理解 GoogLeNet 模型——CNN 架构
Google Net(或 Inception V1)是由 Google 研究(与多所大学合作)于 2014 年在题为“Going Deeper with Convolutions”的研究论文中提出的。该架构是 ILSVRC 2014 图像分类挑战赛的获胜者。与之前的获胜者 AlexNet(ILSVRC 2012 的获胜者)和 ZF-Net(ILSVRC 2013 的获胜者)相比,它的错误率显着降低,并且错误率明显低于 VGG(2014 年的亚军)。该架构使用了诸如架构中间的 1×1卷积和全局平均池化等技术。
谷歌网络的特点:
GoogLeNet 架构与以前最先进的架构(例如 AlexNet 和 ZF-Net)有很大不同。它使用了许多不同类型的方法,例如1×1卷积和全局平均池化,使其能够创建更深层次的架构。在架构中,我们将讨论其中一些方法:
- 1×1卷积:初始架构在其架构中使用 1×1 卷积。这些卷积用于减少架构的参数(权重和偏差)数量。通过减少参数,我们还增加了架构的深度。下面我们来看一个1×1卷积的例子:
- 例如,如果我们想在不使用 1×1卷积作为中间体的情况下执行具有 48 个过滤器的5×5 卷积:

- 操作总数: (14 x 14 x 48) x (5 x 5 x 480) = 112.9 M
- 使用 1×1 卷积:
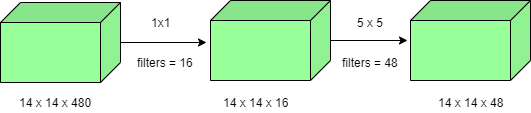
- (14 x 14 x 16) x (1 x 1 x 480) + (14 x 14 x 48) x (5 x 5 x 16) = 1.5M + 3.8M = 5.3M ,远小于 112.9M。
- 全球平均池:
在之前的架构中,例如 AlexNet,在网络的末端使用了全连接层。这些全连接层包含许多架构的大部分参数,这会导致计算成本的增加。
在 GoogLeNet 架构中,有一种称为全局平均池化的方法用于网络末端。该层采用7×7的特征图并将其平均为1×1 。这也将可训练参数的数量减少到 0,并将 top-1 的准确率提高了 0.6% - 初始模块:
Inception 模块不同于以前的架构,如 AlexNet、ZF-Net。在这种架构中,每一层都有一个固定的卷积大小。
在 Inception 模块中,输入和输出以并行方式执行的1×1、3×3、5×5卷积和3×3 最大池化堆叠在一起以生成最终输出。不同大小的卷积滤波器背后的想法将更好地处理多个尺度的对象。
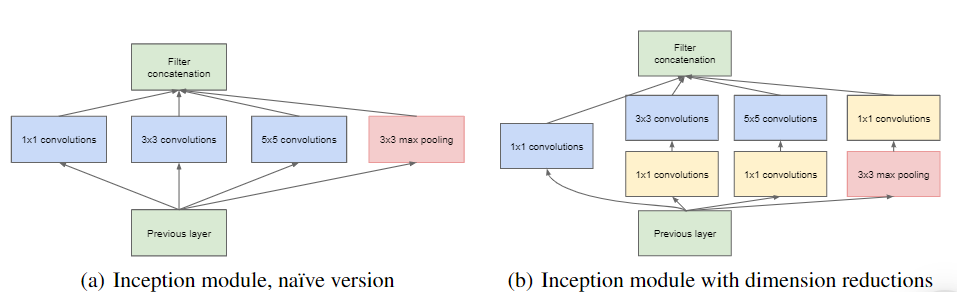
- 训练辅助分类器:
Inception 架构在架构中间使用了一些中间分类器分支,这些分支仅在训练期间使用。这些分支由步长为 3 的 5×5 平均池化层、具有128 个滤波器的 1×1卷积、两个具有 1024 个输出和 1000 个输出的全连接层以及一个 softmax 分类层组成。这些层产生的损失加到总损失中,权重为 0.3。这些层有助于解决梯度消失问题并提供正则化。
模型架构:
下面是 GoogLeNet 的逐层架构细节。 
整体架构为 22 层深。该架构旨在牢记计算效率。即使计算资源很少,该架构也可以在单个设备上运行。该架构还包含两个辅助分类器层,连接到 Inception (4a) 和 Inception (4d) 层的输出。
辅助分类器的架构细节如下:
- 过滤器大小为 5×5 且步幅为 3 的平均池化层。
- 具有 128 个滤波器的 1×1 卷积,用于降维和 ReLU 激活。
- 具有 1025 个输出和 ReLU 激活的全连接层
- Dropout 正则化,dropout 比率 = 0.7
- 具有 1000 个类输出的 softmax 分类器,类似于主要的 softmax 分类器。

这种架构采用 224 x 224大小的图像,带有 RGB 颜色通道。该架构中的所有卷积都使用整流线性单元 (ReLU) 作为其激活函数。
结果:
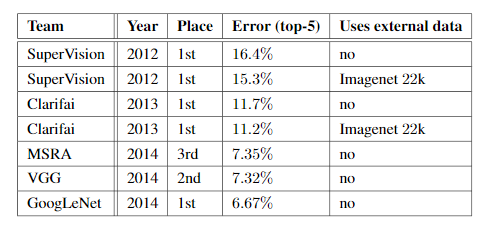
GoogLeNet在ILSRVRC 2014年获奖者服用1只发生在这两个类别的检测任务。它在分类任务中的 top-5 错误率为 6.67%。 6 个 GoogLeNet 的集合在 ImageNet 测试集上给出了 43.9% 的 mAP。

参考:
- 谷歌网络论文