- 机器学习-分类算法
- 机器学习-分类算法(1)
- 分类算法-决策树
- 分类算法-决策树(1)
- 机器学习中的回归与分类
- C++中的机器学习(1)
- 机器学习 (1)
- 机器学习中的 P 值(1)
- 机器学习中的 P 值
- C++中的机器学习
- 机器学习 python (1)
- R-决策树(1)
- 决策树
- 决策树(1)
- R-决策树
- Scikit学习-决策树(1)
- Scikit学习-决策树
- 机器学习 python 代码示例
- scikit 学习决策树 - Python (1)
- scikit 学习决策树 - Python (1)
- 决策树 - Python (1)
- 机器学习 - 任何代码示例
- scikit 学习决策树 - Python 代码示例
- scikit 学习决策树 - Python 代码示例
- 在机器学习中什么是“i” (1)
- 机器学习-什么是P值(1)
- 机器学习-什么是P值
- 什么是机器学习?
- 什么是机器学习?(1)
📅 最后修改于: 2020-09-28 05:54:25 🧑 作者: Mango
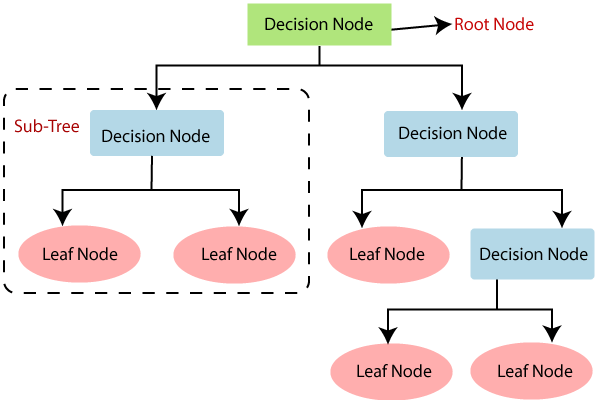
决策树分类算法
- 决策树是一种监督学习技术 ,可用于分类和回归问题,但大多数情况下,它是解决分类问题的首选方法。它是树结构的分类器,其中内部节点代表数据集的特征,分支代表决策规则 , 每个叶节点代表结果。
- 在决策树中,有两个节点,即决策节点和叶节点。决策节点用于做出任何决策,并具有多个分支,而叶子节点是这些决策的输出,并且不包含任何其他分支。
- 根据给定数据集的特征执行决策或测试。
- 它是用于根据给定条件获取问题/决策的所有可能解决方案的图形表示。
- 之所以称为决策树,是因为它与树类似,它始于根节点,该根节点在进一步的分支上扩展并构造树状结构。
- 为了构建树,我们使用CART算法,该算法代表“ 分类和回归树”算法。
- 决策树只是问一个问题,然后根据答案(是/否)将决策树进一步分解为子树。
- 下图说明了决策树的一般结构:
注意:决策树可以包含分类数据(YES / NO)和数字数据。
为什么要使用决策树?
机器学习中有多种算法,因此在创建机器学习模型时要记住的重点是为给定的数据集和问题选择最佳算法。以下是使用决策树的两个原因:
- 决策树通常在做出决策时会模仿人类的思维能力,因此很容易理解。
- 决策树背后的逻辑很容易理解,因为它显示出树状结构。
决策树术语
决策树算法如何工作?
