Kullback-Leibler 散度
熵:熵是一种测量随机变量 X 的不确定性/随机性的方法
换句话说,熵测量随机变量中的信息量。它通常以位为单位进行测量。
联合熵:一对离散随机变量 X, Y ~ p (x, y) 的联合熵是指定它们的值平均所需的信息量。

条件熵:给定另一个 X 的随机变量 Y 的条件熵表示在另一方知道 X 的情况下,一个人平均还需要提供多少额外信息来传达 Y。


例子:
计算公平硬币的熵:

![= - [p(head)log\left ( p(head) \right ) + p(tail)log\left ( p(tail) \right )] \\ = - [\frac{1}{2}log\frac{1}{2} + \frac{1}{2}log\frac{1}{2}] \\ = - [-\left ( \frac{1}{2} log2 + \frac{1}{2}log2 \right )] \\ = [\frac{1}{2} + \frac{1}{2}] \\ = 1](https://mangodoc.oss-cn-beijing.aliyuncs.com/geek8geeks/Kullback-Leibler_Divergence_7.jpg "由 QuickLaTeX.com 渲染")
在这里,公平硬币的熵最大,即 1。随着硬币的偏差增加,信息/熵减少。下面是 Entropy vs Biasness 的图,曲线如下:
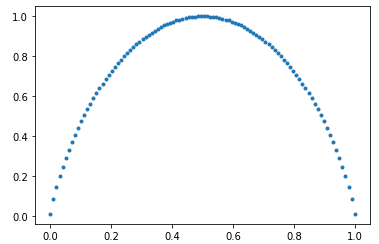
硬币与熵的偏差
交叉熵:交叉熵是对给定随机变量或事件集的两个概率分布(p 和 q)之间差异的度量。换句话说,C ross-entropy 是当我们使用模型q时对来自分布源p 的数据进行编码所需的平均位数。
交叉熵可以定义为:
![H_p\left ( p,q \right ) = E_p\left [ - log \left ( q(x) \right ) \right ] = -\sum_{x \epsilon \Omega} p(x) log (q(x))](https://mangodoc.oss-cn-beijing.aliyuncs.com/geek8geeks/Kullback-Leibler_Divergence_9.jpg "由 QuickLaTeX.com 渲染")
Kullback-Leibler 散度: KL 散度是对给定随机变量或一组事件的两个概率分布之间的相对差异的度量。 KL散度也称为相对熵。可以通过以下公式计算:

Cross-Entropy 和 KL-divergence 的区别在于,Cross-Entropy 计算从分布 q 而不是 p 中表示事件所需的总分布,而 KL-divergence 表示从分布中表示事件所需的额外比特量q 而不是 p。
KL散度的性质:
D(p || q) 总是大于或等于 0。
D(p || q) 不等于 D(q || p)。 KL 散度不具有交流性。
如果 p=q,则 D(p || q) 为 0。
示例和实现:
假设有两个包含 4 种类型球(绿色、蓝色、红色、黄色)的盒子。从盒子中随机抽取一个球,具有给定的概率。我们的任务是计算两个框的分布差异,即KL-divergence。
代码:解决这个问题的Python代码实现。
# box =[P(green),P(blue),P(red),P(yellow)]
box_1 = [0.25, 0.33, 0.23, 0.19]
box_2 = [0.21, 0.21, 0.32, 0.26]
import numpy as np
from scipy.special import rel_entr
def kl_divergence(a, b):
return sum(a[i] * np.log(a[i]/b[i]) for i in range(len(a)))
print('KL-divergence(box_1 || box_2): %.3f ' % kl_divergence(box_1,box_2))
print('KL-divergence(box_2 || box_1): %.3f ' % kl_divergence(box_2,box_1))
# D( p || p) =0
print('KL-divergence(box_1 || box_1): %.3f ' % kl_divergence(box_1,box_1))
print("Using Scipy rel_entr function")
box_1 = np.array(box_1)
box_2 = np.array(box_2)
print('KL-divergence(box_1 || box_2): %.3f ' % sum(rel_entr(box_1,box_2)))
print('KL-divergence(box_2 || box_1): %.3f ' % sum(rel_entr(box_2,box_1)))
print('KL-divergence(box_1 || box_1): %.3f ' % sum(rel_entr(box_1,box_1)))
输出:
KL-divergence(box_1 || box_2): 0.057
KL-divergence(box_2 || box_1): 0.056
KL-divergence(box_1 || box_1): 0.000
Using Scipy rel_entr function
KL-divergence(box_1 || box_2): 0.057
KL-divergence(box_2 || box_1): 0.056
KL-divergence(box_1 || box_1): 0.000 KL散度的应用:
熵和 KL 散度有许多有用的应用,特别是在数据科学和压缩方面。
- 熵可用于数据预处理步骤,例如特征选择。例如,如果我们想根据主题对不同的 NLP 文档进行分类,那么我们可以检查文档中出现的不同单词的随机性。 “计算机”这个词出现在技术相关文档中的机会更多,但“the”这个词就不是这样了。
- 熵也可用于文本压缩和量化压缩。包含某种模式的数据比更随机的数据更容易压缩。
- KL-divergence 也用于许多 NLP 和计算机视觉模型,例如在 Variational Auto Encoder 中,以比较原始图像分布和从编码分布生成的图像分布。