R 编程中的多层神经网络
一系列或一组算法试图通过模仿人脑操作的确定过程来识别数据集中的潜在关系,称为神经网络。因此,神经网络可以指人类的神经元,无论是人工的还是有机的。神经网络可以很容易地适应不断变化的输入,以通过网络实现或生成可能的最佳结果,并且不需要重新设计输出标准。
神经网络的类型
神经网络可以根据其层和深度激活过滤器、结构、使用的神经元、神经元密度、数据流等分为多种类型。神经网络的类型如下:
- 感知器
- 多层感知器或多层神经网络
- 前馈神经网络
- 卷积神经网络
- 径向基函数神经网络
- 递归神经网络
- 序列到序列模型
- 模块化神经网络
多层神经网络
准确地说,完全连接的多层神经网络称为多层感知器。多层神经网络由多层人工神经元或节点组成。与单层神经网络不同,近来大多数网络都有多层神经网络。下图是多层神经网络的可视化。
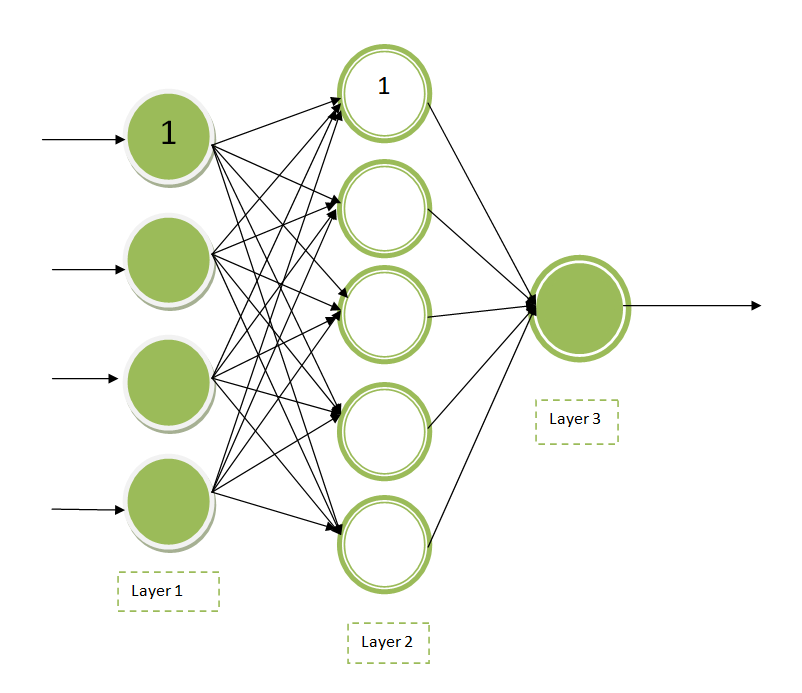
解释:
这里标记为“1”的节点称为偏置单元。最左边的层或第 1 层是输入层,中间层或第 2 层是隐藏层,最右边的层或第 3 层是输出层。可以说上图有3 个输入单元(保留偏置单元)、 1 个输出单元和 3 个隐藏单元。
多层神经网络是前馈神经网络的典型例子。神经元的数量和层数由需要调整的神经网络的超参数组成。为了找到超参数的理想值,必须使用一些交叉验证技术。使用反向传播技术,进行权重调整训练。
多层神经网络公式
假设我们有 x n 个输入(x 1 , x 2 ....x n )和一个偏置单元。让应用的权重为 w 1 , w 2 .....w n。然后找到在输入和权重之间执行点积的求和和偏差单元:
r = Σmi=1 wixi + bias在将 r 输入激活函数F(r) 时,我们找到隐藏层的输出。对于第一个隐藏层 h 1 ,神经元可以计算为:
h11 = F(r)对于所有其他隐藏层,重复相同的过程。不断重复这个过程,直到达到最后一组重量。
在 R 中实现多层神经网络
在 R 语言中,安装神经网络包以研究神经网络的概念。神经网络包需要一个全数字矩阵或数据框。通过提及神经网络()函数的隐藏参数的值来控制隐藏层,该函数可以是许多隐藏层的向量。每次使用set.seed()函数生成随机数。
例子:
使用神经网络包来拟合线性模型。让我们看看在 R 中拟合多层神经网络的步骤。
- 第 1 步:第一步是选择数据集。在此示例中,让我们处理MASS包的波士顿数据集。该数据集通常处理波士顿边缘或郊区的住房价值。目标是通过使用所有其他可用的连续变量来找到其所有者占用的房屋的 medv 或中值。使用set.seed()函数生成随机数。
r
set.seed(500)
library(MASS)
data <- Bostonr
apply(data, 2, function(x) sum(is.na(x)))r
index <- sample(1 : nrow(data),
round(0.75 * nrow(data)))
train <- data[index, ]
test <- data[-index, ]
lm.fit <- glm(medv~., data = train)
summary(lm.fit)
pr.lm <- predict(lm.fit, test)
MSE.lm <- sum((pr.lm - test$medv)^2) / nrow(test)r
maxs <- apply(data, 2, max)
mins <- apply(data, 2, min)
scaled <- as.data.frame(scale(data,
center = mins,
scale = maxs - mins))
train_ <- scaled[index, ]
test_ <- scaled[-index, ]r
library(neuralnet)
n <- names(train_)
f <- as.formula(paste("medv ~",
paste(n[!n %in% "medv"],
