在 Pandas 中创建管道
管道在转换和处理大量数据方面发挥着有用的作用。管道 是一系列数据处理机制。 Pandas 管道功能允许我们将各种用户定义的Python函数字符串在一起,以构建数据处理管道。在 Pandas 中有两种创建管道的方法。通过调用.pipe()函数并导入pdpipe包。
通过pandas管道函数,即pipe()函数,我们可以一次在一行中调用多个函数进行数据处理。让我们使用 pipe()函数来理解和创建管道。
下面是描述如何使用 Pandas 创建管道的各种示例。
示例 1:
Python3
# importing pandas library
import pandas as pd
# Create empty dataframe
df = pd.DataFrame()
# Creating a simple dataframe
df['name'] = ['Reema', 'Shyam', 'Jai',
'Nimisha', 'Rohit', 'Riya']
df['gender'] = ['Female', 'Male', 'Male',
'Female', 'Male', 'Female']
df['age'] = [31, 32, 19, 23, 28, 33]
# View dataframe
dfPython3
# function to find maen
def mean_age_by_group(dataframe, col):
# groups the data by a column and
# returns the mean age per group
return dataframe.groupby(col).mean()
# function to convert to uppercase
def uppercase_column_name(dataframe):
# Converts all the column names into uppercase
dataframe.columns = dataframe.columns.str.upper()
# And returns them
return dataframePython3
# Create a pipeline that applies both the functions created above
pipeline = df.pipe(mean_age_by_group, col='gender').pipe(uppercase_column_name)
# calling pipeline
pipelinePython3
# importing the package
import pdpipe as pdp
import pandas as pd
# creating a emplty dataframe named dataset
dataset = pd.DataFrame()
# Creating a simple dataframe
dataset['name'] = ['Reema', 'Shyam', 'Jai',
'Nimisha', 'Rohit', 'Riya']
dataset['gender'] = ['Female', 'Male', 'Male',
'Female', 'Male', 'Female']
dataset['age'] = [31, 32, 19, 23, 28, 33]
dataset['department'] = ['Accounts', 'Management',
'IT', 'IT', 'Management',
'Advertising']
dataset['index'] = [1, 2, 3, 4, 5, 6]
# View dataframe
datasetPython3
# creating a pipeline and
# droping the umwanted column
dropCol = pdp.ColDrop("index").apply(dataset)
# display the new dataframe
# after column drop
dropColPython3
# creating a pipeline and
# droping the umwanted column
dropCol2 = pdp.ColDrop("index")
# applying the ColDrop to dataframe
df2 = dropCol2(dataset)
# display dataframe
df2Python3
# importing the package
import pdpipe as pdp
import pandas as pd
# function to assign
# senior and junior in post
def fun(x):
if x > 30:
return "Senior"
else:
return "Junior"
# creating a emplty dataframe named dataset
dataset = pd.DataFrame()
# Creating a simple dataframe
dataset['name'] = ['Reema', 'Shyam', 'Jai',
'Nimisha', 'Rohit', 'Riya']
dataset['gender'] = ['Female', 'Male', 'Male',
'Female', 'Male', 'Female']
dataset['age'] = [31, 32, 19, 23, 28, 33]
dataset['department'] = ['Accounts', 'Management',
'IT', 'IT', 'Management',
'Advertising']
dataset['index'] = [1, 2, 3, 4, 5, 6]
# creating new column
# comparing with another column
# and applying the function
dataset['post'] = dataset['age'].apply(fun)
# display dataframe
datasetPython3
#droping the valus using ValDrop
df3 = pdp.ValDrop(['IT'],'department').apply(dataset)
#display dataframe
df3输出:
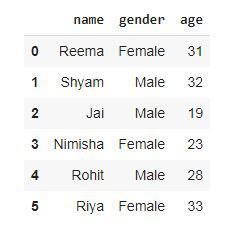
现在,创建用于数据处理的函数。
蟒蛇3
# function to find maen
def mean_age_by_group(dataframe, col):
# groups the data by a column and
# returns the mean age per group
return dataframe.groupby(col).mean()
# function to convert to uppercase
def uppercase_column_name(dataframe):
# Converts all the column names into uppercase
dataframe.columns = dataframe.columns.str.upper()
# And returns them
return dataframe
现在,使用 .pipe()函数创建管道。
蟒蛇3
# Create a pipeline that applies both the functions created above
pipeline = df.pipe(mean_age_by_group, col='gender').pipe(uppercase_column_name)
# calling pipeline
pipeline
输出:
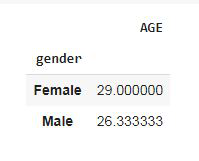
现在,让我们通过导入pdpipe包来理解和创建管道。
pdpipe Python包提供了一个简洁的界面,用于构建具有先决条件的 Pandas 管道。 pdpipe 是 Python 的 panda 数据帧的预处理管道包。 pdpipe API 有助于使用几行代码轻松分解或组合复杂的熊猫处理管道。
我们可以通过简单地编写来安装这个包:
pip install pdpipe示例 2:
蟒蛇3
# importing the package
import pdpipe as pdp
import pandas as pd
# creating a emplty dataframe named dataset
dataset = pd.DataFrame()
# Creating a simple dataframe
dataset['name'] = ['Reema', 'Shyam', 'Jai',
'Nimisha', 'Rohit', 'Riya']
dataset['gender'] = ['Female', 'Male', 'Male',
'Female', 'Male', 'Female']
dataset['age'] = [31, 32, 19, 23, 28, 33]
dataset['department'] = ['Accounts', 'Management',
'IT', 'IT', 'Management',
'Advertising']
dataset['index'] = [1, 2, 3, 4, 5, 6]
# View dataframe
dataset
输出:
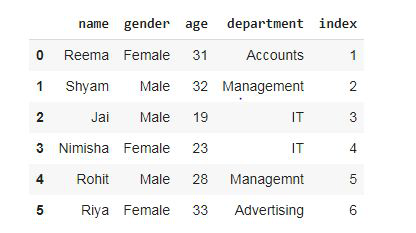
使用 pdpipe 从数据框中删除列。
蟒蛇3
# creating a pipeline and
# droping the umwanted column
dropCol = pdp.ColDrop("index").apply(dataset)
# display the new dataframe
# after column drop
dropCol
输出:
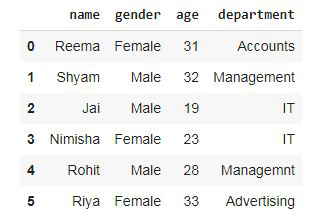
还有另一种通过 pdpipe 删除列的方法。
蟒蛇3
# creating a pipeline and
# droping the umwanted column
dropCol2 = pdp.ColDrop("index")
# applying the ColDrop to dataframe
df2 = dropCol2(dataset)
# display dataframe
df2
输出:
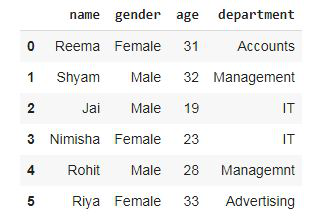
在这里,分两步放下列。在第一步中,我们创建了一个管道,在第二步中,我们将其应用于数据帧。
示例 3:
现在我们使用 pdpipe 向数据框添加一列。
蟒蛇3
# importing the package
import pdpipe as pdp
import pandas as pd
# function to assign
# senior and junior in post
def fun(x):
if x > 30:
return "Senior"
else:
return "Junior"
# creating a emplty dataframe named dataset
dataset = pd.DataFrame()
# Creating a simple dataframe
dataset['name'] = ['Reema', 'Shyam', 'Jai',
'Nimisha', 'Rohit', 'Riya']
dataset['gender'] = ['Female', 'Male', 'Male',
'Female', 'Male', 'Female']
dataset['age'] = [31, 32, 19, 23, 28, 33]
dataset['department'] = ['Accounts', 'Management',
'IT', 'IT', 'Management',
'Advertising']
dataset['index'] = [1, 2, 3, 4, 5, 6]
# creating new column
# comparing with another column
# and applying the function
dataset['post'] = dataset['age'].apply(fun)
# display dataframe
dataset
输出:
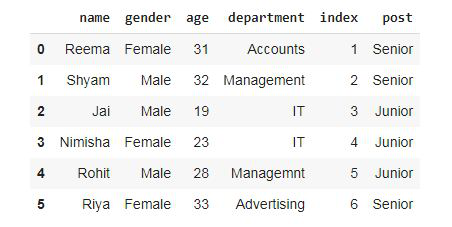
现在,从数据框中删除值。
蟒蛇3
#droping the valus using ValDrop
df3 = pdp.ValDrop(['IT'],'department').apply(dataset)
#display dataframe
df3
输出:
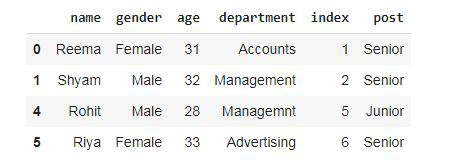
包含“ IT ”值的行被删除。