Python的时间序列数据可视化
时间序列是按时间顺序列出的一系列数据点。时间序列是一系列连续的等间隔时间点。时间序列分析包括分析时间序列数据的方法,以提取有意义的见解和其他有用的数据特征。时间序列数据分析在金融业、制药业、社交媒体公司、网络服务提供商、研究等众多行业中变得非常重要。要理解时间序列数据,可视化是必不可少的。没有可视化,任何类型的数据分析都是不完整的。因为一个好的可视化可以为数据提供有意义和有趣的见解。
做任何类型的数据分析数据集都是最重要也是最基本的要求。没有数据集,我们就无法进行分析。在这里,我们正在获取用于时间序列数据可视化的库存数据。单击此处查看完整的数据集。为了可视化时间序列数据,我们需要导入一些包:
Python3
import pandas as pd
import numpy as np
import matplotlib.pyplot as pltPython3
# reading the dataset using read_csv
df = pd.read_csv("stock_data.csv",
parse_dates=True,
index_col="Date")
# displaying the first five rows of dataset
df.head()Python3
# deleting column
df.drop(columns='Unnamed: 0')Python3
df['Volume'].plot()Python3
df.plot(subplots=True, figsize=(10, 12))Python3
# Resampling the time series data based on monthly 'M' frequency
df_month = df.resample("M").mean()
# using subplot
fig, ax = plt.subplots(figsize=(10, 6))
# plotting bar graph
ax.bar(df_month['2016':].index,
df_month.loc['2016':, "Volume"],
width=25, align='center')Python3
df.Low.diff(2).plot(figsize=(10, 6))Python3
df.High.diff(2).plot(figsize=(10, 6))Python3
df['Change'] = df.Close.div(df.Close.shift())
df['Change'].plot(figsize=(10, 8), fontsize=16)Python3
df['2017']['Change'].plot(figsize=(10, 6))现在通过创建数据框 df 加载数据集。
蟒蛇3
# reading the dataset using read_csv
df = pd.read_csv("stock_data.csv",
parse_dates=True,
index_col="Date")
# displaying the first five rows of dataset
df.head()
输出:
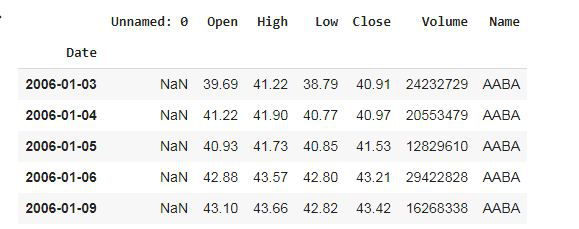
我们在 read_csv函数使用了 'parse_dates' 参数将 'Date' 列转换为 DatetimeIndex 格式。默认情况下,日期以字符串格式存储,这不是时间序列数据分析的正确格式。
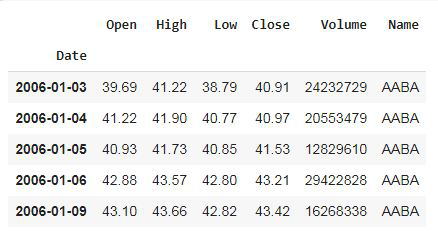
现在,从数据框中删除不需要的列,即“未命名:0”。
蟒蛇3
# deleting column
df.drop(columns='Unnamed: 0')
输出:
示例 1:为时间序列数据绘制简单的线图。
蟒蛇3
df['Volume'].plot()
输出:
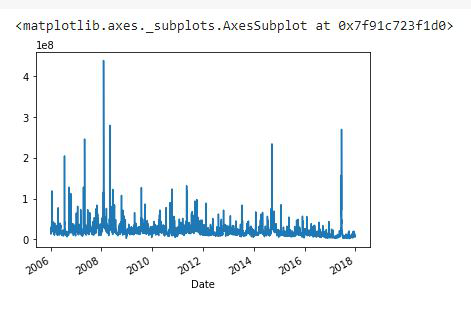
在这里,我们绘制了“体积”列数据。
示例 2:现在让我们使用 subplot 绘制所有其他列。
蟒蛇3
df.plot(subplots=True, figsize=(10, 12))
输出:

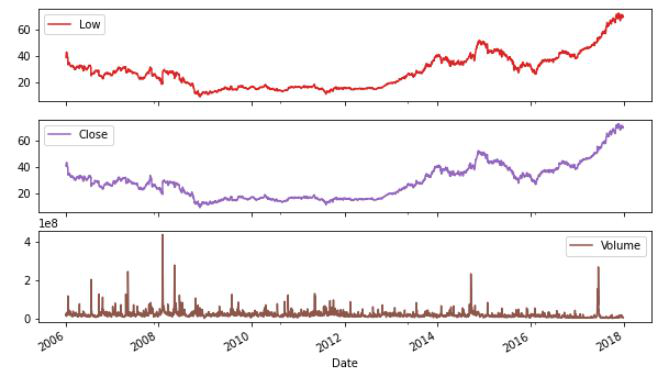
上面使用的线图非常适合显示季节性。
季节性:在时间序列数据中,季节性是在不到一年的特定固定时间间隔内发生的变化,例如每周、每月或每季度。
重采样:重采样是一种经济地使用数据样本来提高准确性和量化总体参数不确定性的方法。重新采样数月或数周并制作条形图是另一种非常简单且广泛使用的寻找季节性的方法。在这里,我们将制作 2016 年和 2017 年月份数据的条形图。
示例 3:
蟒蛇3
# Resampling the time series data based on monthly 'M' frequency
df_month = df.resample("M").mean()
# using subplot
fig, ax = plt.subplots(figsize=(10, 6))
# plotting bar graph
ax.bar(df_month['2016':].index,
df_month.loc['2016':, "Volume"],
width=25, align='center')
输出:

图中有 24 个条形,每个条形代表一个月。
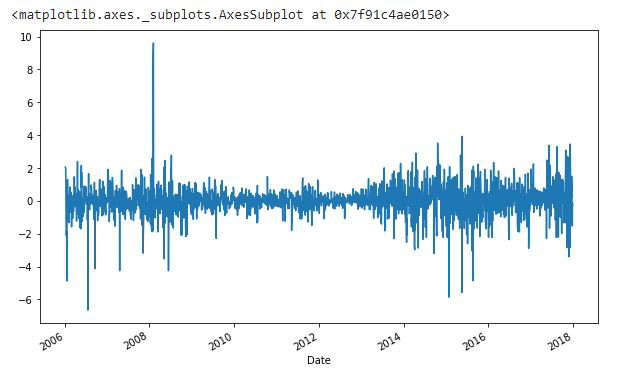
差分:差分用于使指定区间的值存在差异。默认情况下,它是 1,我们可以为绘图指定不同的值。它是最流行的去除数据趋势的方法。
示例 4:
蟒蛇3
df.Low.diff(2).plot(figsize=(10, 6))
输出:
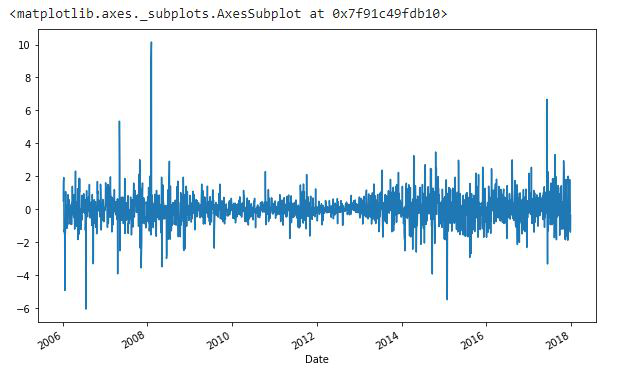
蟒蛇3
df.High.diff(2).plot(figsize=(10, 6))
输出:
绘制数据变化图
我们还可以绘制数据随时间发生的变化。有几种方法可以绘制数据的变化。
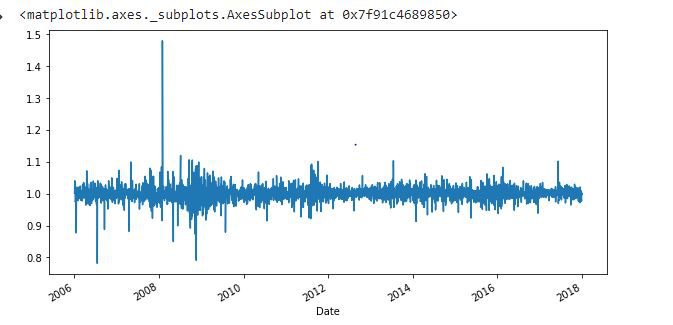
移位:移位函数可用于在指定时间间隔之前或之后移位数据。我们可以指定时间,它默认将数据移动一天。这意味着我们将获得前一天的数据。同时并排查看前一天的数据和今天的数据很有帮助。
蟒蛇3
df['Change'] = df.Close.div(df.Close.shift())
df['Change'].plot(figsize=(10, 8), fontsize=16)
在这段代码中, .div()函数有助于填充缺失的数据值。实际上, div() 意味着除法。如果我们取 df. div(6) 它将把 df 中的每个元素除以 6。我们这样做是为了避免由 'shift()' 操作创建的空值或缺失值。
在这里,我们采用了 .div(df.Close.shift()),它将 df 的每个值除以 df.Close.shift() 以删除空值。
输出:
我们还可以使用特定的时间间隔和绘图来更清晰地查看。这里我们只绘制了 2017 年的数据。
蟒蛇3
df['2017']['Change'].plot(figsize=(10, 6))
输出:
