将 Lambda 函数应用于 Pandas 数据框
在 Pandas 中,我们可以根据需要自由添加不同的函数,例如 lambda函数、排序函数等。我们可以将 lambda函数应用于 Pandas 数据框的列和行。
Syntax: lambda arguments: expression
An anonymous function which we can pass in instantly without defining a name or any thing like a full traditional function.
示例 1:使用 Dataframe.assign() 将lambda函数应用于单列
Python3
# importing pandas library
import pandas as pd
# creating and initializing a list
values= [['Rohan',455],['Elvish',250],['Deepak',495],
['Soni',400],['Radhika',350],['Vansh',450]]
# creating a pandas dataframe
df = pd.DataFrame(values,columns=['Name','Total_Marks'])
# Applying lambda function to find
# percentage of 'Total_Marks' column
# using df.assign()
df = df.assign(Percentage = lambda x: (x['Total_Marks'] /500 * 100))
# displaying the data frame
dfPython3
# importing pandas library
import pandas as pd
# creating and initializing a nested list
values_list = [[15, 2.5, 100], [20, 4.5, 50], [25, 5.2, 80],
[45, 5.8, 48], [40, 6.3, 70], [41, 6.4, 90],
[51, 2.3, 111]]
# creating a pandas dataframe
df = pd.DataFrame(values_list, columns=['Field_1', 'Field_2', 'Field_3'])
# Applying lambda function to find
# the product of 3 columns using
# df.assign()
df = df.assign(Product=lambda x: (x['Field_1'] * x['Field_2'] * x['Field_3']))
# printing dataframe
dfPython3
# importing pandas and numpy libraries
import pandas as pd
import numpy as np
# creating and initializing a nested list
values_list = [[15, 2.5, 100], [20, 4.5, 50], [25, 5.2, 80],
[45, 5.8, 48], [40, 6.3, 70], [41, 6.4, 90],
[51, 2.3, 111]]
# creating a pandas dataframe
df = pd.DataFrame(values_list, columns=['Field_1', 'Field_2', 'Field_3'],
index=['a', 'b', 'c', 'd', 'e', 'f', 'g'])
# Apply function numpy.square() to square
# the values of one row only i.e. row
# with index name 'd'
df = df.apply(lambda x: np.square(x) if x.name == 'd' else x, axis=1)
# printing dataframe
dfPython3
# importing pandas and numpylibraries
import pandas as pd
import numpy as np
# creating and initializing a nested list
values_list = [[15, 2.5, 100], [20, 4.5, 50], [25, 5.2, 80],
[45, 5.8, 48], [40, 6.3, 70], [41, 6.4, 90],
[51, 2.3, 111]]
# creating a pandas dataframe
df = pd.DataFrame(values_list, columns=['Field_1', 'Field_2', 'Field_3'],
index=['a', 'b', 'c', 'd', 'e', 'f', 'g'])
# Apply function numpy.square() to square
# the values of 3 rows only i.e. with row
# index name 'a', 'e' and 'g' only
df = df.apply(lambda x: np.square(x) if x.name in [
'a', 'e', 'g'] else x, axis=1)
# printing dataframe
dfPython3
# importing pandas and numpylibraries
import pandas as pd
import numpy as np
# creating and initializing a nested list
values_list = [[1.5, 2.5, 10.0], [2.0, 4.5, 5.0], [2.5, 5.2, 8.0],
[4.5, 5.8, 4.8], [4.0, 6.3, 70], [4.1, 6.4, 9.0],
[5.1, 2.3, 11.1]]
# creating a pandas dataframe
df = pd.DataFrame(values_list, columns=['Field_1', 'Field_2', 'Field_3'],
index=['a', 'b', 'c', 'd', 'e', 'f', 'g'])
# Apply function numpy.square() to square
# the values of 2 rows only i.e. with row
# index name 'b' and 'f' only
df = df.apply(lambda x: np.square(x) if x.name in ['b', 'f'] else x, axis=1)
# Applying lambda function to find product of 3 columns
# i.e 'Field_1', 'Field_2' and 'Field_3'
df = df.assign(Product=lambda x: (x['Field_1'] * x['Field_2'] * x['Field_3']))
# printing dataframe
df输出 :
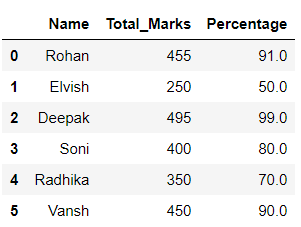
在上面的示例中,lambda函数应用于“Total_Marks”列,并在它的帮助下形成了一个新列“Percentage”。
示例 2:使用 Dataframe.assign() 将lambda函数应用于多列
Python3
# importing pandas library
import pandas as pd
# creating and initializing a nested list
values_list = [[15, 2.5, 100], [20, 4.5, 50], [25, 5.2, 80],
[45, 5.8, 48], [40, 6.3, 70], [41, 6.4, 90],
[51, 2.3, 111]]
# creating a pandas dataframe
df = pd.DataFrame(values_list, columns=['Field_1', 'Field_2', 'Field_3'])
# Applying lambda function to find
# the product of 3 columns using
# df.assign()
df = df.assign(Product=lambda x: (x['Field_1'] * x['Field_2'] * x['Field_3']))
# printing dataframe
df
输出 :
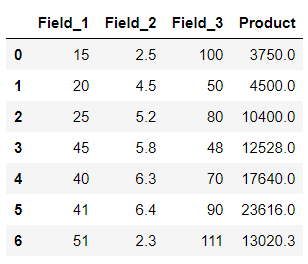
在上面的示例中,lambda函数应用于 3 列,即“Field_1”、“Field_2”和“Field_3”。
示例 3 :使用 Dataframe.apply() 将lambda函数应用于单行
Python3
# importing pandas and numpy libraries
import pandas as pd
import numpy as np
# creating and initializing a nested list
values_list = [[15, 2.5, 100], [20, 4.5, 50], [25, 5.2, 80],
[45, 5.8, 48], [40, 6.3, 70], [41, 6.4, 90],
[51, 2.3, 111]]
# creating a pandas dataframe
df = pd.DataFrame(values_list, columns=['Field_1', 'Field_2', 'Field_3'],
index=['a', 'b', 'c', 'd', 'e', 'f', 'g'])
# Apply function numpy.square() to square
# the values of one row only i.e. row
# with index name 'd'
df = df.apply(lambda x: np.square(x) if x.name == 'd' else x, axis=1)
# printing dataframe
df
输出 :
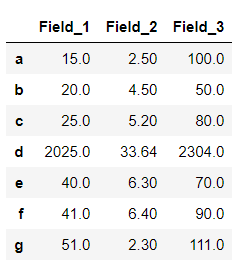
在上面的示例中,一个 lambda函数应用于以 'd' 开头的行,因此所有值都与其对应。
示例 4:使用 Dataframe.apply() 将lambda函数应用于多行
Python3
# importing pandas and numpylibraries
import pandas as pd
import numpy as np
# creating and initializing a nested list
values_list = [[15, 2.5, 100], [20, 4.5, 50], [25, 5.2, 80],
[45, 5.8, 48], [40, 6.3, 70], [41, 6.4, 90],
[51, 2.3, 111]]
# creating a pandas dataframe
df = pd.DataFrame(values_list, columns=['Field_1', 'Field_2', 'Field_3'],
index=['a', 'b', 'c', 'd', 'e', 'f', 'g'])
# Apply function numpy.square() to square
# the values of 3 rows only i.e. with row
# index name 'a', 'e' and 'g' only
df = df.apply(lambda x: np.square(x) if x.name in [
'a', 'e', 'g'] else x, axis=1)
# printing dataframe
df
输出 :

在上面的示例中,一个 lambda函数应用于以“a”、“e”和“g”开头的 3 行。
示例 5:将lambda函数同时应用于多列和多行
Python3
# importing pandas and numpylibraries
import pandas as pd
import numpy as np
# creating and initializing a nested list
values_list = [[1.5, 2.5, 10.0], [2.0, 4.5, 5.0], [2.5, 5.2, 8.0],
[4.5, 5.8, 4.8], [4.0, 6.3, 70], [4.1, 6.4, 9.0],
[5.1, 2.3, 11.1]]
# creating a pandas dataframe
df = pd.DataFrame(values_list, columns=['Field_1', 'Field_2', 'Field_3'],
index=['a', 'b', 'c', 'd', 'e', 'f', 'g'])
# Apply function numpy.square() to square
# the values of 2 rows only i.e. with row
# index name 'b' and 'f' only
df = df.apply(lambda x: np.square(x) if x.name in ['b', 'f'] else x, axis=1)
# Applying lambda function to find product of 3 columns
# i.e 'Field_1', 'Field_2' and 'Field_3'
df = df.assign(Product=lambda x: (x['Field_1'] * x['Field_2'] * x['Field_3']))
# printing dataframe
df
输出 :
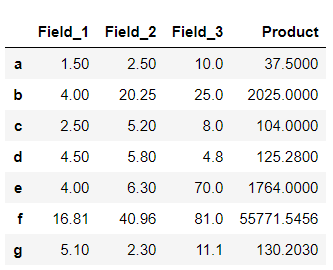
在此示例中,将 lambda函数应用于两行和三列。