使用 None 或 Null 值过滤 PySpark DataFrame 列
很多时候在处理 PySpark SQL 数据帧时,数据帧在列中包含许多 NULL/None 值,在许多情况下,在执行数据帧的任何操作之前,我们首先必须处理 NULL/None 值以获得所需的值结果或输出,我们必须从数据框中过滤那些 NULL 值。
在本文中,我们将学习如何使用 NULL/None 值过滤 PySpark 数据框列。
用于过滤所述NULL /无值我们在PySpark API知道该函数的作为过滤器()和与此函数,我们使用isNotNull()函数。
Syntax:
- df.filter(condition) : This function returns the new dataframe with the values which satisfies the given condition.
- df.column_name.isNotNull() : This function is used to filter the rows that are not NULL/None in the dataframe column.
示例 1:使用 None 值过滤 PySpark 数据框列
在下面的代码中,我们创建了 Spark 会话,然后我们创建了 Dataframe,其中每列都包含一些 None 值。现在,我们使用 filter() 过滤了 Name 列中存在的 None 值,其中我们传递了条件df.Name.isNotNull()来过滤 Name 列的 None 值。
Python
# importing necessary libraries
from pyspark.sql import SparkSession
# function to create SparkSession
def create_session():
spk = SparkSession.builder \
.master("local") \
.appName("Filter_values.com") \
.getOrCreate()
return spk
# function to create dataframe
def create_df(spark, data, schema):
df1 = spark.createDataFrame(data, schema)
return df1
if __name__ == "__main__":
# calling function to create SparkSession
spark = create_session()
input_data = [("Shivansh", "Data Scientist", "Noida"),
(None, "Software Developer", None),
("Swati", "Data Analyst", "Hyderabad"),
(None, None, "Noida"),
("Arpit", "Android Developer", "Banglore"),
(None, None, None)]
schema = ["Name", "Job Profile", "City"]
# calling function to create dataframe
df = create_df(spark, input_data, schema)
# filtering the columns with None values
df = df.filter(df.Name.isNotNull())
# visulizing the dataframe
df.show()Python
# importing necessary libraries
from pyspark.sql import SparkSession
# function to create new SparkSession
def create_session():
spk = SparkSession.builder \
.master("local") \
.appName("Filter_values.com") \
.getOrCreate()
return spk
def create_df(spark, data, schema):
df1 = spark.createDataFrame(data, schema)
return df1
if __name__ == "__main__":
# calling function to create SparkSession
spark = create_session()
input_data = [("Shivansh", "Data Scientist", "Noida"),
(None, "Software Developer", None),
("Swati", "Data Analyst", "Hyderabad"),
(None, None, "Noida"),
("Arpit", "Android Developer", "Banglore"),
(None, None, None)]
schema = ["Name", "Job Profile", "City"]
# calling function to create dataframe
df = create_df(spark, input_data, schema)
# filtering the columns with None values
df = df.filter("City is Not NULL")
# visulizing the dataframe
df.show()Python
# importing necessary libraries
from pyspark.sql import SparkSession
# function to create SparkSession
def create_session():
spk = SparkSession.builder \
.master("local") \
.appName("Filter_values.com") \
.getOrCreate()
return spk
def create_df(spark, data, schema):
df1 = spark.createDataFrame(data, schema)
return df1
if __name__ == "__main__":
# calling function to create SparkSession
spark = create_session()
input_data = [("Shivansh", "Data Scientist", "Noida"),
(None, "Software Developer", None),
("Swati", "Data Analyst", "Hyderabad"),
(None, None, "Noida"),
("Arpit", "Android Developer", "Banglore"),
(None, None, None)]
schema = ["Name", "Job Profile", "City"]
# calling function to create dataframe
df = create_df(spark, input_data, schema)
# filtering the Job Profile with None values
df = df.filter(df["Job Profile"].isNotNull())
# visulizing the dataframe
df.show()输出:

原始数据框
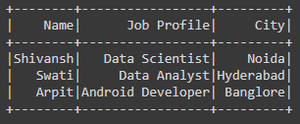
过滤 NULL/None 值后的数据框
示例 2:使用 filter()函数过滤具有 NULL/None 值的 PySpark 数据帧列
在下面的代码中,我们创建了 Spark 会话,然后我们创建了 Dataframe,其中每列都包含一些 None 值。现在,我们使用 filter() 过滤了 City 列中存在的 None 值,其中我们以英语形式传递了条件,即“City is Not Null” 这是过滤 City 列的 None 值的条件。
注意:条件必须用双引号引起来。
Python
# importing necessary libraries
from pyspark.sql import SparkSession
# function to create new SparkSession
def create_session():
spk = SparkSession.builder \
.master("local") \
.appName("Filter_values.com") \
.getOrCreate()
return spk
def create_df(spark, data, schema):
df1 = spark.createDataFrame(data, schema)
return df1
if __name__ == "__main__":
# calling function to create SparkSession
spark = create_session()
input_data = [("Shivansh", "Data Scientist", "Noida"),
(None, "Software Developer", None),
("Swati", "Data Analyst", "Hyderabad"),
(None, None, "Noida"),
("Arpit", "Android Developer", "Banglore"),
(None, None, None)]
schema = ["Name", "Job Profile", "City"]
# calling function to create dataframe
df = create_df(spark, input_data, schema)
# filtering the columns with None values
df = df.filter("City is Not NULL")
# visulizing the dataframe
df.show()
输出:
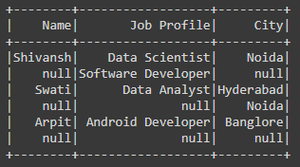
原始数据框

从城市列中过滤 NULL/None 值后
示例 3:当列名有空格时,使用 filter() 过滤具有 None 值的列
在下面的代码中,我们创建了 Spark 会话,然后我们创建了 Dataframe,其中每列都包含一些 None 值。我们使用 filter()函数过滤了“Job Profile”列中存在的 None 值,其中我们传递了条件df[“Job Profile”].isNotNull()来过滤 Job Profile 列的 None 值。
注意:为了访问单词之间有空格的列名,通过使用方括号 [] 表示参考数据框,我们必须使用方括号给出名称。
Python
# importing necessary libraries
from pyspark.sql import SparkSession
# function to create SparkSession
def create_session():
spk = SparkSession.builder \
.master("local") \
.appName("Filter_values.com") \
.getOrCreate()
return spk
def create_df(spark, data, schema):
df1 = spark.createDataFrame(data, schema)
return df1
if __name__ == "__main__":
# calling function to create SparkSession
spark = create_session()
input_data = [("Shivansh", "Data Scientist", "Noida"),
(None, "Software Developer", None),
("Swati", "Data Analyst", "Hyderabad"),
(None, None, "Noida"),
("Arpit", "Android Developer", "Banglore"),
(None, None, None)]
schema = ["Name", "Job Profile", "City"]
# calling function to create dataframe
df = create_df(spark, input_data, schema)
# filtering the Job Profile with None values
df = df.filter(df["Job Profile"].isNotNull())
# visulizing the dataframe
df.show()
输出:

原始数据框
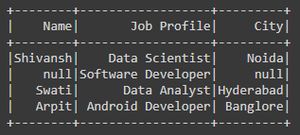
从 Job Profile 列过滤 NULL/None 值后