在 R 中按组计算唯一值
在本文中,我们将讨论如何在 R 编程语言中按组计算唯一值的数量。所以让我们看下面的例子,
假设您有一个包含多列的数据集,如下所示: class age age_group 1 A 20 YOUNG 2 B 15 KID 3 C 45 OLD 4 B 14 KID 5 A 21 YOUNG 6 A 22 YOUNG 7 C 47 OLD 8 A 19 YOUNG 9 B 16 KID 10 C 50 OLD 11 A 23 YOUNG
在这个虚拟数据集类中, age 、 age_group表示列名,我们的任务是按 age_group 计算唯一值的数量。
因此,结果数据集应如下所示: age_group unique_count 1 YOUNG 5 2 KID 3 3 OLD 3
方法一:使用聚合函数
使用聚合函数,我们可以对多行执行操作(通过对数据进行分组)并生成单个汇总值。
例子:
R
# Count Unique values by group
# Creating dataset
# creating class column
x <- c("A","B","C","B","A","A","C","A","B","C","A")
# creating age column
y <- c(20,15,45,14,21,22,47,18,16,50,23)
# creating age_group column
z <- c("YOUNG","KID","OLD","KID","YOUNG","YOUNG",
"OLD","YOUNG","KID","OLD","YOUNG")
# creating dataframe
df <- data.frame(class=x,age=y,age_group=z)
df
# applying aggregate function
aggregate( age~age_group,df, function(x) length(unique(x)))R
# Count Unique values by group
# loading dplyr
library("dplyr")
# Creating dataset
# creating class column
x <- c("A","B","C","B","A","A","C","A","B","C","A")
# creating age column
y <- c(20,15,45,14,21,22,47,18,16,50,23)
# creating age_group column
z <- c("YOUNG","KID","OLD","KID","YOUNG","YOUNG",
"OLD","YOUNG","KID","OLD","YOUNG")
# creating dataframe
df <- data.frame(class=x,age=y,age_group=z)
# grouping age_group column
# counting all the unique
# value based on the age_group
# column
df %>%
group_by(age_group) %>%
summarise(n_distinct(age))输出:
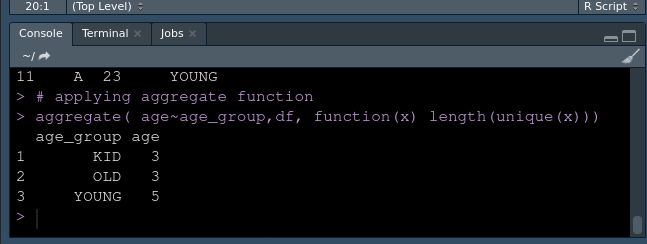
输出 1。
方法二:使用dplyr包和group_by函数
“ dplyr ”是 最广泛使用的 R 包。 它主要用于数据整理目的。它提供了一组用于数据操作的工具。
例子:
电阻
# Count Unique values by group
# loading dplyr
library("dplyr")
# Creating dataset
# creating class column
x <- c("A","B","C","B","A","A","C","A","B","C","A")
# creating age column
y <- c(20,15,45,14,21,22,47,18,16,50,23)
# creating age_group column
z <- c("YOUNG","KID","OLD","KID","YOUNG","YOUNG",
"OLD","YOUNG","KID","OLD","YOUNG")
# creating dataframe
df <- data.frame(class=x,age=y,age_group=z)
# grouping age_group column
# counting all the unique
# value based on the age_group
# column
df %>%
group_by(age_group) %>%
summarise(n_distinct(age))
输出:
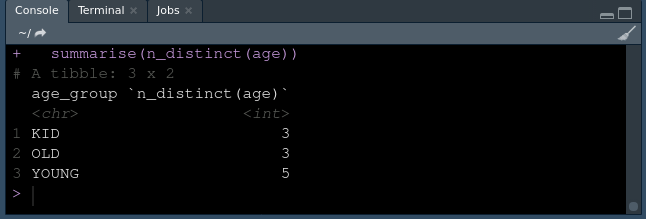
输出 2。