在决策树中,为了预测给定数据集的类别,算法从树的根节点开始。该算法将根属性的值与记录(真实数据集)属性进行比较,并根据比较结果跟随分支并跳转到下一个节点。
对于下一个节点,该算法再次将属性值与其他子节点进行比较,并进一步移动。它继续该过程,直到到达树的叶节点为止。使用以下算法可以更好地理解整个过程:
- 步骤1:以树的根节点开始,S表示,它包含完整的数据集。
- 步骤2:使用属性选择度量(ASM)在数据集中找到最佳属性。
- 步骤3:将S分为子集,其中包含最佳属性的可能值。
- 步骤4:生成决策树节点,其中包含最佳属性。
- 步骤5:使用在步骤-3中创建的数据集的子集,递归地创建新的决策树。继续此过程,直到到达无法进一步对节点进行分类的阶段,并将最终节点称为叶节点。
示例:假设某候选人有工作机会,并且想要决定是否应接受该工作机会。因此,为解决此问题,决策树从根节点开始(ASM的Salal属性)。根节点根据相应的标签进一步分为下一个决策节点(与办公室的距离)和一个叶节点。下一个决策节点进一步分为一个决策节点(Cab设备)和一个叶子节点。最后,决策节点分为两个叶节点(接受要约和拒绝要约)。考虑下图:

属性选择措施
在实施决策树时,主要问题是如何为根节点和子节点选择最佳属性。因此,为了解决这些问题,存在一种称为属性选择度量或ASM的技术。通过这种测量,我们可以轻松地为树的节点选择最佳属性。 ASM有两种流行的技术,它们是:
- 信息增益
- 基尼指数
1.信息获取:
- 信息增益是对基于属性的数据集进行分割后熵变化的度量。
- 它计算功能为类提供的信息量。
- 根据信息增益的值,我们拆分节点并构建决策树。
- 决策树算法总是试图使信息增益的值最大化,并且首先分割具有最高信息增益的节点/属性。可以使用以下公式计算:
Information Gain= Entropy(S)- [(Weighted Avg) *Entropy(each feature)
熵:熵是度量给定属性中的杂质的度量。它指定数据的随机性。熵可以计算为:
哪里,
- S =样本总数
- P(是)=是的概率
- P(no)=否的概率
2.基尼系数:
- 基尼系数是在CART(分类和回归树)算法中创建决策树时使用的杂质或纯度的度量。
- 与高基尼系数相比,低基尼系数的属性应该是首选。
- 它仅创建二进制拆分,并且CART算法使用Gini索引创建二进制拆分。
- 基尼系数可以使用以下公式计算:
修剪:获取最佳决策树
修剪是从树中删除不必要的节点以便获得最佳决策树的过程。
太大的树会增加过度拟合的风险,而小的树可能无法捕获数据集的所有重要特征。因此,在不降低精度的情况下减小学习树的大小的技术被称为修剪。主要使用两种类型的树木修剪技术:
- 成本复杂度修剪
- 减少错误修剪。
决策树的优势
- 很容易理解,因为它遵循人类在现实生活中做出任何决定时遵循的相同过程。
- 这对于解决与决策相关的问题非常有用。
- 它有助于考虑问题的所有可能结果。
- 与其他算法相比,对数据清理的需求更少。
决策树的缺点
- 决策树包含许多层,这使其变得复杂。
- 它可能存在过拟合问题,可以使用随机森林算法解决。
- 对于更多的类别标签,决策树的计算复杂度可能会增加。
决策树的Python实现
现在,我们将使用Python实现决策树。为此,我们将使用先前分类模型中使用的数据集“ user_data.csv”。通过使用相同的数据集,我们可以将决策树分类器与其他分类模型(例如KNN SVM,LogisticRegression等)进行比较。
步骤也将保持不变,如下所示:
- 数据预处理步骤
- 将决策树算法拟合到训练集
- 预测测试结果
- 测试结果的准确性(创建混淆矩阵)
- 可视化测试集结果。
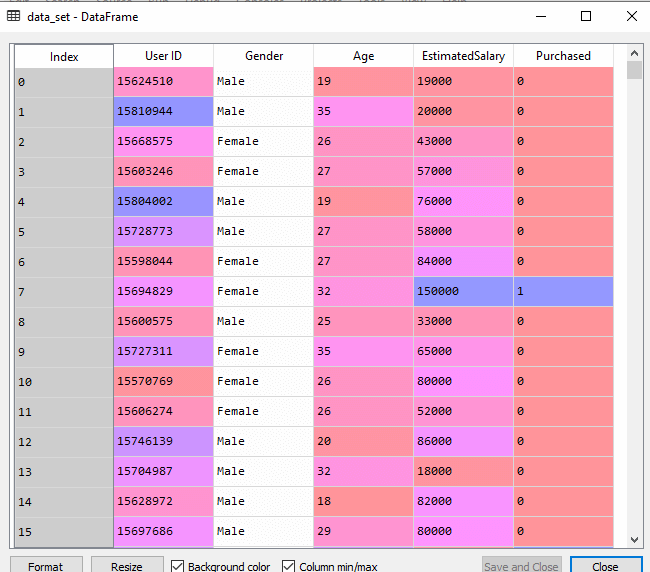
1.数据预处理步骤:
以下是预处理步骤的代码:
# importing libraries
import numpy as nm
import matplotlib.pyplot as mtp
import pandas as pd
#importing datasets
data_set= pd.read_csv('user_data.csv')
