门控循环单元网络
先决条件:循环神经网络、长短期记忆网络
为了解决在基本循环神经网络的操作过程中经常遇到的消失-爆炸梯度问题,开发了许多变体。最著名的变体之一是长短期记忆网络(LSTM) 。鲜为人知但同样有效的变体之一是门控循环单元网络(GRU) 。
与 LSTM 不同,它仅由三个门组成,并且不保持内部单元状态。存储在 LSTM 循环单元的内部单元状态中的信息被合并到门控循环单元的隐藏状态中。这个集体信息被传递到下一个门控循环单元。 GRU 的不同门如下所述:-
- 更新门(z):它确定有多少过去的知识需要传递到未来。它类似于 LSTM 循环单元中的输出门。
- 重置门(r):它确定要忘记多少过去的知识。它类似于 LSTM 循环单元中输入门和遗忘门的组合。
- 当前记忆门(
 ):在关于门控循环单元网络的典型讨论中,它经常被忽略。它被合并到复位门中,就像输入调制门是输入门的子部分一样,用于将一些非线性引入输入,并使输入为零均值。使其成为重置门的子部分的另一个原因是减少先前信息对传递到未来的当前信息的影响。
):在关于门控循环单元网络的典型讨论中,它经常被忽略。它被合并到复位门中,就像输入调制门是输入门的子部分一样,用于将一些非线性引入输入,并使输入为零均值。使其成为重置门的子部分的另一个原因是减少先前信息对传递到未来的当前信息的影响。
门控循环单元网络的基本工作流程类似于图示的基本循环神经网络,两者之间的主要区别在于每个循环单元的内部工作,因为门控循环单元网络由调节当前输入和之前的隐藏状态。
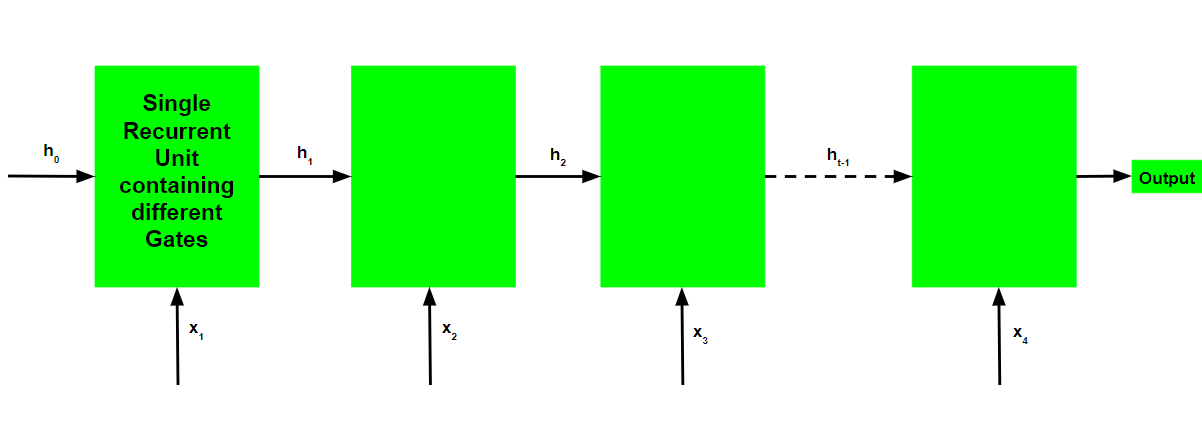
门控循环单元的工作:
- 将输入当前输入和之前的隐藏状态作为向量。
- 按照下面给出的步骤计算三个不同门的值:-
- 对于每个门,通过在相关向量和每个门的相应权重之间执行逐元素乘法(哈德积)来计算参数化的当前输入和先前隐藏的状态向量。
- 在参数化向量上按元素对每个门应用相应的激活函数。下面给出了具有要应用于门的激活函数的门列表。
Update Gate : Sigmoid Function
Reset Gate : Sigmoid Function- 计算当前记忆门的过程有点不同。首先,计算重置门和先前隐藏状态向量的 Hadmard 积。然后这个向量被参数化,然后添加到参数化的当前输入向量。

- 为了计算当前的隐藏状态,首先,定义一个与输入相同维度的向量。这个向量将被称为 1 并在数学上用 1 表示。首先,计算更新门和先前隐藏状态向量的哈德玛积。然后通过从一个中减去更新门来生成一个新向量,然后计算新生成的向量与当前记忆门的哈德玛积。最后,将两个向量相加得到当前隐藏状态向量。
上述工作说明如下:-

请注意,蓝色圆圈表示逐元素乘法。圆圈中的正号表示矢量相加,而负号表示矢量相减(负值矢量相加)。权重矩阵 W 包含当前输入向量和每个门的先前隐藏状态的不同权重。
就像循环神经网络一样,GRU 网络也在每个时间步生成一个输出,这个输出用于使用梯度下降训练网络。
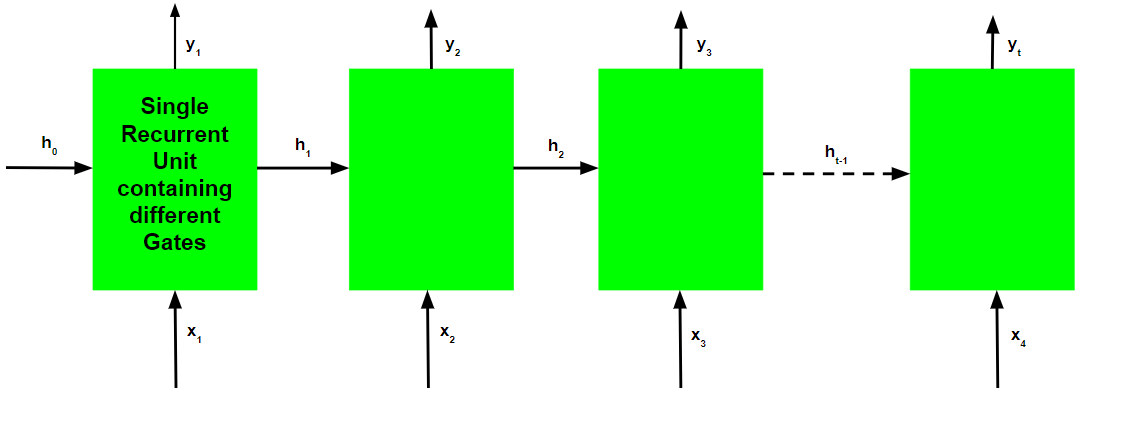
请注意,就像工作流程一样,GRU 网络的训练过程在图表上也与基本循环神经网络的训练过程相似,不同之处仅在于每个循环单元的内部工作。
门控循环单元网络的时间反向传播算法类似于长短期记忆网络,不同之处仅在于微分链的形成。
让 是每个时间步的预测输出,并且
是每个时间步的预测输出,并且 是每个时间步的实际输出。然后每个时间步的误差由下式给出:-
是每个时间步的实际输出。然后每个时间步的误差由下式给出:-

因此,总误差由所有时间步长的误差总和给出。


同样,值 可以计算为每个时间步的梯度之和。
可以计算为每个时间步的梯度之和。

使用链式法则并使用以下事实 是一个函数
是一个函数 这函数是
这函数是 ,出现以下表达式:-
因此,总误差梯度由下式给出:-
请注意,梯度方程涉及一个链它看起来类似于基本的循环神经网络,但是由于导数的内部工作原理,这个方程的工作方式不同
 .
.
门控循环单元如何解决梯度消失的问题?
梯度的值由导数链控制,从 .回想一下表达式
.回想一下表达式 :-
:-
使用上面的表达式,值是:-
回想一下表达式 :-
使用上面的表达式计算的值 :-
由于更新门和重置门都使用 sigmoid函数作为它们的激活函数,因此两者都可以取值 0 或 1。
案例 1(z = 1):
在这种情况下,无论 , 术语
等于z,而z又等于1。
案例 2A(z=0 和 r=0):
在这种情况下,术语等于 0。
案例 2B(z=0 和 r=1):
在这种情况下,术语等于
.该值由可训练的权重矩阵控制,因此网络学会以这样的方式调整权重,即
接近 1。
因此,时间反向传播算法以这样一种方式调整各自的权重,使导数链的值尽可能接近 1。