collapse = " + ")))
nn <- neuralnet(f,
data = train_,
hidden = c(4, 2),
linear.output = T)r
# R program to illustrate
# Multi Layered Neural Networks
# Use the set.seed() function
# To generate random numbers
set.seed(500)
# Import required library
library(MASS)
# Working on the Boston dataset
data <- Boston
apply(data, 2, function(x) sum(is.na(x)))
index <- sample(1 : nrow(data),
round(0.75 * nrow(data)))
train <- data[index, ]
test <- data[-index, ]
lm.fit <- glm(medv~., data = train)
summary(lm.fit)
pr.lm <- predict(lm.fit, test)
MSE.lm <- sum((pr.lm - test$medv)^2) / nrow(test)
maxs <- apply(data, 2, max)
mins <- apply(data, 2, min)
scaled <- as.data.frame(scale(data,
center = mins,
scale = maxs - mins))
train_ <- scaled[index, ]
test_ <- scaled[-index, ]
# Applying Neural network concepts
library(neuralnet)
n <- names(train_)
f <- as.formula(paste("medv ~",
paste(n[!n %in% "medv"],
collapse = " + ")))
nn <- neuralnet(f, data = train_,
hidden = c(4, 2),
linear.output = T)
# Plotting the graph
plot(nn)- 第 2 步:然后检查数据集中的缺失值或数据点。如果有,则修复丢失的数据点。
r
apply(data, 2, function(x) sum(is.na(x)))
- 输出:
crim zn indus chas nox rm age dis rad tax ptratio black lstat medv
0 0 0 0 0 0 0 0 0 0 0 0 0 0 - 第 3 步:由于没有丢失任何数据点,因此继续准备数据集。现在将数据随机分成两组,训练集和测试集。在准备数据时,尝试将数据拟合到线性回归模型上,然后在测试集上对其进行测试。
r
index <- sample(1 : nrow(data),
round(0.75 * nrow(data)))
train <- data[index, ]
test <- data[-index, ]
lm.fit <- glm(medv~., data = train)
summary(lm.fit)
pr.lm <- predict(lm.fit, test)
MSE.lm <- sum((pr.lm - test$medv)^2) / nrow(test)
- 输出:
Deviance Residuals:
Min 1Q Median 3Q Max
-14.9143 -2.8607 -0.5244 1.5242 25.0004
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 43.469681 6.099347 7.127 5.50e-12 ***
crim -0.105439 0.057095 -1.847 0.065596 .
