清理给定 Pandas Dataframe 中的字符串数据
众所周知,在当今世界,各种公司都在使用数据分析。在处理数据时,我们可能会遇到任何需要开箱即用方法进行评估的问题。现实生活中的大多数数据都包含实体的名称或其他名词。名称可能格式不正确。在这篇文章中,我们将讨论清理此类数据的方法。
假设我们正在处理基于电子商务的网站的数据。产品名称的格式不正确。正确格式化数据,使得没有前导和尾随空格,并且所有产品的第一个字母都是大写字母。
解决方案#1:很多时候我们会遇到需要编写适合手头任务的自定义函数的情况。
# importing pandas as pd
import pandas as pd
# Create the dataframe
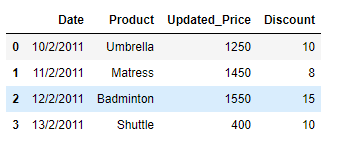
df = pd.DataFrame({'Date':['10/2/2011', '11/2/2011', '12/2/2011', '13/2/2011'],
'Product':[' UMbreLla', ' maTress', 'BaDmintoN ', 'Shuttle'],
'Updated_Price':[1250, 1450, 1550, 400],
'Discount':[10, 8, 15, 10]})
# Print the dataframe
print(df)
输出 :
现在我们将编写自己的自定义函数来解决这个问题。
def Format_data(df):
# iterate over all the rows
for i in range(df.shape[0]):
# reassign the values to the product column
# we first strip the whitespaces using strip() function
# then we capitalize the first letter using capitalize() function
df.iat[i, 1]= df.iat[i, 1].strip().capitalize()
# Let's call the function
Format_data(df)
# Print the Dataframe
print(df)
输出 : 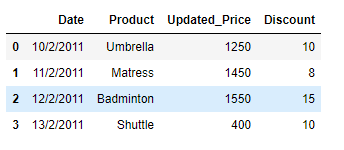
解决方案 #2:现在我们将看到使用 Pandas DataFrame.apply()函数的更好、更有效的方法。
# importing pandas as pd
import pandas as pd
# Create the dataframe
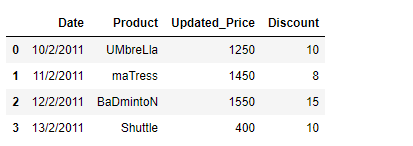
df = pd.DataFrame({''Date':['10/2/2011', '11/2/2011', '12/2/2011', '13/2/2011'],
'Product':[' UMbreLla', ' maTress', 'BaDmintoN ', 'Shuttle'],
'Updated_Price':[1250, 1450, 1550, 400],
'Discount':[10, 8, 15, 10]})
# Print the dataframe
print(df)
输出 :
让我们使用 Pandas DataFrame.apply()函数以正确的格式格式化产品名称。在 Pandas DataFrame.apply()函数中,我们将使用 lambda函数。
# Using the df.apply() function on product column
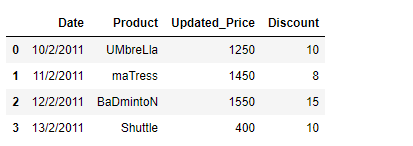
df['Product'] = df['Product'].apply(lambda x : x.strip().capitalize())
# Print the Dataframe
print(df)
输出 :