目标检测 vs 目标识别 vs 图像分割
对象识别:
对象识别是识别图像和视频中存在的对象的技术。它是机器学习和深度学习最重要的应用之一。该领域的目标是教机器像人类一样理解(识别)图像的内容。

使用机器学习的对象识别
- HOG(Histogram of orientation Gradients)特征提取器和SVM(支持向量机)模型:在深度学习时代之前,它是一种最先进的目标检测方法。它采用正样本(包含对象的图像)和负样本(不包含对象的图像)的直方图描述符,并以此训练我们的 SVM 模型。
- 特征袋模型:就像词袋将文档视为词的无序集合一样,这种方法也将图像表示为图像特征的无序集合。这方面的例子是 SIFT、MSER 等。
- Viola-Jones 算法:该算法广泛用于图像中或实时的人脸检测。它从图像中执行类似 Haar 的特征提取。这会产生大量的特征。然后将这些特征传递到提升分类器中。这会生成一个级联的增强分类器来执行图像检测。图像需要传递给每个分类器以生成正面(找到人脸)结果。 Viola-Jones 的优势在于其检测时间为 2 fps,可用于实时人脸识别系统。
使用深度学习的对象识别
卷积神经网络 (CNN) 是最流行的对象识别方法之一。它被广泛使用,并且大多数最先进的神经网络都将这种方法用于各种与对象识别相关的任务,例如图像分类。这个 CNN 网络将图像作为输入并输出不同类别的概率。如果图像中存在对象,则其输出概率很高,否则其余类的输出概率可以忽略不计或很低。深度学习的优势在于,与机器学习相比,我们不需要从数据中提取特征。 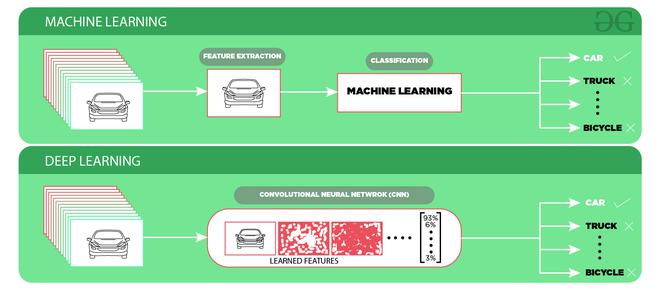
物体识别的挑战:
- 由于我们将 CNN 模型的最后(全连接)层生成的输出作为单个类标签。因此,如果图像中存在多个类标签,那么简单的 CNN 方法将不起作用。
- 如果我们想定位边界框中对象的存在,我们需要尝试不同的方法,不仅输出类标签,还输出边界框位置。

图像分类:
在图像分类中,它将图像作为输入并输出具有某种度量(概率、损失、准确度等)的图像的分类标签。例如:猫的图像可以归类为类标签“猫”,或者狗的图像可以按一定概率归类为类标签“狗”。

对象定位:该算法定位图像中对象的存在,并用边界框表示它。它以图像为输入,以(位置、高度和宽度)的形式输出边界框的位置。
物体检测:
对象检测算法作为图像分类和对象定位的组合。它将图像作为输入并生成一个或多个边界框,每个边界框都带有类标签。这些算法足以处理多类分类和定位以及处理多次出现的对象。
目标检测的挑战:
- 在目标检测中,边界框总是矩形的。因此,如果对象包含曲率部分,则它无助于确定对象的形状。
- 物体检测无法准确估计一些测量值,例如物体的面积、物体的周长等。

图像分割:
图像分割是对象检测的进一步扩展,其中我们通过为图像中的每个对象生成的像素级掩码来标记对象的存在。这种技术比边界框生成更精细,因为这可以帮助我们确定图像中每个对象的形状。这种粒度有助于我们在医学图像处理、卫星成像等各个领域。最近提出了许多图像分割方法。最受欢迎的一种是 K He 等人提出的 Mask R-CNN。在 2017 年。

主要有两种类型的细分:
- 实例分割:识别对象的边界并用不同的颜色标记它们的像素。
- 语义分割:根据类别类别或类别标签,用不同颜色标记图像(包括背景)中的每个像素。

应用:
上面讨论的对象识别技术可用于许多领域,例如:
- 无人驾驶汽车:物体识别用于检测道路标志、其他车辆等。
- 医学图像处理:对象识别和图像处理技术可以帮助更准确地检测疾病。例如,用于乳腺癌检测的谷歌人工智能比医生检测更准确。
- 监控和安全:如人脸识别、物体跟踪、活动识别等。
参考:
- Ross Girshick 的 RCNN 论文
- Mathworks 对象识别与对象检测
- CS231n 斯坦福幻灯片