#Extracting Independent and dependent Variable
x= data_set.iloc[:, [2,3]].values
y= data_set.iloc[:, 4].values
# Splitting the dataset into training and test set.
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0.25, random_state=0)
#feature Scaling
from sklearn.preprocessing import StandardScaler
st_x= StandardScaler()
x_train= st_x.fit_transform(x_train)
x_test= st_x.transform(x_test)
在上面的代码中,我们已经对数据进行了预处理。加载数据集的位置,其表示为:
2.使决策树算法适合训练集
现在,我们将模型拟合到训练集。为此,我们将从sklearn.tree库导入DecisionTreeClassifier类。下面是它的代码:
#Fitting Decision Tree classifier to the training set
From sklearn.tree import DecisionTreeClassifier
classifier= DecisionTreeClassifier(criterion='entropy', random_state=0)
classifier.fit(x_train, y_train)
在上面的代码中,我们创建了一个分类器对象,在其中传递了两个主要参数:
- “标准=’熵”:标准用于衡量拆分质量,该质量由熵给出的信息增益计算得出。
- random_state = 0“:用于生成随机状态。
以下是此输出:
Out[8]:
DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False,
random_state=0, splitter='best')
3.预测测试结果
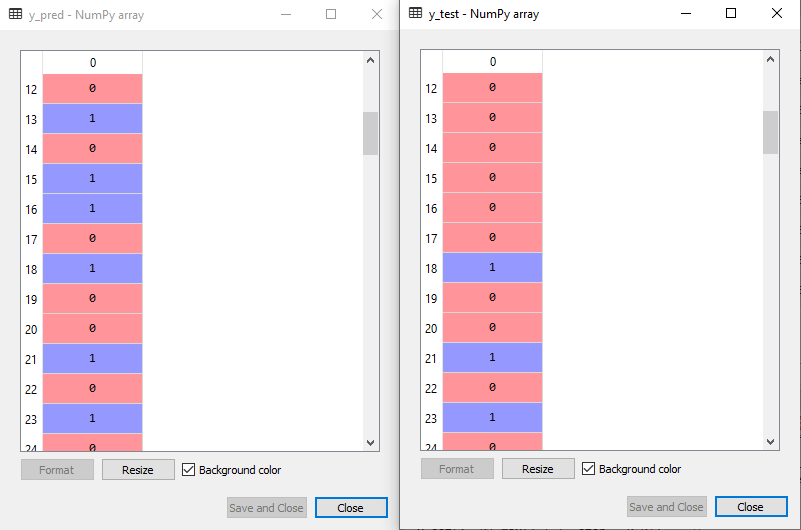
现在我们将预测测试集的结果。我们将创建一个新的预测向量y_pred。下面是它的代码:
#Predicting the test set result
y_pred= classifier.predict(x_test)
输出:
在下面的输出图像中,给出了预测输出和实际测试输出。我们可以清楚地看到,预测向量中存在一些与实际向量值不同的值。这些是预测错误。
4.测试结果的准确性(创建混淆矩阵)
在上面的输出中,我们看到了一些不正确的预测,因此,如果我们想知道正确和不正确的预测的数量,则需要使用混淆矩阵。下面是它的代码:
#Creating the Confusion matrix
from sklearn.metrics import confusion_matrix
cm= confusion_matrix(y_test, y_pred)
输出:
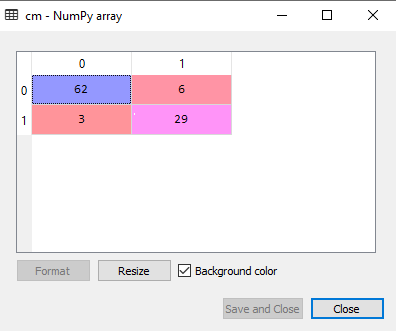
在上面的输出图像中,我们可以看到混淆矩阵,该矩阵具有6 + 3 = 9个错误的预测和62 + 29 = 91个正确的预测。因此,可以说与其他分类模型相比,决策树分类器做出了很好的预测。
5.可视化训练集结果:
在这里,我们将可视化训练集结果。为了可视化训练集结果,我们将为决策树分类器绘制图形。分类器将为购买或未购买SUV汽车的用户预测是或否,就像我们在Logistic回归中所做的那样。下面是它的代码:
#Visulaizing the trianing set result
from matplotlib.colors import ListedColormap
x_set, y_set = x_train, y_train
x1, x2 = nm.meshgrid(nm.arange(start = x_set[:, 0].min() - 1, stop = x_set[:, 0].max() + 1, step =0.01),
nm.arange(start = x_set[:, 1].min() - 1, stop = x_set[:, 1].max() + 1, step = 0.01))
mtp.contourf(x1, x2, classifier.predict(nm.array([x1.ravel(), x2.ravel()]).T).reshape(x1.shape),
alpha = 0.75, cmap = ListedColormap(('purple','green' )))
mtp.xlim(x1.min(), x1.max())
mtp.ylim(x2.min(), x2.max())
fori, j in enumerate(nm.unique(y_set)):
mtp.scatter(x_set[y_set == j, 0], x_set[y_set == j, 1],
c = ListedColormap(('purple', 'green'))(i), label = j)
mtp.title('Decision Tree Algorithm (Training set)')
mtp.xlabel('Age')
mtp.ylabel('Estimated Salary')
mtp.legend()
mtp.show()
输出:
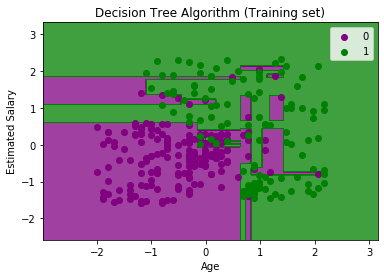
以上输出与其余分类模型完全不同。它具有垂直线和水平线,它们根据年龄和估计的薪水变量划分数据集。
如我们所见,树正试图捕获每个数据集,这是过度拟合的情况。
6.可视化测试集结果:
测试集结果的可视化将类似于训练集的可视化,只是训练集将替换为测试集。
#Visulaizing the test set result
from matplotlib.colors import ListedColormap
x_set, y_set = x_test, y_test
x1, x2 = nm.meshgrid(nm.arange(start = x_set[:, 0].min() - 1, stop = x_set[:, 0].max() + 1, step =0.01),
nm.arange(start = x_set[:, 1].min() - 1, stop = x_set[:, 1].max() + 1, step = 0.01))
mtp.contourf(x1, x2, classifier.predict(nm.array([x1.ravel(), x2.ravel()]).T).reshape(x1.shape),
alpha = 0.75, cmap = ListedColormap(('purple','green' )))
mtp.xlim(x1.min(), x1.max())
mtp.ylim(x2.min(), x2.max())
fori, j in enumerate(nm.unique(y_set)):
mtp.scatter(x_set[y_set == j, 0], x_set[y_set == j, 1],
c = ListedColormap(('purple', 'green'))(i), label = j)
mtp.title('Decision Tree Algorithm(Test set)')
mtp.xlabel('Age')
mtp.ylabel('Estimated Salary')
mtp.legend()
mtp.show()
输出:
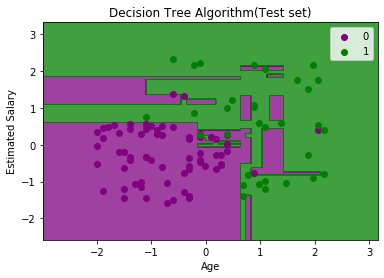
如上图所示,紫色区域中有一些绿色数据点,反之亦然。因此,这些是我们在混淆矩阵中讨论的错误预测。