zn 0.044347 0.015974 2.776 0.005782 **
indus 0.024034 0.071107 0.338 0.735556
chas 2.596028 1.089369 2.383 0.017679 *
nox -22.336623 4.572254 -4.885 1.55e-06 ***
rm 3.538957 0.472374 7.492 5.15e-13 ***
age 0.016976 0.015088 1.125 0.261291
dis -1.570970 0.235280 -6.677 9.07e-11 ***
rad 0.400502 0.085475 4.686 3.94e-06 ***
tax -0.015165 0.004599 -3.297 0.001072 **
ptratio -1.147046 0.155702 -7.367 1.17e-12 ***
black 0.010338 0.003077 3.360 0.000862 ***
lstat -0.524957 0.056899 -9.226 < 2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for gaussian family taken to be 23.26491)
Null deviance: 33642 on 379 degrees of freedom
Residual deviance: 8515 on 366 degrees of freedom
AIC: 2290
Number of Fisher Scoring iterations: 2- 第 4 步:现在在训练神经网络之前对数据集进行归一化。因此,缩放和拆分数据。 scale()函数返回一个需要在数据帧中强制转换的矩阵。
r
maxs <- apply(data, 2, max)
mins <- apply(data, 2, min)
scaled <- as.data.frame(scale(data,
center = mins,
scale = maxs - mins))
train_ <- scaled[index, ]
test_ <- scaled[-index, ]
- 第 5 步:现在将数据拟合到神经网络中。使用神经网络包。
r
library(neuralnet)
n <- names(train_)
f <- as.formula(paste("medv ~",
paste(n[!n %in% "medv"],
collapse = " + ")))
nn <- neuralnet(f,
data = train_,
hidden = c(4, 2),
linear.output = T)
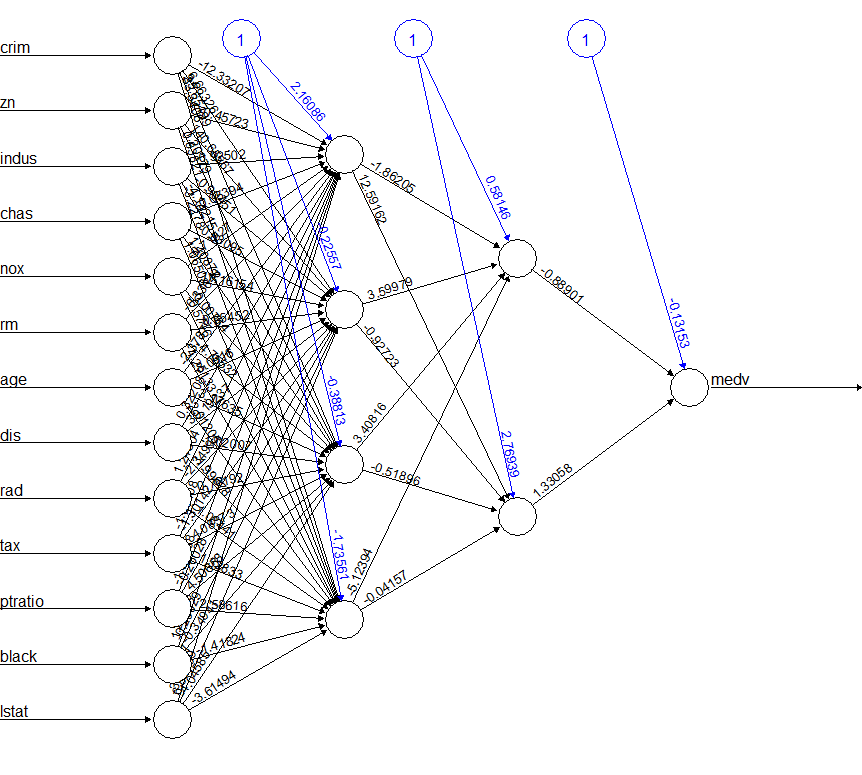
现在我们的模型适合多层神经网络。现在结合所有步骤并绘制神经网络以可视化输出。使用plot()函数来执行此操作。
r
# R program to illustrate
# Multi Layered Neural Networks
# Use the set.seed() function
# To generate random numbers
set.seed(500)
# Import required library
library(MASS)
# Working on the Boston dataset
data <- Boston
apply(data, 2, function(x) sum(is.na(x)))
index <- sample(1 : nrow(data),
round(0.75 * nrow(data)))
train <- data[index, ]
test <- data[-index, ]
lm.fit <- glm(medv~., data = train)
summary(lm.fit)
pr.lm <- predict(lm.fit, test)
MSE.lm <- sum((pr.lm - test$medv)^2) / nrow(test)
maxs <- apply(data, 2, max)
mins <- apply(data, 2, min)
scaled <- as.data.frame(scale(data,
center = mins,
scale = maxs - mins))
train_ <- scaled[index, ]
test_ <- scaled[-index, ]
# Applying Neural network concepts
library(neuralnet)
n <- names(train_)
f <- as.formula(paste("medv ~",
paste(n[!n %in% "medv"],
collapse = " + ")))
nn <- neuralnet(f, data = train_,
hidden = c(4, 2),
linear.output = T)
# Plotting the graph
plot(nn)
输出: