单变量优化是非线性优化问题的简单情况,其中无约束的情况没有约束。单变量优化可以定义为无约束的非线性优化,并且在此优化中只有一个决策变量需要我们为其寻找值。
min f(x) such that x ∈ R
在哪里,
f(x)=目标函数
x =决策变量
因此,当您查看此优化问题时,通常会以上述形式编写该代码,即表示要最小化f(x) ,该函数称为目标函数。下面可以将用来最小化此函数的变量(称为决策变量)写为wrt x,如下所示,您还说x是连续的,也就是说它可以在实数行中取任何值。并且由于这是单变量优化问题,因此x是标量变量,而不是矢量变量。
凸函数:
每当我们谈论单变量优化问题时,就很容易在这样的2D图片中将其可视化。

因此,这里我们在x轴上拥有决策变量x的不同值,在y轴上拥有函数值。当您绘制此图形时,您可以很容易地在图形中注意到标记该函数达到其最小值的点。因此,可以通过将垂直线放到x轴上找到该函数达到最小值的点。因此,您可以说x *是该函数取最小值时的x的实际值,并且可以通过将函数垂直于y轴放置来确定函数在其最小点取的值,而f *是此函数可能具有的最佳价值。因此,这种函数称为凸函数,因为这里只有一个最小值。因此,这里没有多个最小值可供选择的问题,这里只有一个最小值,并且在图中进行了标记。因此,在这种情况下,我们可以说此最小值既是局部最小值,也是全局最小值。实际上,我们可以说这是一个局部最小值,因为在这一点附近,这是您可以获得的最佳解决方案。如果我们在这一点附近得到的解决方案也是全局最佳解决方案,那么我们也将其称为全局最小值。
非凸函数:
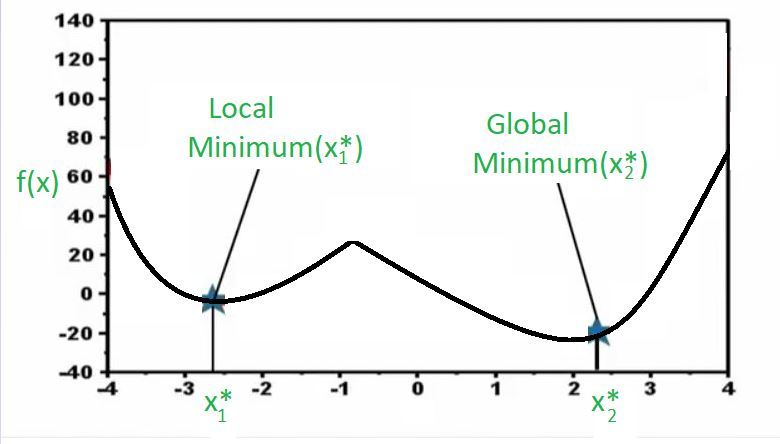
现在,看看上面的图。在这里,我有一个函数,再次它是一个单变量优化问题。因此,在x轴上,我具有不同的决策变量值,在y轴上,我们绘制了函数。现在,您可能会注意到函数有两个点达到最小值,并且您会看到当我们说最小值时,我们实际上实际上仅表示局部最小值,因为如果您注意到图中的x1 *点,则该点附近,从最小化的角度来看,此函数无法获得更好的价值。换句话说,如果我在x1 *处并且函数采用该值,那么如果我向右移动,函数值将增加,这对我们基本上是不利的,因为我们正在尝试寻找最小值,并且如果我移动在我左边,函数值将再次增加,这不好,因为我们正在为此函数找到最小值。这基本上是下面的内容。
这表示在本地附近永远找不到比这更好的点。但是,如果你去远的地方,那么你将得到这一点(X2 *)这里再次从本地角度来看是最好的,因为如果我们在朝着正确的方向去函数增加,如果我们在左方向且函数去增加,并且在这个特定示例中,事实证明,从全球范围来看,这是最好的解决方案。因此,尽管两者都是局部最小值,即在附近它们是最好的,但是此局部最小值(x2 *)也是全局最小值,因为如果您采用整个区域,则仍然无法击败该解决方案。因此,当您拥有整个区域中最低的解决方案时,我们将其称为全局最小值。这些是我们称为非凸函数的函数类型,其中存在多个局部最优解,优化器的工作是从可能的多种最优解中找出最佳解。
为什么这个概念对数据科学很重要?
让我们在这个概念和数据科学之间建立联系。在许多数据科学算法中,找到全局最小值的问题一直是一个实际问题。例如,在20世纪90年代,人们对神经网络充满了兴趣和兴趣,而在过去的几年中,对神经网络进行了大量研究,结果发现,找到全局最优解是非常困难的并且在许多情况下,这些神经网络都经过训练以达到局部最优,对于所要解决的问题类型而言还不够好。因此,这已成为神经网络概念的一个真正的问题,然后在最近几年重新审视了这个问题,现在有了更好的算法,更好的功能形式以及更好的训练策略。这样您就可以实现一些全局最优的概念,这就是为什么我们让这些算法卷土重来并且非常有用的原因。