📌 相关文章
- 机器学习算法(1)
- 机器学习算法
- 如何在 Weka 中使用分类机器学习算法?(1)
- 如何在 Weka 中使用分类机器学习算法?
- 机器学习中的回归与分类
- 机器学习-决策树分类(1)
- 机器学习-决策树分类
- 机器学习中的 P 值(1)
- C++中的机器学习(1)
- 机器学习 (1)
- C++中的机器学习
- 机器学习中的 P 值
- 机器学习-Scikit学习算法
- 机器学习-Scikit学习算法(1)
- 算法分类示例
- 算法分类示例(1)
- 算法分类示例(1)
- 算法分类示例
- 算法分类示例(1)
- 算法分类示例(1)
- 算法分类示例
- 算法分类示例
- 算法分类示例
- 机器学习 python (1)
- 分类算法的分类
- 分类算法的分类(1)
- 机器学习 python 代码示例
- 机器学习 - 任何代码示例
- 什么是机器学习?(1)
📜 机器学习-分类算法
📅 最后修改于: 2020-09-27 02:13:22 🧑 作者: Mango
机器学习中的分类算法
众所周知,监督机器学习算法可以大致分为回归算法和分类算法。在回归算法中,我们已经预测了连续值的输出,但是要预测分类值,我们需要分类算法。
什么是分类算法?
分类算法是一种监督学习技术,用于根据训练数据识别新观察的类别。在分类中,程序从给定的数据集或观察值中学习,然后将新观察值分类为多个类或组。例如,是或否,0或1,垃圾邮件或非垃圾邮件,猫或狗等。类可以称为目标/标签或类别。
与回归不同,分类的输出变量是类别,而不是值,例如“绿色或蓝色”,“水果或动物”等。由于分类算法是一种有监督的学习技术,因此它需要标记的输入数据,表示它包含具有相应输出的输入。
在分类算法中,离散输出函数(y)映射到输入变量(x)。
y=f(x), where y = categorical output
机器学习分类算法的最佳示例是电子邮件垃圾邮件检测器。
分类算法的主要目标是识别给定数据集的类别,这些算法主要用于预测分类数据的输出。
使用下图可以更好地理解分类算法。在下图中,有两个类,即A类和B类。这些类具有彼此相似但与其他类不同的功能。
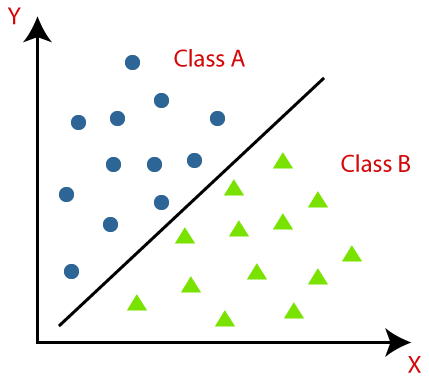
在数据集上实现分类的算法称为分类器。有两种类型的分类:
- 二进制分类器:如果分类问题只有两个可能的结果,则称为二进制分类器。
例如:是或否,男或女,垃圾邮件或非垃圾邮件,CAT或DOG等。 - 多分类器:如果分类问题有两个以上的结果,则称为多分类器。
示例:农作物类型分类,音乐类型分类。
分类问题中的学习者:
在分类问题中,有两种类型的学习者:
- 懒惰学习者:懒惰学习者首先存储训练数据集,然后等待直到接收到测试数据集。在惰性学习者的情况下,分类是基于存储在训练数据集中的最相关数据进行的。培训花费的时间更少,但预测所需的时间却更多。
示例: K-NN算法,基于案例的推理 - 渴望学习者:渴望学习者在接收测试数据集之前,基于训练数据集开发分类模型。与懒惰学习者相反,渴望学习者花费更少的时间进行训练,而花费更多的时间进行预测。 示例:决策树,朴素贝叶斯,人工神经网络。
ML分类算法的类型:
分类算法可以进一步分为两大类:
- 线性模型
- 逻辑回归
- 支持向量机
- 非线性模型
- K最近邻居
- 内核SVM
- 朴素贝叶斯
- 决策树分类
- 随机森林分类
注意:我们将在后面的章节中学习上述算法。
评估分类模型:
模型完成后,有必要评估其性能;它是分类模型或回归模型。因此,为了评估分类模型,我们有以下几种方法:
1.对数损失或交叉熵损失:
- 它用于评估分类器的性能,分类器的输出是介于0和1之间的概率值。
- 对于一个好的二进制分类模型,对数损失的值应接近0。
- 如果预测值偏离实际值,则对数损失的值会增加。
- 对数损失越小,表示模型的准确性越高。
- 对于二元分类,交叉熵可以计算为:
?(ylog(p)+(1?y)log(1?p))
其中y =实际输出,p =预测输出。
2.混淆矩阵:
- 混淆矩阵为我们提供了一个矩阵/表作为输出,并描述了模型的性能。
- 也称为误差矩阵。
- 该矩阵由汇总形式的预测结果组成,该预测结果具有正确预测和错误预测的总数。矩阵如下表所示:
| Actual Positive | Actual Negative | |
|---|---|---|
| Predicted Positive | True Positive | False Positive |
| Predicted Negative | False Negative | True Negative |
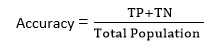
3. AUC-ROC曲线:
- ROC曲线表示接收器工作特性曲线 ,AUC表示曲线下的面积 。
- 该图显示了分类模型在不同阈值下的性能。
- 为了可视化多分类模型的性能,我们使用了AUC-ROC曲线。
- 用TPR和FPR绘制ROC曲线,其中Y轴为TPR(真正率),X轴为FPR(假正率)。
分类算法的用例
分类算法可以在不同的地方使用。以下是分类算法的一些流行用例:
- 电子邮件垃圾邮件检测
- 语音识别
- 癌症肿瘤细胞的鉴定。
- 药品分类
- 生物识别等