Pandas GroupBy – 计算最后一个值
groupby操作涉及对大量数据进行分组并在这些组上进行计算操作。它通常涉及拆分对象、应用函数和组合结果的某种组合。在本文中,让我们看看如何使用 pandas 获取组中最后一个值的计数。
句法:
DataFrame.groupby(by, axis, as_index)参数:
- by (datatype-list, tuples, dict, series, array):映射、函数、标签或标签列表。传递的函数按原样用于确定组。
- 轴(数据类型 int,默认 0):1 - 拆分列和 0 - 拆分行。
- as_index(数据类型 bool,默认为 True。):返回一个以组标签为索引的对象,用于所有聚合输出,
方法一:使用 GroupBy & Aggregate函数
在这种方法中,用户需要调用 DataFrame.groupby()函数来演示如何使用Python语言中的 pandas 来获取组中最后一个值的计数。
例子:
在这个例子中,我们创建了一个带有汽车名称和价格的示例数据框,并在汽车上应用 groupby函数,设置 as_index false 不会创建新索引,然后使用“last”按汽车的最后价格聚合分组函数聚合函数中的参数并将列命名为“Price_last”。然后添加另一个 lambda函数以获取汽车获得最后价格的次数。
以下示例中使用的数据框:
cars Price_in_million
0 benz 15
1 benz 12
2 benz 23
3 benz 23
4 bmw 63
5 bmw 34
6 bmw 63Python3
# import python pandas package
import pandas as pd
# create a sample dataframe
data = pd.DataFrame({'cars': ['benz', 'benz', 'benz',
'benz', 'bmw', 'bmw', 'bmw'],
'Price_in_million': [15, 12, 23, 23,
63, 34, 63]})
# use groupby function to groupby cars, setting
# as_index false doesnt create an index.
# use aggregate function with 'last; parameter
# to get the last price im the group of cars.
# apply lambda function to get the number of
# times the car got the last price.
data.groupby('cars', as_index=False).agg(Price_last=('Price_in_million', 'last'),
Price_last_count=('Price_in_million',
lambda x: sum(x == x.iloc[-1])))Python3
# import python pandas package
import pandas as pd
# create a sample dataframe
data = pd.DataFrame({'cars': ['benz', 'benz', 'benz',
'benz', 'bmw', 'bmw', 'bmw'],
'Price_in_million': [15, 12, 23, 23, 63, 34, 63]})
# get the 4th row present in the data
data.iloc[4]
# Now apply lambda function to get the number
# of times the row is present in the dataset
data.apply(lambda x: sum(x==x.iloc[4]))Python3
# import pandas package
import pandas as pd
# create a sample dataset
data = pd.DataFrame({'cars': ['benz', 'benz', 'benz',
'benz', 'bmw', 'bmw', 'bmw'],
'Price_in_million': [15, 12, 23, 23, 63, 34, 63]})
# perform inner merge with the grouped and original dataset
merged = pd.merge(data.groupby('cars').tail(1), data, how='inner')
# apply a count aggregated groupby function to
# get the no. of. occurrences of last value.
result = merged.groupby(['cars', 'Price_in_million'])[
'Price_in_million'].agg('count')
print(result)Python3
# import pandas package
import pandas as pd
# create a sample dataset
data = pd.DataFrame({'cars': ['benz', 'benz', 'benz',
'benz', 'bmw', 'bmw', 'bmw'],
'Price_in_million': [15, 12, 23, 23, 63, 34, 63]})
# computes the final value of each group
grouped = data.groupby('cars').last()
# Merge dataset named "data" with this result
data = data.merge(grouped, left_on='cars', right_index=True, how='inner')
# Now compare the merged columns for same price
# and create a new column of boolean values
# where prices match
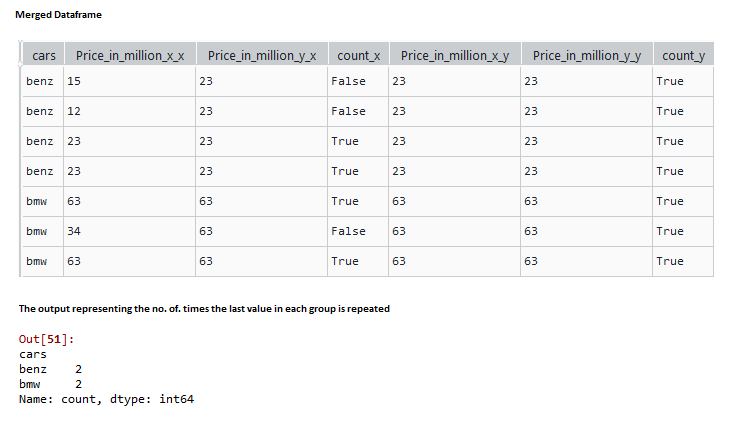
data['count'] = data['Price_in_million_x'] == data['Price_in_million_y']
# Use groupby function to return the aggregated
# sum of count column where the price matches
data.groupby('cars')['count'].sum()输出:
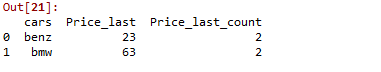
方法二:使用 Lambda函数
在这种方法中,用户必须调用上面使用的 lambda函数来返回 R 编程语言中数据帧中存在的相应行的计数。
例子:
如您所见,在此示例中,汽车 - BMW 和价格 63 对应于数据集中的第 4 行。应用上面的 lambda函数返回汽车 BMW 出现了 3 次,而价格 63 出现了 2 次。
Python3
# import python pandas package
import pandas as pd
# create a sample dataframe
data = pd.DataFrame({'cars': ['benz', 'benz', 'benz',
'benz', 'bmw', 'bmw', 'bmw'],
'Price_in_million': [15, 12, 23, 23, 63, 34, 63]})
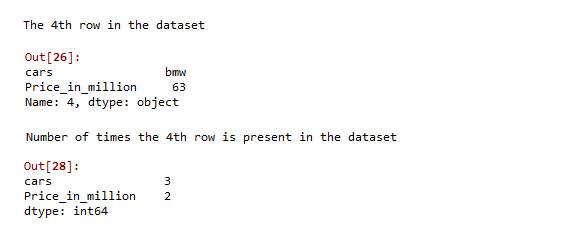
# get the 4th row present in the data
data.iloc[4]
# Now apply lambda function to get the number
# of times the row is present in the dataset
data.apply(lambda x: sum(x==x.iloc[4]))
输出:
方法三:使用 GroupBy、pandas Merge & Aggregate函数
使用 pandas 的组中最后一个值的计数也可以使用 pandas合并函数获得,如下所示。
句法:
DataFrame.merge(right, how='inner', on=None)参数:
- right - 要合并的对象。 (数据框或系列对象)。
- how - 左连接,右连接,外连接,默认 - 内连接
- on –(标签或列表)。指定要加入的列名。
例子:
在这个例子中,我们创建了一个带有汽车名称和价格的示例数据框,并在汽车上应用 groupby函数,并使用 tail()函数计算组的最终值。现在,对分组数据集和原始数据集执行内部合并。最后,应用计数聚合的 groupby函数来获得否。最后一个值的出现次数。
Python3
# import pandas package
import pandas as pd
# create a sample dataset
data = pd.DataFrame({'cars': ['benz', 'benz', 'benz',
'benz', 'bmw', 'bmw', 'bmw'],
'Price_in_million': [15, 12, 23, 23, 63, 34, 63]})
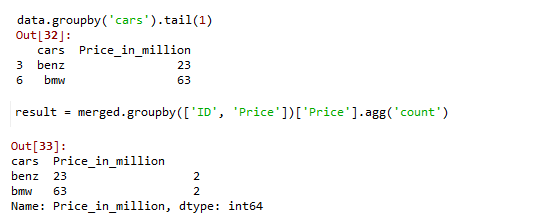
# perform inner merge with the grouped and original dataset
merged = pd.merge(data.groupby('cars').tail(1), data, how='inner')
# apply a count aggregated groupby function to
# get the no. of. occurrences of last value.
result = merged.groupby(['cars', 'Price_in_million'])[
'Price_in_million'].agg('count')
print(result)
输出:
方法四:使用 GroupBy、pandas Merge 和 Sum函数
我们也可以通过稍微改变上述方法得到相同的结果,使用last()函数而不是tail() ,如下所示,
例子:
在这个例子中,我们创建了一个带有汽车名称和价格的示例数据框,对汽车应用 groupby函数,并使用 last()函数找到每个组的最终元素,并在内部将分组数据集与原始数据集合并。现在比较合并列中的两个价格并创建一个 bool 数据类型的新列,其中价格匹配。现在使用 groupby函数来获取组的最后一个值重复的次数。
Python3
# import pandas package
import pandas as pd
# create a sample dataset
data = pd.DataFrame({'cars': ['benz', 'benz', 'benz',
'benz', 'bmw', 'bmw', 'bmw'],
'Price_in_million': [15, 12, 23, 23, 63, 34, 63]})
# computes the final value of each group
grouped = data.groupby('cars').last()
# Merge dataset named "data" with this result
data = data.merge(grouped, left_on='cars', right_index=True, how='inner')
# Now compare the merged columns for same price
# and create a new column of boolean values
# where prices match
data['count'] = data['Price_in_million_x'] == data['Price_in_million_y']
# Use groupby function to return the aggregated
# sum of count column where the price matches
data.groupby('cars')['count'].sum()
输出: