PySpark 计数与 DataFrame 不同
在本文中,我们将讨论如何计算 Pyspark DataFrame 中存在的不同值。
在 Pyspark 中,有两种方法可以获取不同值的计数。我们可以使用 DataFrame 的distinct()和count()函数来获取 PySpark DataFrame 的不同计数。另一种方法是使用 SQL countDistinct()函数,该函数将提供所有选定列的不同值计数。让我们通过示例了解与 DataFrame 不同的两种计数方式。
方法一:distinct().count():
distinct 和 count 是可以应用于 DataFrame 的两个不同函数。 distinct() 将通过检查 DataFrame 中一行的所有列来消除所有重复值或记录,count() 将返回 DataFrame 上的记录计数。通过将这两个函数一个接一个地链接起来,我们可以得到 PySpark DataFrame 的不同计数。
示例 1:使用 distinct().count() 从 DataFrame 中区分 Pyspark Count
在此示例中,我们将创建一个 DataFrame df,其中包含学生详细信息,例如姓名、课程和分数。 DataFrame 也包含一些重复的值。我们将应用 distinct().count() 找出 DataFrame df 中存在的所有不同值计数。
Python3
# importing module
import pyspark
# importing sparksession from
# pyspark.sql mudule
from pyspark.sql import SparkSession
# creating sparksession and giving
# app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# giving rows value for dataframe
data = [("Ram", "MCA", 80),
("Riya", "MBA", 85),
("Jiya", "B.E", 60),
("Maria", "B.Tech", 65),
("Shreya", "B.sc", 91),
("Ram", "MCA", 80),
("John", "M.E", 85),
("Shyam", "BA", 70),
("Kumar", "B.sc", 78),
("Maria", "B.Tech", 65)]
# giving column names of dataframe
columns = ["Name", "Course", "Marks"]
# creating a dataframe df
df = spark.createDataFrame(data, columns)
# show df
df.show()
# counting the total number of values
# in df
print("Total number of records in df:", df.count())Python3
# applying distinct().count() on df
print('Distinct count in DataFrame df is :', df.distinct().count())Python3
# importing sparksession from
# pyspark.sql mudule
from pyspark.sql import SparkSession
# creating sparksession and giving
# app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# giving rows value for dataframe
data = [("Ram", "IT", 80000),
("Shyam", "Sales", 70000),
("Jiya", "Sales", 60000),
("Maria", "Accounts", 65000),
("Ramesh", "IT", 80000),
("John", "Management", 80000),
("Shyam", "Sales", 70000),
("Kumar", "Sales", 78000),
("Maria", "Accounts", 65000)]
# giving column names of dataframe
columns = ["Emp_name", "Depart", "Salary"]
# creating a dataframe df
df = spark.createDataFrame(data, columns)
# show df
df.show()
# counting the total number of values in df
print("Total number of records in df:", df.count())Python3
# importing countDistinct from
# pyspark.sql.functions
from pyspark.sql.functions import countDistinct
# applying the function countDistinct()
# on df using select()
df2 = df.select(countDistinct("Emp_name", "Depart", "Salary"))
# show df2
df2.show()Python3
# importing countDistinct from
# pyspark.sql.functions
from pyspark.sql.functions import countDistinct
# applying the function countDistinct()
# on df using select()
df3 = df.select(countDistinct("Depart"))
# show df2
df3.show()Python3
# importing sparksession from pyspark.sql mudule
from pyspark.sql import SparkSession
# creating sparksession and giving app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# giving rows value for dataframe
data = [("Ram", "IT", 44, 80000),
("Shyam", "Sales", 45, 70000),
("Jiya", "Sales", 30, 60000),
("Maria", "Accounts", 29, 65000),
("Ram", "IT", 38, 80000),
("John", "Management", 35, 80000),
("Shyam", "Sales", 45, 70000),
("Kumar", "Sales", 27, 70000),
("Maria", "Accounts", 32, 65000),
("Ria", "Management", 32, 65000)]
# giving column names of dataframe
columns = ["Emp_name", "Depart", "Age", "Salary"]
# creating a dataframe df
df = spark.createDataFrame(data, columns)
# show df
df.show()
# counting the total number of values in df
print("Total number of records in df:", df.count())Python3
# creating a temporary view of
# Dataframe and storing it into df2
df.createOrReplaceTempView("df2")
# using the SQL query to count all
# distinct records and display the
# count on the screen
spark.sql("select count(distinct(*)) from df2").show()Python3
# using the SQL query to count distinct
# records in 2 columns only display the
# count on the screen
spark.sql("select count(distinct(Emp_name, Salary)) from df2").show()输出:

这是我们创建的 DataFrame df,它总共包含 10 条记录。现在,我们应用 distinct().count() 找出 DataFrame df 中存在的总不同值计数。
蟒蛇3
# applying distinct().count() on df
print('Distinct count in DataFrame df is :', df.distinct().count())
输出:
Distinct count in DataFrame df is : 8在此输出中,我们可以看到 DataFrame df 中存在 8 个不同的值。
方法 2:countDistinct():
此函数提供一组选定列中存在的不同元素的计数。 countDistinct() 是一个 SQL函数,它将提供所有选定列的不同值计数。
示例 1:使用 countDistinct() 从 DataFrame 中区分 Pyspark 计数。
在此示例中,我们将创建一个 DataFrame df,其中包含员工详细信息,例如 Emp_name、Department 和 Salary。 DataFrame 也包含一些重复的值。我们将应用 countDistinct() 来找出 DataFrame df 中存在的所有不同值计数。
蟒蛇3
# importing sparksession from
# pyspark.sql mudule
from pyspark.sql import SparkSession
# creating sparksession and giving
# app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# giving rows value for dataframe
data = [("Ram", "IT", 80000),
("Shyam", "Sales", 70000),
("Jiya", "Sales", 60000),
("Maria", "Accounts", 65000),
("Ramesh", "IT", 80000),
("John", "Management", 80000),
("Shyam", "Sales", 70000),
("Kumar", "Sales", 78000),
("Maria", "Accounts", 65000)]
# giving column names of dataframe
columns = ["Emp_name", "Depart", "Salary"]
# creating a dataframe df
df = spark.createDataFrame(data, columns)
# show df
df.show()
# counting the total number of values in df
print("Total number of records in df:", df.count())

这是我们创建的 DataFrame df,它总共包含 9 条记录。现在,我们将应用 countDistinct() 来找出 DataFrame df 中存在的总不同值计数。要应用此函数,我们将从 pyspark.sql.functions 模块导入该函数。
蟒蛇3
# importing countDistinct from
# pyspark.sql.functions
from pyspark.sql.functions import countDistinct
# applying the function countDistinct()
# on df using select()
df2 = df.select(countDistinct("Emp_name", "Depart", "Salary"))
# show df2
df2.show()
输出:
+----------------------------------------+
|count(DISTINCT Emp_name, Depart, Salary)|
+----------------------------------------+
| 7|
+----------------------------------------+DataFrame df 中有 7 个不同的记录。 countDistinct() 以列格式提供不同的计数值,如输出所示,因为它是一个 SQL函数。
现在,让我们看看基于某一特定列的不同值计数。我们将计算员工详细信息 df 的部门列中存在的不同值。
蟒蛇3
# importing countDistinct from
# pyspark.sql.functions
from pyspark.sql.functions import countDistinct
# applying the function countDistinct()
# on df using select()
df3 = df.select(countDistinct("Depart"))
# show df2
df3.show()
输出:
+----------------------+
|count(DISTINCT Depart)|
+----------------------+
| 4|
+----------------------+部门列中有 4 个不同的值。在此示例中,我们仅在 Depart 列上应用了 countDistinct()。
示例 2:使用 SQL 查询与 DataFrame 不同的 Pyspark 计数。
在此示例中,我们创建了一个包含员工详细信息(如 Emp_name、Depart、Age 和 Salary)的数据框。现在,我们将使用我们在 SQL 中使用的简单 SQL 查询来计算数据帧中的不同记录。让我们看一下例子并理解它:
蟒蛇3
# importing sparksession from pyspark.sql mudule
from pyspark.sql import SparkSession
# creating sparksession and giving app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# giving rows value for dataframe
data = [("Ram", "IT", 44, 80000),
("Shyam", "Sales", 45, 70000),
("Jiya", "Sales", 30, 60000),
("Maria", "Accounts", 29, 65000),
("Ram", "IT", 38, 80000),
("John", "Management", 35, 80000),
("Shyam", "Sales", 45, 70000),
("Kumar", "Sales", 27, 70000),
("Maria", "Accounts", 32, 65000),
("Ria", "Management", 32, 65000)]
# giving column names of dataframe
columns = ["Emp_name", "Depart", "Age", "Salary"]
# creating a dataframe df
df = spark.createDataFrame(data, columns)
# show df
df.show()
# counting the total number of values in df
print("Total number of records in df:", df.count())
输出:
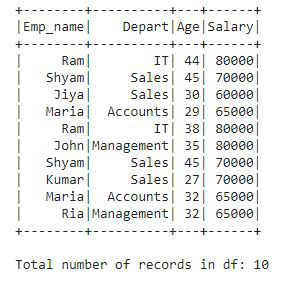
这是包含总共 10 条记录以及一些重复记录的数据框。现在,我们将使用 SQL 查询并找出在此数据框中找到多少条不同的记录。它就像我们在 SQL 中所做的一样简单。
蟒蛇3
# creating a temporary view of
# Dataframe and storing it into df2
df.createOrReplaceTempView("df2")
# using the SQL query to count all
# distinct records and display the
# count on the screen
spark.sql("select count(distinct(*)) from df2").show()
输出:
+---------------------------------------------+
|count(DISTINCT Emp_name, Depart, Age, Salary)|
+---------------------------------------------+
| 9|
+---------------------------------------------+在整个数据帧 df 中发现了 9 个不同的记录。
现在让我们使用以下 SQL 查询在两列(即 Emp_name 和 Salary)中找到不同的值计数。
蟒蛇3
# using the SQL query to count distinct
# records in 2 columns only display the
# count on the screen
spark.sql("select count(distinct(Emp_name, Salary)) from df2").show()
输出:
+----------------------------------------------------------------+
|count(DISTINCT named_struct(Emp_name, Emp_name, Salary, Salary))|
+----------------------------------------------------------------+
| 7|
+----------------------------------------------------------------+在 Emp_name 和 Salary 列中有 7 个不同的值。
由于 SQL 以表格格式提供对数据执行的所有操作的输出。我们在包含两行的列中得到了答案,第一行有标题,第二行包含不同的记录数。在 Example2 中也得到了相同格式的输出,countDistinct() 也是一个 SQL函数。