Tensorflow 中的多层感知器学习
在本文中,我们将了解多层感知器的概念及其使用 TensorFlow 库在Python中的实现。
多层感知器
多层感知也称为 MLP。它是完全连接的密集层,可将任何输入维度转换为所需维度。多层感知是具有多层的神经网络。为了创建一个神经网络,我们将神经元组合在一起,使一些神经元的输出成为其他神经元的输入。
可以在这里找到对神经网络和 TensorFlow的简要介绍:
- 神经网络
- TensorFlow 简介
多层感知器有一个输入层,对于每个输入,有一个神经元(或节点),它有一个输出层,每个输出有一个节点,它可以有任意数量的隐藏层,每个隐藏层可以有任意数量的节点。多层感知器 (MLP) 的示意图如下所示。
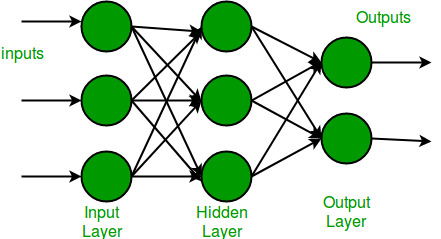
在上面的多层感知器图中,我们可以看到有三个输入,因此三个输入节点,隐藏层有三个节点。输出层给出两个输出,因此有两个输出节点。输入层中的节点接受输入并转发它以进行进一步处理,在上图中,输入层中的节点将其输出转发到隐藏层中的三个节点中的每一个,同样的方式,隐藏层处理信息并将其传递给输出层。
多层感知中的每个节点都使用一个 sigmoid 激活函数。 sigmoid 激活函数将实数值作为输入,并使用 sigmoid 公式将它们转换为 0 到 1 之间的数字。

现在我们已经完成了多层感知的理论部分,让我们继续使用TensorFlow库在Python中实现一些代码。
逐步实施
第 1 步:导入必要的库。
Python3
# importing modules
import tensorflow as tf
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Activation
import matplotlib.pyplot as pltPython3
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()Python3
# Cast the records into float values
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
# normalize image pixel values by dividing
# by 255
gray_scale = 255
x_train /= gray_scale
x_test /= gray_scalePython3
print("Feature matrix:", x_train.shape)
print("Target matrix:", x_test.shape)
print("Feature matrix:", y_train.shape)
print("Target matrix:", y_test.shape)Python3
fig, ax = plt.subplots(10, 10)
k = 0
for i in range(10):
for j in range(10):
ax[i][j].imshow(x_train[k].reshape(28, 28),
aspect='auto')
k += 1
plt.show()Python3
model = Sequential([
# reshape 28 row * 28 column data to 28*28 rows
Flatten(input_shape=(28, 28)),
# dense layer 1
Dense(256, activation='sigmoid'),
# dense layer 2
Dense(128, activation='sigmoid'),
# output layer
Dense(10, activation='sigmoid'),
])Python
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])Python3
model.fit(x_train, y_train, epochs=10,
batch_size=2000,
validation_split=0.2)Python3
results = model.evaluate(x_test, y_test, verbose = 0)
print('test loss, test acc:', results)第 2 步:下载数据集。
TensorFlow 允许我们读取 MNIST 数据集,我们可以将其作为训练和测试数据集直接加载到程序中。
Python3
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
输出:
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz
11493376/11490434 [==============================] – 2s 0us/step
第 3 步:现在我们将像素转换为浮点值。
Python3
# Cast the records into float values
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
# normalize image pixel values by dividing
# by 255
gray_scale = 255
x_train /= gray_scale
x_test /= gray_scale
我们正在将像素值转换为浮点值以进行预测。将数字更改为灰度值将是有益的,因为值变小并且计算变得更容易和更快。由于像素值的范围是 0 到 256,除 0 外,范围是 255。因此将所有值除以 255 会将其转换为 0 到 1 的范围
第 4 步:了解数据集的结构
Python3
print("Feature matrix:", x_train.shape)
print("Target matrix:", x_test.shape)
print("Feature matrix:", y_train.shape)
print("Target matrix:", y_test.shape)
输出:
Feature matrix: (60000, 28, 28)
Target matrix: (10000, 28, 28)
Feature matrix: (60000,)
Target matrix: (10000,)因此,我们得到训练数据集中有 60,000 条记录,测试数据集中有 10,000 条记录,并且数据集中的每个图像的大小为 28×28。
第 5 步:可视化数据。
Python3
fig, ax = plt.subplots(10, 10)
k = 0
for i in range(10):
for j in range(10):
ax[i][j].imshow(x_train[k].reshape(28, 28),
aspect='auto')
k += 1
plt.show()
输出

第 6 步:形成输入、隐藏和输出层。
Python3
model = Sequential([
# reshape 28 row * 28 column data to 28*28 rows
Flatten(input_shape=(28, 28)),
# dense layer 1
Dense(256, activation='sigmoid'),
# dense layer 2
Dense(128, activation='sigmoid'),
# output layer
Dense(10, activation='sigmoid'),
])
需要注意的一些要点:
- Sequential 模型允许我们根据需要在多层感知器中逐层创建模型,并且仅限于单输入、单输出的层堆栈。
- Flatten在不影响批量大小的情况下展平提供的输入。例如,如果输入的形状为 (batch_size,) 而没有特征轴,则展平会增加一个额外的通道维度,输出形状为 (batch_size, 1)。
- Activation用于使用 sigmoid 激活函数。
- 前两个Dense层用于制作全连接模型,是隐藏层。
- 最后一个 Dense 层是包含 10 个神经元的输出层,这些神经元决定图像属于哪个类别。
第 7 步:编译模型。
Python
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
此处使用的编译函数涉及损失、优化器和指标的使用。这里使用的损失函数是sparse_categorical_crossentropy ,使用的优化器是adam 。
第 8 步:拟合模型。
Python3
model.fit(x_train, y_train, epochs=10,
batch_size=2000,
validation_split=0.2)
输出:

需要注意的一些要点:
- 时期告诉我们模型将在前向和后向传递中训练的次数。
- Batch Size表示样本的数量,如果未指定,batch_size 将默认为 32。
- Validation Split是一个介于 0 和 1 之间的浮点值。模型将把这部分训练数据分开,以在每个 epoch 结束时评估损失和任何模型指标。 (模型不会在此数据上进行训练)
第 9 步:找到模型的准确度。
Python3
results = model.evaluate(x_test, y_test, verbose = 0)
print('test loss, test acc:', results)
输出:
test loss, test acc: [0.27210235595703125, 0.9223999977111816]通过在测试样本上使用model.evaluate() ,我们得到了 92% 的模型准确率。