PySpark – 将数据帧拆分为相同数量的行
当有一个巨大的数据集时,最好将它们分成相等的块,然后单独处理每个数据帧。如果数据帧上的操作与行无关,则这是可能的。然后可以并行处理每个块或等分数据帧,从而更有效地利用资源。在本文中,我们将讨论如何将 PySpark 数据帧拆分为相等数量的行。
创建用于演示的数据框:
Python
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# Column names for the dataframe
columns = ["Brand", "Product"]
# Row data for the dataframe
data = [
("HP", "Laptop"),
("Lenovo", "Mouse"),
("Dell", "Keyboard"),
("Samsung", "Monitor"),
("MSI", "Graphics Card"),
("Asus", "Motherboard"),
("Gigabyte", "Motherboard"),
("Zebronics", "Cabinet"),
("Adata", "RAM"),
("Transcend", "SSD"),
("Kingston", "HDD"),
("Toshiba", "DVD Writer")
]
# Create the dataframe using the above values
prod_df = spark.createDataFrame(data=data,
schema=columns)
# View the dataframe
prod_df.show()Python
# Define the number of splits you want
n_splits = 4
# Calculate count of each dataframe rows
each_len = prod_df.count() // n_splits
# Create a copy of original dataframe
copy_df = prod_df
# Iterate for each dataframe
i = 0
while i < n_splits:
# Get the top `each_len` number of rows
temp_df = copy_df.limit(each_len)
# Truncate the `copy_df` to remove
# the contents fetched for `temp_df`
copy_df = copy_df.subtract(temp_df)
# View the dataframe
temp_df.show(truncate=False)
# Increment the split number
i += 1Python
# Define the number of splits you want
from pyspark.sql.types import StructType, StructField, StringType
from pyspark.sql.functions import concat, col, lit
n_splits = 4
# Calculate count of each dataframe rows
each_len = prod_df.count() // n_splits
# Create a copy of original dataframe
copy_df = prod_df
# Function to modify columns of each individual split
def modify_dataframe(data):
return data.select(
concat(col("Brand"), lit(" - "),
col("Product"))
)
# Create an empty dataframe to
# store concatenated results
schema = StructType([
StructField('Brand - Product', StringType(), True)
])
result_df = spark.createDataFrame(data=[],
schema=schema)
# Iterate for each dataframe
i = 0
while i < n_splits:
# Get the top `each_len` number of rows
temp_df = copy_df.limit(each_len)
# Truncate the `copy_df` to remove
# the contents fetched for `temp_df`
copy_df = copy_df.subtract(temp_df)
# Perform operation on the newly created dataframe
temp_df_mod = modify_dataframe(data=temp_df)
temp_df_mod.show(truncate=False)
# Concat the dataframe
result_df = result_df.union(temp_df_mod)
# Increment the split number
i += 1
result_df.show(truncate=False)输出:

在上面的代码块中,我们为数据帧定义了模式结构并提供了示例数据。我们的数据框由 2 个字符串类型的列组成,其中包含 12 条记录。
示例 1:使用“DataFrame.limit()”拆分数据帧
我们将使用 split() 方法来创建“n”个相等的数据帧。
Syntax: DataFrame.limit(num)
Where, Limits the result count to the number specified.
代码:
Python
# Define the number of splits you want
n_splits = 4
# Calculate count of each dataframe rows
each_len = prod_df.count() // n_splits
# Create a copy of original dataframe
copy_df = prod_df
# Iterate for each dataframe
i = 0
while i < n_splits:
# Get the top `each_len` number of rows
temp_df = copy_df.limit(each_len)
# Truncate the `copy_df` to remove
# the contents fetched for `temp_df`
copy_df = copy_df.subtract(temp_df)
# View the dataframe
temp_df.show(truncate=False)
# Increment the split number
i += 1
输出:
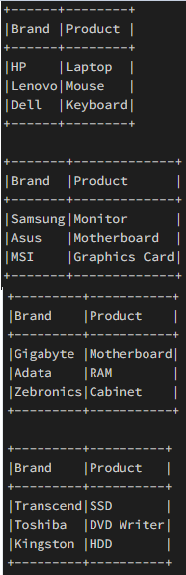
示例 2:拆分数据帧,执行操作并连接结果
我们现在将数据帧分成“n”个相等的部分,并对这些部分中的每一个单独执行连接操作,然后将结果连接到一个“result_df”。这是为了演示我们如何使用前面代码的扩展对每个数据帧分别执行数据帧操作,然后附加这些单独的数据帧以生成长度等于原始数据帧的新数据帧。
Python
# Define the number of splits you want
from pyspark.sql.types import StructType, StructField, StringType
from pyspark.sql.functions import concat, col, lit
n_splits = 4
# Calculate count of each dataframe rows
each_len = prod_df.count() // n_splits
# Create a copy of original dataframe
copy_df = prod_df
# Function to modify columns of each individual split
def modify_dataframe(data):
return data.select(
concat(col("Brand"), lit(" - "),
col("Product"))
)
# Create an empty dataframe to
# store concatenated results
schema = StructType([
StructField('Brand - Product', StringType(), True)
])
result_df = spark.createDataFrame(data=[],
schema=schema)
# Iterate for each dataframe
i = 0
while i < n_splits:
# Get the top `each_len` number of rows
temp_df = copy_df.limit(each_len)
# Truncate the `copy_df` to remove
# the contents fetched for `temp_df`
copy_df = copy_df.subtract(temp_df)
# Perform operation on the newly created dataframe
temp_df_mod = modify_dataframe(data=temp_df)
temp_df_mod.show(truncate=False)
# Concat the dataframe
result_df = result_df.union(temp_df_mod)
# Increment the split number
i += 1
result_df.show(truncate=False)
输出:
