按列值拆分 Pandas 数据框
有时为了更准确地分析 Dataframe,我们需要将其拆分为 2 个或更多部分。 Pandas 提供了根据列索引、行索引和列值等拆分 Dataframe 的功能。
让我们看看如何在Python中按列值拆分 Pandas 数据框?
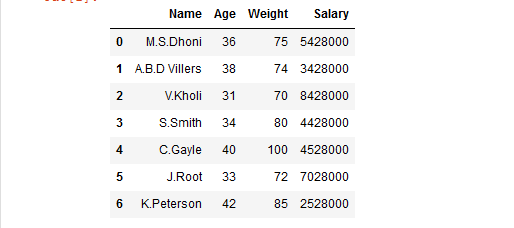
现在,让我们创建一个数据框:
维利尔斯
Python3
# importing pandas library
import pandas as pd
# Initializing the nested list with Data-set
player_list = [['M.S.Dhoni', 36, 75, 5428000],
['A.B.D Villiers', 38, 74, 3428000],
['V.Kholi', 31, 70, 8428000],
['S.Smith', 34, 80, 4428000],
['C.Gayle', 40, 100, 4528000],
['J.Root', 33, 72, 7028000],
['K.Peterson', 42, 85, 2528000]]
# creating a pandas dataframe
df = pd.DataFrame(player_list,
columns = ['Name', 'Age',
'Weight', 'Salary'])
# show the dataframe
dfPython3
# importing pandas library
import pandas as pd
# Initializing the nested list with Data-set
player_list = [['M.S.Dhoni', 36, 75, 5428000],
['A.B.D Villiers', 38, 74, 3428000],
['V.Kholi', 31, 70, 8428000],
['S.Smith', 34, 80, 4428000],
['C.Gayle', 40, 100, 4528000],
['J.Root', 33, 72, 7028000],
['K.Peterson', 42, 85, 2528000]]
# creating a pandas dataframe
df = pd.DataFrame(player_list,
columns = ['Name', 'Age',
'Weight', 'Salary'])
# splitting the dataframe into 2 parts
# on basis of 'Age' column values
# using Relational operator
df1 = df[df['Age'] >= 37]
# printing df1
df1Python3
df2 = df[df['Age'] < 37]
# printing df2
df2Python3
# importing pandas library
import pandas as pd
# Initializing the nested list with Data-set
player_list = [['M.S.Dhoni', 36, 75, 5428000],
['A.B.D Villiers', 38, 74, 3428000],
['V.Kholi', 31, 70, 8428000],
['S.Smith', 34, 80, 4428000],
['C.Gayle', 40, 100, 4528000],
['J.Root', 33, 72, 7028000],
['K.Peterson', 42, 85, 2528000]]
# creating a pandas dataframe
df = pd.DataFrame(player_list,
columns = ['Name', 'Age',
'Weight', 'Salary'])
# splitting the dataframe into 2 parts
# on basis of 'Weight' column values
mask = df['Weight'] >= 80
df1 = df[mask]
# invert the boolean values
df2 = df[~mask]
# printing df1
df1Python3
# printing df2
df2Python3
# importing pandas library
import pandas as pd
# Initializing the nested list with Data-set
player_list = [['M.S.Dhoni', 36, 75, 5428000],
['A.B.D Villiers', 38, 74, 3428000],
['V.Kholi', 31, 70, 8428000],
['S.Smith', 34, 80, 4428000],
['C.Gayle', 40, 100, 4528000],
['J.Root', 33, 72, 7028000],
['K.Peterson', 42, 85, 2528000]]
# creating a pandas dataframe
df = pd.DataFrame(player_list,
columns = ['Name', 'Age',
'Weight', 'Salary'])
# splitting the dataframe into 2 parts
# on basis of 'Salary' column values
# using dataframe.groupby() function
df1, df2 = [x for _, x in df.groupby(df['Salary'] < 4528000)]
# printing df1
df1Python3
# printing df2
df2输出:
方法一:使用布尔掩码 方法。
此方法仅用于打印我们传递布尔值 True 的那部分数据帧。
示例 1:
Python3
# importing pandas library
import pandas as pd
# Initializing the nested list with Data-set
player_list = [['M.S.Dhoni', 36, 75, 5428000],
['A.B.D Villiers', 38, 74, 3428000],
['V.Kholi', 31, 70, 8428000],
['S.Smith', 34, 80, 4428000],
['C.Gayle', 40, 100, 4528000],
['J.Root', 33, 72, 7028000],
['K.Peterson', 42, 85, 2528000]]
# creating a pandas dataframe
df = pd.DataFrame(player_list,
columns = ['Name', 'Age',
'Weight', 'Salary'])
# splitting the dataframe into 2 parts
# on basis of 'Age' column values
# using Relational operator
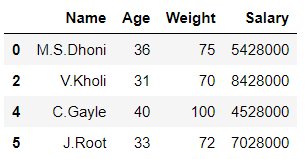
df1 = df[df['Age'] >= 37]
# printing df1
df1
输出:

Python3
df2 = df[df['Age'] < 37]
# printing df2
df2
输出:

在上面的示例中,数据框“df”根据列“ Age ”的值分为 2 个部分“df1”和“df2”。
示例 2:
Python3
# importing pandas library
import pandas as pd
# Initializing the nested list with Data-set
player_list = [['M.S.Dhoni', 36, 75, 5428000],
['A.B.D Villiers', 38, 74, 3428000],
['V.Kholi', 31, 70, 8428000],
['S.Smith', 34, 80, 4428000],
['C.Gayle', 40, 100, 4528000],
['J.Root', 33, 72, 7028000],
['K.Peterson', 42, 85, 2528000]]
# creating a pandas dataframe
df = pd.DataFrame(player_list,
columns = ['Name', 'Age',
'Weight', 'Salary'])
# splitting the dataframe into 2 parts
# on basis of 'Weight' column values
mask = df['Weight'] >= 80
df1 = df[mask]
# invert the boolean values
df2 = df[~mask]
# printing df1
df1
输出:

Python3
# printing df2
df2
输出:

在上面的示例中,数据框“df”根据“权重”列的值分为 2 个部分“df1”和“df2”。
方法 2:使用Dataframe.groupby() 。
此方法用于根据某些标准将数据分组。
例子:
Python3
# importing pandas library
import pandas as pd
# Initializing the nested list with Data-set
player_list = [['M.S.Dhoni', 36, 75, 5428000],
['A.B.D Villiers', 38, 74, 3428000],
['V.Kholi', 31, 70, 8428000],
['S.Smith', 34, 80, 4428000],
['C.Gayle', 40, 100, 4528000],
['J.Root', 33, 72, 7028000],
['K.Peterson', 42, 85, 2528000]]
# creating a pandas dataframe
df = pd.DataFrame(player_list,
columns = ['Name', 'Age',
'Weight', 'Salary'])
# splitting the dataframe into 2 parts
# on basis of 'Salary' column values
# using dataframe.groupby() function
df1, df2 = [x for _, x in df.groupby(df['Salary'] < 4528000)]
# printing df1
df1
输出:
Python3
# printing df2
df2
输出:

在上面的示例中,数据框“df”根据“ Salary ”列的值分为 2 个部分“df1”和“df2”。