Pandas DataFrame 中的字符串操作
字符串操作是更改、解析、拼接、粘贴或分析字符串的过程。我们知道,有时,字符串中的数据不适合操纵分析或获取数据的描述。但是Python以其操纵字符串的能力而闻名。因此,通过在这里扩展它,我们将了解 Pandas 如何为我们提供使用一些内置函数来修改和处理字符串数据帧的方法。 Pandas 库有一些通常用于字符串数据帧操作的内置函数
首先,我们将知道使用 pandas 创建字符串数据框的方法:
Python3
# Importing the necessary libraries
import pandas as pd
import numpy as np
# df stands for dataframe
df = pd.Series(['Gulshan', 'Shashank', 'Bablu',
'Abhishek', 'Anand', np.nan, 'Pratap'])
print(df)Python3
# we can change the dtype after
# creation of dataframe
print(df.astype('string'))Python3
# now creating the dataframe as dtype = 'string'
import pandas as pd
import numpy as np
df = pd.Series(['Gulshan', 'Shashank', 'Bablu', 'Abhishek',
'Anand', np.nan, 'Pratap'], dtype='string')
print(df)Python3
# now creating the dataframe as dtype = pd.StringDtype()
import pandas as pd
import numpy as np
df = pd.Series(['Gulshan', 'Shashank', 'Bablu', 'Abhishek',
'Anand', np.nan, 'Pratap'], dtype=pd.StringDtype())
print(df)Python3
# python script for create a dataframe
# for string manipulations
import pandas as pd
import numpy as np
df = pd.Series(['night_fury1', 'Is ', 'Geeks, forgeeks',
'100', np.nan, ' Contributor '])
dfPython3
# lower()
print(df.str.lower())Python3
#upper()
print(df.str.upper())Python3
# strip()
print(df)
print('\nAfter using the strip:')
print(df.str.strip())Python3
# split(pattern)
print(df)
print('\nAfter using the strip:')
print(df.str.split(','))
# now we can use [] or get() to fetch
# the index values
print('\nusing []:')
print(df.str.split(',').str[0])
print('\nusing get():')
print(df.str.split(',').str.get(1))Python3
# len()
print("length of the dataframe: ", len(df))
print("length of each value of dataframe:")
print(df.str.len())Python3
# cat(sep=pattern)
print(df)
print("\nafter using cat:")
print(df.str.cat(sep='_'))
print("\nworking with NaN using cat:")
print(df.str.cat(sep='_', na_rep='#'))Python3
# get_dummies()
print(df.str.get_dummies())Python3
# startswith(pattern)
print(df.str.startswith('G'))Python3
# endswith(pattern)
print(df.str.endswith('1'))Python3
# replace(a,b)
print(df)
print("\nAfter using replace:")
print(df.str.replace('Geeks', 'Gulshan'))Python3
# repeat(value)
print(df.str.repeat(2))Python3
# count(pattern)
print(df.str.count('n'))Python3
# find(pattern)
# in result '-1' indicates there is no
# value matching with given pattern in
# particular row
print(df.str.find('n'))Python3
# findall(pattern)
# in result [] indicates null list as
# there is no value matching with given
# pattern in particular row
print(df.str.findall('n'))Python3
# islower()
print(df.str.islower())Python3
# isupper()
print(df.str.isupper())Python3
# isnumeric()
print(df.str.isnumeric())Python3
# swapcase()
print(df.str.swapcase())输出:

让我们将上面创建的数据框的类型更改为字符串类型。可以有多种方法来做同样的事情。让我们在下面的例子中看看它们。
示例 1:我们可以在创建数据框后更改 dtype:
Python3
# we can change the dtype after
# creation of dataframe
print(df.astype('string'))
输出:

示例 2:将数据框创建为 dtype = ' 字符串':
Python3
# now creating the dataframe as dtype = 'string'
import pandas as pd
import numpy as np
df = pd.Series(['Gulshan', 'Shashank', 'Bablu', 'Abhishek',
'Anand', np.nan, 'Pratap'], dtype='string')
print(df)
输出:

示例 3:将数据框创建为 dtype = pd.StringDtype():
Python3
# now creating the dataframe as dtype = pd.StringDtype()
import pandas as pd
import numpy as np
df = pd.Series(['Gulshan', 'Shashank', 'Bablu', 'Abhishek',
'Anand', np.nan, 'Pratap'], dtype=pd.StringDtype())
print(df)
输出:

Pandas 中的字符串操作
现在,我们看到了一个pandas数据框内部的字符串操作,所以首先创建一个数据框,并在下面这个单一数据框上操作所有字符串操作,这样大家就可以轻松了解了。
例子:
Python3
# python script for create a dataframe
# for string manipulations
import pandas as pd
import numpy as np
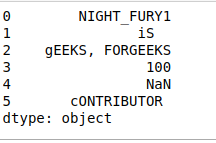
df = pd.Series(['night_fury1', 'Is ', 'Geeks, forgeeks',
'100', np.nan, ' Contributor '])
df
输出:

让我们看一下这个库为字符串操作提供的各种方法。
- lower():将DataFrame中字符串中的所有大写字符转换为小写,并在结果中返回小写字符串。
Python3
# lower()
print(df.str.lower())
0 night_fury1
1 is
2 geeks, forgeeks
3 100
4 NaN
5 contributor
dtype: object
- upper():将DataFrame中字符串中的所有小写字符转换为大写,并在result中返回大写字符串。
Python3
#upper()
print(df.str.upper())
输出:
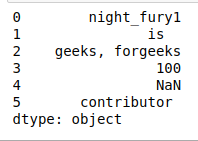
- strip():如果字符串的开头或结尾有空格,我们应该使用 strip() 修剪字符串以消除空格或删除 DataFrame 中字符串包含的多余空格。
Python3
# strip()
print(df)
print('\nAfter using the strip:')
print(df.str.strip())
输出:

- split(' '):用给定的模式分割每个字符串。字符串被拆分,执行拆分操作后的新元素存储在列表中。
Python3
# split(pattern)
print(df)
print('\nAfter using the strip:')
print(df.str.split(','))
# now we can use [] or get() to fetch
# the index values
print('\nusing []:')
print(df.str.split(',').str[0])
print('\nusing get():')
print(df.str.split(',').str.get(1))
输出:


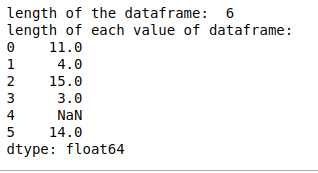
- len():在 len() 的帮助下,我们可以计算 DataFrame 中每个字符串的长度,如果 DataFrame 中有空数据,则返回 NaN。
Python3
# len()
print("length of the dataframe: ", len(df))
print("length of each value of dataframe:")
print(df.str.len())
输出:
- cat(sep=' '):它将数据帧索引元素或 DataFrame 中的每个字符串与给定的分隔符连接起来。
Python3
# cat(sep=pattern)
print(df)
print("\nafter using cat:")
print(df.str.cat(sep='_'))
print("\nworking with NaN using cat:")
print(df.str.cat(sep='_', na_rep='#'))
输出:

- get_dummies():它返回带有 One-Hot Encoded 值的 DataFrame,就像我们可以看到它返回布尔值 1 如果它存在于相对索引中,则返回 0 如果不存在。
Python3
# get_dummies()
print(df.str.get_dummies())
输出:

- startswith(pattern):如果 DataFrame 索引中的元素或字符串以模式开头,则返回 true。
Python3
# startswith(pattern)
print(df.str.startswith('G'))
输出:

- endswith(pattern):如果 DataFrame 索引中的元素或字符串以模式结尾,则返回 true。
Python3
# endswith(pattern)
print(df.str.endswith('1'))
输出:

- replace(a,b):它用值 b 替换值 a,如下例中的“Geeks”被“Gulshan”替换。
Python3
# replace(a,b)
print(df)
print("\nAfter using replace:")
print(df.str.replace('Geeks', 'Gulshan'))
输出:

- repeat(value):它以给定的次数重复每个元素,如下例所示,DataFrame 中每个字符串出现两次。
Python3
# repeat(value)
print(df.str.repeat(2))
输出:

- count(pattern):它返回 Data-Frame 中每个元素中出现模式的计数,如下例所示,它在 DataFrame 的每个字符串中计数“n”,并返回每个字符串中“n”的总计数。
Python3
# count(pattern)
print(df.str.count('n'))
输出:
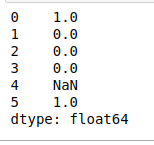
- find(pattern):它返回模式第一次出现的第一个位置。我们可以在下面的示例中看到,它返回整个 DataFrame 中每个字符串中字符“n”出现的索引值。
Python3
# find(pattern)
# in result '-1' indicates there is no
# value matching with given pattern in
# particular row
print(df.str.find('n'))
输出:

- findall(pattern):它返回所有出现的模式的列表。正如我们在下面看到的,有一个包含 n 的返回列表,因为它在字符串中只出现一次。
Python3
# findall(pattern)
# in result [] indicates null list as
# there is no value matching with given
# pattern in particular row
print(df.str.findall('n'))
输出:
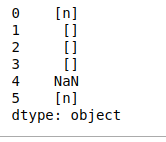
- islower():检查Data-Frame索引中每个字符串中的所有字符是否为小写,并返回一个布尔值。
Python3
# islower()
print(df.str.islower())
输出:
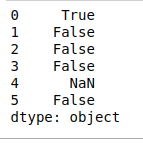
- isupper():检查Data-Frame索引中每个字符串的所有字符是否大写,并返回一个布尔值。
Python3
# isupper()
print(df.str.isupper())
输出:

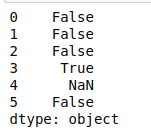
- isumeric():检查数据帧索引中每个字符串中的所有字符是否都是数字,并返回一个布尔值。
Python3
# isnumeric()
print(df.str.isnumeric())
输出:
- swapcase():它将大小写从低到高交换,反之亦然。如下例所示,它将每个字符串中的所有大写字符转换为小写,反之亦然(小写 -> 大写)。
Python3
# swapcase()
print(df.str.swapcase())
输出: