📌 相关文章
- 回归和分类 |监督机器学习(1)
- 机器学习-分类算法
- 机器学习-分类算法(1)
- 机器学习中的回归分析
- 机器学习中的回归分析(1)
- 回归与分类 (1)
- 机器学习中的逻辑回归
- 机器学习中的逻辑回归(1)
- 机器学习中的线性回归
- 机器学习中的线性回归(1)
- 机器学习-多项式回归
- 机器学习-多项式回归(1)
- 机器学习-决策树分类(1)
- 机器学习-决策树分类
- 机器学习中的 P 值
- C++中的机器学习(1)
- C++中的机器学习
- 机器学习 (1)
- 机器学习中的 P 值(1)
- 回归与分类 - 无论代码示例
- 机器学习中的简单线性回归
- 机器学习中的简单线性回归(1)
- 机器学习 python (1)
- 机器学习 python 代码示例
- 机器学习-多元线性回归
- 机器学习-多元线性回归(1)
- 机器学习 - 任何代码示例
- 在机器学习中什么是“i” (1)
- 机器学习-什么是P值(1)
📜 机器学习中的回归与分类
📅 最后修改于: 2020-09-28 05:47:07 🧑 作者: Mango
机器学习中的回归与分类
回归和分类算法是监督学习算法。两种算法都用于机器学习中的预测并与标记的数据集一起使用。但是两者之间的区别在于它们如何用于不同的机器学习问题。
回归算法和分类算法之间的主要区别在于:回归算法用于预测连续值,例如价格,工资,年龄等;分类算法用于预测/分类离散值,例如,男性或女性,真或假,垃圾邮件或非垃圾邮件等
考虑下图:
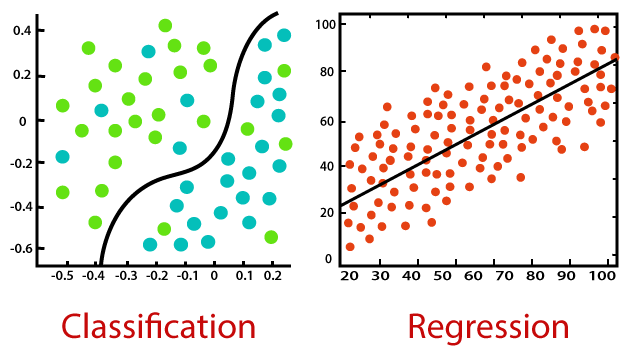
分类:
分类是找到一个函数的过程,该函数有助于根据不同的参数将数据集分为几类。在分类中,在训练数据集上训练计算机程序,并基于该训练将数据分类为不同的类别。
分类算法的任务是找到将输入(x)映射到离散输出(y)的映射函数 。
示例:了解分类问题的最佳示例是电子邮件垃圾邮件检测。该模型基于数百万个具有不同参数的电子邮件进行了训练,并且每当收到新电子邮件时,它都会识别该电子邮件是否为垃圾邮件。如果电子邮件是垃圾邮件,则将其移至“垃圾邮件”文件夹。
ML分类算法的类型:
分类算法可以进一步分为以下几种类型:
- 逻辑回归
- K最近邻居
- 支持向量机
- 内核SVM
- 朴素贝叶斯
- 决策树分类
- 随机森林分类
回归:
回归是寻找因变量和自变量之间的相关性的过程。它有助于预测连续变量,例如预测市场趋势,预测房价等。
回归算法的任务是找到将输入变量(x)映射到连续输出变量(y)的映射函数 。
示例:假设我们要进行天气预报,因此为此,我们将使用回归算法。在天气预报中,该模型是根据过去的数据进行训练的,一旦训练完成,就可以轻松预测未来几天的天气。
回归算法的类型:
- 简单线性回归
- 多元线性回归
- 多项式回归
- 支持向量回归
- 决策树回归
- 森林随机回归
回归与分类之间的区别
| Regression Algorithm | Classification Algorithm |
|---|---|
| 在回归中,输出变量必须是连续的值 | 在分类中,输出变量必须是离散值 |
| 回归算法的任务是将输入值(x)映射到连续输出变量(y) | 分类算法的任务是将输入值(x)映射到离散的输出变量(y) |
| 回归算法主要使用连续的数据 | 分类算法主要使用离散的数据 |
| 在回归分析中,我们试图找到能更准确地预测输出的最佳拟合线 | 在分类中,我们尝试寻找决策边界,以将数据集划分为不同的类 |
| 回归算法可以用来解决天气预报、房价预测等回归问题 | 分类算法可用于解决垃圾邮件识别、语音识别、癌细胞识别等分类问题 |
| 回归算法可以进一步分为线性回归和非线性回归 | 分类算法可分为二元分类器和多类分类器 |