使用Python修改 XML 文件
Python|修改/解析 XML
可扩展标记语言 (XML) 是一种标记语言,它定义了一组规则,用于以人类可读和机器可读的格式对文档进行编码。XML 的设计目标侧重于 Internet 上的简单性、通用性和可用性。它是一种文本数据格式,通过 Unicode 为不同的人类语言提供强大的支持。尽管 XML 的设计侧重于文档,但该语言被广泛用于表示任意数据结构,例如 Web 服务中使用的数据结构。
XML 是一种固有的分层数据格式,最自然的方式是用树来表示它。要执行解析、搜索、修改 XML 文件等任何操作,我们使用模块 xml.etree.ElementTree .它有两个类。 ElementTree将整个 XML 文档表示为有助于执行操作的树。 Element表示此树中的单个节点。整个文档的读取和写入在ElementTree级别完成。与单个 XML 元素及其子元素的交互在Element级别完成。
元素属性:Properties Description Tag String identifying what kind of data the element represents.
Can be accessed using elementname.tag.Number of Attributes Stored as a python dictionary.
Can be accesses by elementname.attrib.Text string String information regarding the element. Child string Optional child elements string information. Child Elements Number of child elements to a particular root.
解析:
我们可以从字符串或 XML 文档中解析 XML 数据。将xml.etree.ElementTree视为 ET。
1. ET.parse('Filename').getroot() -ET.parse('fname') - 创建一棵树,然后我们通过 .getroot() 提取根。
2. ET.fromstring(stringname) - 从 XML 数据字符串创建根。
示例 1:
XML 文档:
XML
Python3
# importing the module.
import xml.etree.ElementTree as ET
XMLexample_stored_in_a_string ='''
'''
# parsing directly.
tree = ET.parse('xmldocument.xml')
root = tree.getroot()
# parsing using the string.
stringroot = ET.fromstring(XMLexample_stored_in_a_string)
# printing the root.
print(root)
print(stringroot)Python3
import xml.etree.ElementTree as ET
XMLexample_stored_in_a_string ='''
1
2
3
'''
# parsing from the string.
root = ET.fromstring(XMLexample_stored_in_a_string)
# printing attributes of the root tags 'neighbor'.
for neighbor in root.iter('neighbor'):
print(neighbor.attrib)
# finding the state tag and their child attributes.
for state in root.findall('state'):
rank = state.find('rank').text
name = state.get('name')
print(name, rank)xml
Belgian Waffles
5.95
Two of our famous Belgian Waffles
with plenty of real maple syrup
650
Strawberry Belgian Waffles
7.95
Light Belgian waffles covered
with strawberries and whipped cream
900
Berry-Berry Belgian Waffles
8.95
Light Belgian waffles covered with
an assortment of fresh berries and whipped cream
900
French Toast
4.50
Thick slices made from our
homemade sourdough bread
600
Python3
import xml.etree.ElementTree as ET
mytree = ET.parse('xmldocument.xml.txt')
myroot = mytree.getroot()
# iterating through the price values.
for prices in myroot.iter('price'):
# updates the price value
prices.text = str(float(prices.text)+10)
# creates a new attribute
prices.set('newprices', 'yes')
# creating a new tag under the parent.
# myroot[0] here is the first food tag.
ET.SubElement(myroot[0], 'tasty')
for temp in myroot.iter('tasty'):
# giving the value as Yes.
temp.text = str('YES')
# deleting attributes in the xml.
# by using pop as attrib returns dictionary.
# removes the itemid attribute in the name tag of
# the second food tag.
myroot[1][0].attrib.pop('itemid')
# Removing the tag completely we use remove function.
# completely removes the third food tag.
myroot.remove(myroot[2])
mytree.write('output.xml')Python代码:
Python3
# importing the module.
import xml.etree.ElementTree as ET
XMLexample_stored_in_a_string ='''
'''
# parsing directly.
tree = ET.parse('xmldocument.xml')
root = tree.getroot()
# parsing using the string.
stringroot = ET.fromstring(XMLexample_stored_in_a_string)
# printing the root.
print(root)
print(stringroot)
输出:

输出示例1
元素方法:
1) Element.iter('tag') - 遍历所有子元素(子树元素)
2) Element.findall('tag') - 仅查找带有标签且是当前元素的直接子元素的元素。
3) Element.find('tag') - 查找具有特定标签的第一个子项。
4) Element.get('tag') - 访问元素属性。
5) Element.text - 给出元素的文本。
6) Element.attrib -返回所有存在的属性。
7) Element.tag - 返回元素名称。
示例 2:
Python3
import xml.etree.ElementTree as ET
XMLexample_stored_in_a_string ='''
1
2
3
'''
# parsing from the string.
root = ET.fromstring(XMLexample_stored_in_a_string)
# printing attributes of the root tags 'neighbor'.
for neighbor in root.iter('neighbor'):
print(neighbor.attrib)
# finding the state tag and their child attributes.
for state in root.findall('state'):
rank = state.find('rank').text
name = state.get('name')
print(name, rank)
输出:
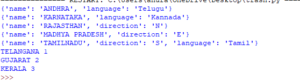
元素方法输出。
修改:
也可以通过 Element 方法修改 XML 文档。
方法:
1) Element.set('attrname', 'value') - 修改元素属性。
2) Element.SubElement(parent, new_childtag) - 在父标签下创建一个新的子标签。
3) Element.write('filename.xml') - 将 xml 树创建到另一个文件中。
4) Element.pop() -删除特定属性。
5) Element.remove() - 删除一个完整的标签。
示例 3:
XML 文档:
xml
Belgian Waffles
5.95
Two of our famous Belgian Waffles
with plenty of real maple syrup
650
Strawberry Belgian Waffles
7.95
Light Belgian waffles covered
with strawberries and whipped cream
900
Berry-Berry Belgian Waffles
8.95
Light Belgian waffles covered with
an assortment of fresh berries and whipped cream
900
French Toast
4.50
Thick slices made from our
homemade sourdough bread
600
Python代码:
Python3
import xml.etree.ElementTree as ET
mytree = ET.parse('xmldocument.xml.txt')
myroot = mytree.getroot()
# iterating through the price values.
for prices in myroot.iter('price'):
# updates the price value
prices.text = str(float(prices.text)+10)
# creates a new attribute
prices.set('newprices', 'yes')
# creating a new tag under the parent.
# myroot[0] here is the first food tag.
ET.SubElement(myroot[0], 'tasty')
for temp in myroot.iter('tasty'):
# giving the value as Yes.
temp.text = str('YES')
# deleting attributes in the xml.
# by using pop as attrib returns dictionary.
# removes the itemid attribute in the name tag of
# the second food tag.
myroot[1][0].attrib.pop('itemid')
# Removing the tag completely we use remove function.
# completely removes the third food tag.
myroot.remove(myroot[2])
mytree.write('output.xml')
输出:
