VGG-16 | CNN模型
ImageNet 大规模视觉识别挑战赛 (ILSVRC) 是一年一度的计算机视觉竞赛。每年,团队都在两项任务上竞争。第一个是检测来自200 个类别的图像中的对象,这称为对象定位。第二个是对图像进行分类,每个图像都标记有1000 个类别中的一个,这称为图像分类。 VGG 16 由牛津大学 Visual Geometry Group Lab 的 Karen Simonyan 和 Andrew Zisserman 于 2014 年在论文“VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION”中提出。该模型在 2014 年ILSVRC挑战赛中获得了上述类别的第一名和第二名。
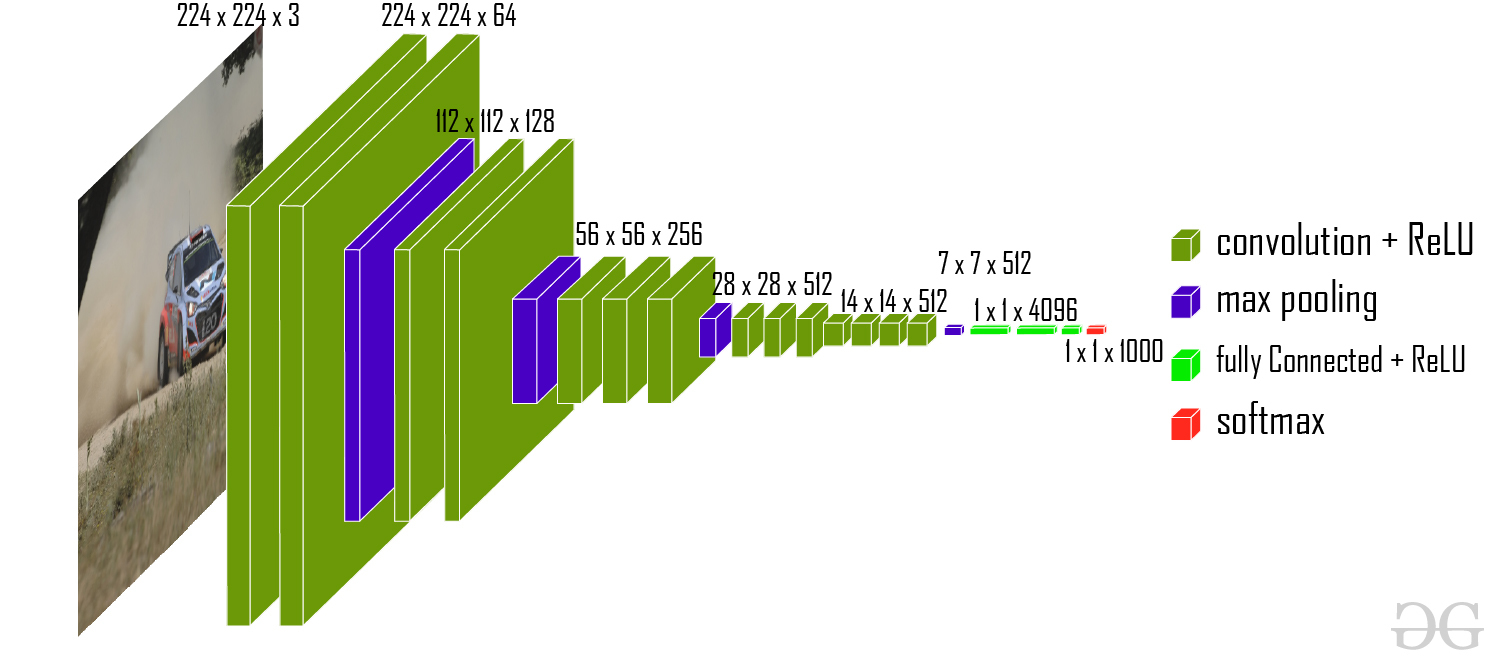
VGG-16 架构
该模型在 ImageNet 数据集上实现了92.7% 的 top-5测试准确率,该数据集包含属于 1000 个类别的1400万张图像。
客观的 :
ImageNet 数据集包含224*224固定大小的图像,并具有 RGB 通道。所以,我们有一个张量(224, 224, 3)作为我们的输入。该模型处理输入图像并输出1000 个值的向量。

