如何使用 Youtube API 提取 YouTube 评论 – Python
先决条件: YouTube API
Google 提供了大量 API 供开发人员选择。 Google 提供的每项服务都有一个关联的 API。作为其中之一,YouTube 数据 API 使用起来非常简单,可提供以下功能:
- 搜索视频
- 处理视频,例如检索有关视频的信息、插入视频、删除视频等。
- 处理订阅,例如列出所有订阅、插入或删除订阅等。
在本文中,我们将讨论如何在Python中使用 Google YouTube API 提取 YouTube 评论和回复。
了解逐步实施:-
- 检索 YouTube 视频结果
- 这里我们将使用commentThreads、list、execute方法,它会给出评论和回复的列表
- 在列表方法中,在part属性中传递片段和回复,在videoId属性中传递视频 URL 的视频 ID
Python3
# creating youtube resource object
youtube = build('youtube','v3',
developerKey="Enter API Key")
# retrieve youtube video results
video_response=youtube.commentThreads().list(
part='snippet,replies',
videoId="Enter Video ID"
).execute()Python3
from googleapiclient.discovery import build
api_key = 'API KEY'
def video_comments(video_id):
# empty list for storing reply
replies = []
# creating youtube resource object
youtube = build('youtube', 'v3',
developerKey=api_key)
# retrieve youtube video results
video_response=youtube.commentThreads().list(
part='snippet,replies',
videoId=video_id
).execute()
# iterate video response
while video_response:
# extracting required info
# from each result object
for item in video_response['items']:
# Extracting comments
comment = item['snippet']['topLevelComment']['snippet']['textDisplay']
# counting number of reply of comment
replycount = item['snippet']['totalReplyCount']
# if reply is there
if replycount>0:
# iterate through all reply
for reply in item['replies']['comments']:
# Extract reply
reply = reply['snippet']['textDisplay']
# Store reply is list
replies.append(reply)
# print comment with list of reply
print(comment, replies, end = '\n\n')
# empty reply list
replies = []
# Again repeat
if 'nextPageToken' in video_response:
video_response = youtube.commentThreads().list(
part = 'snippet,replies',
videoId = video_id
).execute()
else:
break
# Enter video id
video_id = "Enter Video ID"
# Call function
video_comments(video_id)- 遍历每个视频响应并获取评论和回复
- 数据采用字典格式,每条评论数据都有回复计数,如果回复计数为零表示没有回复该评论
- 如果计数大于零,那么我们将迭代每个回复并获取文本。
- nextPageToken包含下一个数据,这里我们检查 nextPageToken 是否没有值,这意味着值为 None,循环结束,否则循环将继续。
下面是完整的实现:
蟒蛇3
from googleapiclient.discovery import build
api_key = 'API KEY'
def video_comments(video_id):
# empty list for storing reply
replies = []
# creating youtube resource object
youtube = build('youtube', 'v3',
developerKey=api_key)
# retrieve youtube video results
video_response=youtube.commentThreads().list(
part='snippet,replies',
videoId=video_id
).execute()
# iterate video response
while video_response:
# extracting required info
# from each result object
for item in video_response['items']:
# Extracting comments
comment = item['snippet']['topLevelComment']['snippet']['textDisplay']
# counting number of reply of comment
replycount = item['snippet']['totalReplyCount']
# if reply is there
if replycount>0:
# iterate through all reply
for reply in item['replies']['comments']:
# Extract reply
reply = reply['snippet']['textDisplay']
# Store reply is list
replies.append(reply)
# print comment with list of reply
print(comment, replies, end = '\n\n')
# empty reply list
replies = []
# Again repeat
if 'nextPageToken' in video_response:
video_response = youtube.commentThreads().list(
part = 'snippet,replies',
videoId = video_id
).execute()
else:
break
# Enter video id
video_id = "Enter Video ID"
# Call function
video_comments(video_id)
输出:

我们来验证一下结果:
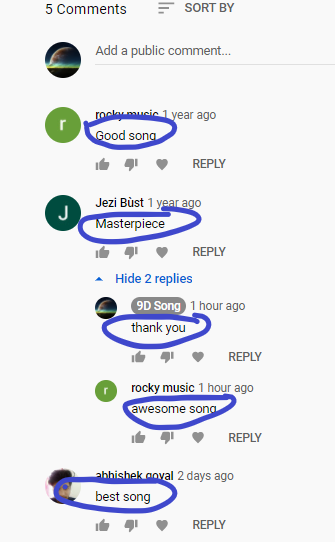
3 条评论和 2 条回复