CURE算法的基本理解
CURE(使用代表聚类)
- 它是一种基于层次的聚类技术,在基于质心和全点极值之间采用中间立场。层次聚类是一种聚类,它从一个点聚类开始,然后移动到与另一个聚类合并,直到形成所需数量的聚类。
- 它用于识别球形和非球形簇。
- 它对于发现组和识别基础数据中的有趣分布很有用。
- CURE 不像大多数数据挖掘算法那样使用一个点质心,而是使用一组定义明确的代表点,以有效地处理集群并消除异常值。

集群和异常值的表示
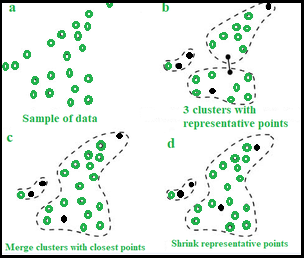
CURE算法的六个步骤:

治愈架构
- 想法:随机样本,比如“s”是从给定数据中提取的。这个随机样本是分区的,比如大小为 s/p 的“p”个分区。分区样本是部分聚类的,例如“s/pq”聚类。异常值从这个部分聚集的分区中被丢弃/消除。部分集群的分区需要再次集群。标记磁盘中的数据。

划分和聚类的表示
- 程序 :
- 选择目标样本编号“gfg”。
- 选择集群中分散良好的“gfg”点。
- 这些分散的点向质心收缩。
- 这些点用作集群的代表并用于“Dmin”集群合并方法。在 Dmin(distance minimum) 聚类合并方法中,计算样本“gfg”内的散点与“gfg 样本”外的点的最小距离。与其他点相比,与样本内的散射点距离最短的点被考虑并合并到样本中。
- 在每次这样的合并之后,将选择新的样本点来代表新的集群。
- 集群合并将停止,直到达到目标,比如“k”。