该向量表示相应类别的分类概率。假设我们有一个模型,该模型预测图像属于 0 类,概率为0.1 ,属于 1类,概率为 0.05 ,属于2类,概率为0.05 ,属于3类,概率为 0.03 ,属于780 类,概率为 0.72 ,属于999类,概率为 0.05和所有其他与0的类。所以,这个分类向量将是:

为了确保这些概率加到1 ,我们使用了 softmax函数。这个 softmax函数定义为:

在此之后,我们将 5 个最可能的候选者放入向量中。

我们的ground truth向量定义如下:

然后我们定义我们的Error函数如下:


所以,这个例子的损失函数是:

所以,


因为,ground truth 中的所有类别都在 Predicted top-5 矩阵中,所以损失变为 0。
建筑学:
网络的输入是尺寸为(224, 224, 3)的图像。前两层有64个3*3过滤器大小和相同填充的通道。然后在步幅为(2, 2)的最大池层之后,两层具有 256 个滤波器大小和滤波器大小(3, 3)的卷积层。接下来是步幅为(2, 2)的最大池化层,与前一层相同。然后有2个filter size为(3, 3)的卷积层和256个filter。之后有2组3 个卷积层和一个最大池层。每个都有512 个(3, 3)大小的过滤器,具有相同的填充。然后将这个图像传递给两个卷积层的堆栈。在这些卷积层和最大池化层中,我们使用的过滤器大小为3*3 ,而不是 AlexNet 中的11*11和 ZF-Net 中的7*7 。在某些层中,它还使用1*1像素,用于操纵输入通道的数量。在每个卷积层之后都有一个1 像素的填充(相同的填充),以防止图像的空间特征。

VGG-16 架构图
经过卷积层和最大池化层的叠加,我们得到了一个(7, 7, 512)特征图。我们将这个输出展平,使其成为(1, 25088)特征向量。在这之后有3 个全连接层,第一层从最后一个特征向量中获取输入并输出(1, 4096)向量,第二层也输出一个大小为(1, 4096)的向量,但第三层为1000类 ILSVRC 挑战输出1000 个通道,然后在第三个全连接层的输出被传递到 softmax 层以对分类向量进行归一化。输出分类向量top-5分类后进行评价。所有隐藏层都使用 ReLU 作为其激活函数。 ReLU 的计算效率更高,因为它可以加快学习速度,并且还降低了梯度消失问题的可能性。
配置:
下表列出了不同的 VGG 架构。我们可以看到有 2 个版本的 VGG-16(C 和 D)。它们之间没有太大区别,除了一些卷积层之外,使用(3, 3)滤波器大小卷积代替(1, 1) 。这两个分别包含1.34亿和1.38亿个参数。
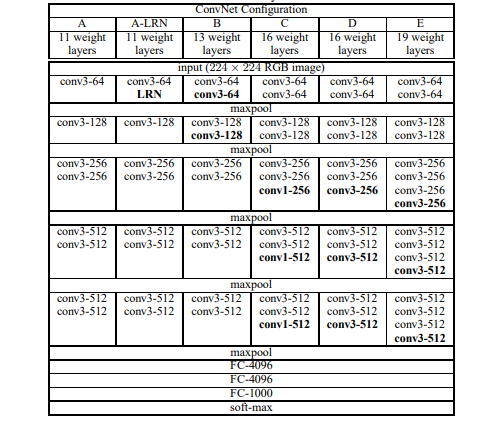
不同的 VGG 配置
图像中的对象定位:
为了执行定位,我们需要通过边界框位置候选来替换类分数。边界框位置由 4-D 矢量(中心坐标、高度、宽度)表示。定位架构有两种版本,一种是在不同候选者之间共享边界框(输出为4 个参数向量),另一种是特定于类的边界框(输出为4000 个参数向量)。本文在 VGG -16 (D) 架构上对这两种方法进行了实验。在这里,我们还需要将损失从分类损失更改为回归损失函数(例如 MSE),以惩罚预测损失与基本事实的偏差。
结果:
VGG-16 是 2014 年 ILSVRC 挑战赛中表现最好的架构之一。它在分类任务中以7.32%的 top-5 分类错误获得亚军(仅次于 GoogLeNet,分类错误率为 6.66% )。它也是本地化任务的获胜者,本地化错误率为 25.32% 。
VGG 16 的挑战:
参考:
- VGG 论文。
- ILSVRC 挑战。