Python3
# importing pandas as pd
import pandas as pd
# reading csv file
df = pd.read_csv("Assignment.csv")
# filtering the rows where job is Govt
for index, row in df.iterrows():
if 'Govt' in row['job']:
print(index, row['job'], row['Age_Range'],
row['Salary'], row['Savings'], row['Credit-Rating'])Python3
# using regular expressions
from re import search
# import pandas as pd
import pandas as pd
# reading CSV file
df = pd.read_csv("Assignment.csv")
# iterating over rows with job as Govt and printing
for ind in df.index:
if search('Govt', df['job'][ind]):
print(df['job'][ind], df['Savings'][ind],
df['Age_Range'][ind], df['Credit-Rating'][ind])输出 :

包含 Fair as Savings 的行
方法 2:使用 itertuples()
使用 itertuples() 通过 find 迭代行以获取包含所需文本的行。 itertuple 方法返回一个迭代器,为 DataFrame 中的每一行生成一个命名元组。它比熊猫的 iterrows() 方法工作得更快。
例子:
蟒蛇3
# importing pandas as pd
import pandas as pd
# reading csv file
df = pd.read_csv("Assignment.csv")
# filtering the rows where Age_Range contains Young
for x in df.itertuples():
if x[2].find('Young') != -1:
print(x)
输出 :
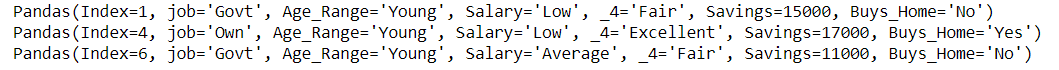
Age_Range 为年轻的行
方法 3:使用 iterrows()
使用 iterrows() 通过 find 迭代行以获取包含所需文本的行。 iterrows()函数返回产生每个索引值的迭代器以及包含每行数据的系列。与 itertuples 相比,它更慢,因为它进行了大量类型检查。
例子:
蟒蛇3
# importing pandas as pd
import pandas as pd
# reading csv file
df = pd.read_csv("Assignment.csv")
# filtering the rows where job is Govt
for index, row in df.iterrows():
if 'Govt' in row['job']:
print(index, row['job'], row['Age_Range'],
row['Salary'], row['Savings'], row['Credit-Rating'])
输出 :

担任政府职务的行
方法四:使用正则表达式
使用正则表达式查找具有所需文本的行。 search() 是模块 re 的一个方法。 re.search(pattern, 字符串):它类似于 re.match() 但它不限制我们只在字符串的开头查找匹配项。我们正在迭代每一行,并将每个索引处的作业与“Govt”进行比较,以仅选择这些行。
例子:
蟒蛇3
# using regular expressions
from re import search
# import pandas as pd
import pandas as pd
# reading CSV file
df = pd.read_csv("Assignment.csv")
# iterating over rows with job as Govt and printing
for ind in df.index:
if search('Govt', df['job'][ind]):
print(df['job'][ind], df['Savings'][ind],
df['Age_Range'][ind], df['Credit-Rating'][ind])
输出 :

工作是政府的行