Python Pandas – 扁平化嵌套 JSON
通过抓取从 Web 中提取的大部分数据都是 JSON 数据类型的形式,因为 JSON 是在 Web 应用程序中传输数据的首选数据类型。首选 JSON 的原因是,由于文件较小,因此在 HTTP 请求和响应中来回发送非常轻量级。
这样的 JSON 文件有时会因为具有不同的级别和层次结构而显得笨拙。这种原始格式的数据不能用于进一步处理。将 JSON 数据结构转换为 Pandas Dataframe 是一种普遍的做法,因为它可以帮助更方便地操作和可视化数据。在本文中,让我们考虑不同的嵌套 JSON 数据结构,并使用内置和自定义函数将它们展平。
Pandas 有一个很好的内置函数,称为json_normalize() ,可以将简单到中等半结构化的嵌套 JSON 结构扁平化为扁平表。
Syntax: pandas.json_normalize(data, errors=’raise’, sep=’.’, max_level=None)
Parameters:
- data – dict or list of dicts
- errors – {‘raise’, ‘ignore’}, default ‘raise’
- sep – str, default ‘.’ nested records will generate names separated by a specified separator.
- max_level – int, default None. Max number of levels(depth of dict) to normalize.
示例 1:
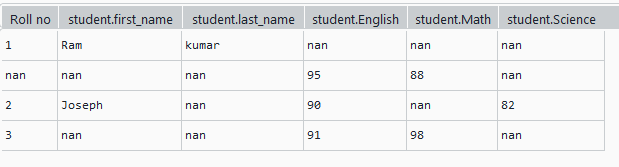
考虑一个嵌套字典列表,其中包含有关学生及其分数的详细信息,如图所示。在这个 JSON 数据结构上使用 pandas json_normalize 将其展平为一个平面表,如图所示
Python3
import pandas as pd
data = [
{"Roll no": 1,
"student": {"first_name": "Ram", "last_name": "kumar"}
},
{"student": {"English": "95", "Math": "88"}
},
{"Roll no": 2,
"student": {"first_name": "Joseph", "English": "90", "Science": "82"}
},
{"Roll no": 3,
"student": {"first_name": "abinaya", "last_name": "devi"},
"student": {"English": "91", "Math": "98"}
},
]
df = pd.json_normalize(data)
print(df)Python3
import pandas as pd
data = [
{
"id": 1,
"candidate": "Roberto mathews",
"health_index": {"bmi": 22, "blood_pressure": 130},
},
{"candidate": "Shane wade", "health_index": {"bmi": 28, "blood_pressure": 160}},
{
"id": 2,
"candidate": "Bruce tommy",
"health_index": {"bmi": 31, "blood_pressure": 190},
},
]
pd.json_normalize(data, max_level=0)Python3
import pandas as pd
data = [
{
"id": 1,
"candidate": "Roberto mathews",
"health_index": {"bmi": 22, "blood_pressure": 130},
},
{"candidate": "Shane wade", "health_index": {"bmi": 28, "blood_pressure": 160}},
{
"id": 2,
"candidate": "Bruce tommy",
"health_index": {"bmi": 31, "blood_pressure": 190},
},
]
pd.json_normalize(data, max_level=1)Python3
import pandas as pd
data = [
{
"company": "Google",
"tagline": "Dont be evil",
"management": {"CEO": "Sundar Pichai"},
"department": [
{"name": "Gmail", "revenue (bn)": 123},
{"name": "GCP", "revenue (bn)": 400},
{"name": "Google drive", "revenue (bn)": 600},
],
},
{
"company": "Microsoft",
"tagline": "Be What's Next",
"management": {"CEO": "Satya Nadella"},
"department": [
{"name": "Onedrive", "revenue (bn)": 13},
{"name": "Azure", "revenue (bn)": 300},
{"name": "Microsoft 365", "revenue (bn)": 300},
],
},
]
result = pd.json_normalize(
data, "department", ["company", "tagline", ["management", "CEO"]]
)
result输出:
示例 2:
现在让我们使用 max_level 选项将稍微复杂的 JSON 结构展平为平面表。对于这个例子,我们考虑了0 的 max_level ,这意味着只展平 JSON 的第一层,并且可以对结果进行试验。
在这里,我们考虑了 JSON 格式的不同个人健康记录的示例。
Python3
import pandas as pd
data = [
{
"id": 1,
"candidate": "Roberto mathews",
"health_index": {"bmi": 22, "blood_pressure": 130},
},
{"candidate": "Shane wade", "health_index": {"bmi": 28, "blood_pressure": 160}},
{
"id": 2,
"candidate": "Bruce tommy",
"health_index": {"bmi": 31, "blood_pressure": 190},
},
]
pd.json_normalize(data, max_level=0)
输出:
由于我们只使用了一层扁平化,第二层被保留为一个键值对,如图所示

示例 3:
现在让我们使用与上面相同的 JSON 数据结构,max_level 为 1,这意味着将 JSON 的前两个级别展平,可以对结果进行实验。
Python3
import pandas as pd
data = [
{
"id": 1,
"candidate": "Roberto mathews",
"health_index": {"bmi": 22, "blood_pressure": 130},
},
{"candidate": "Shane wade", "health_index": {"bmi": 28, "blood_pressure": 160}},
{
"id": 2,
"candidate": "Bruce tommy",
"health_index": {"bmi": 31, "blood_pressure": 190},
},
]
pd.json_normalize(data, max_level=1)
输出:
在这里,与前面的示例不同,我们将 JSON 的前两行展平,这为平面表提供了完整的结构。
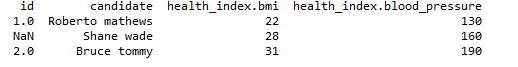
示例 4:
最后,让我们考虑一个深度嵌套的 JSON 结构,它可以通过将元参数传递给 json_normalize函数来转换为平面表,如下所示。
在这里,在下面的代码中,我们将必须解析 JSON 的时间顺序传递给平面表。在下面的代码中,我们首先建议解析部门键,然后是公司和标语,然后,我们将管理和 CEO 键作为嵌套列表传递,表明它们必须被解析为单个字段。
Python3
import pandas as pd
data = [
{
"company": "Google",
"tagline": "Dont be evil",
"management": {"CEO": "Sundar Pichai"},
"department": [
{"name": "Gmail", "revenue (bn)": 123},
{"name": "GCP", "revenue (bn)": 400},
{"name": "Google drive", "revenue (bn)": 600},
],
},
{
"company": "Microsoft",
"tagline": "Be What's Next",
"management": {"CEO": "Satya Nadella"},
"department": [
{"name": "Onedrive", "revenue (bn)": 13},
{"name": "Azure", "revenue (bn)": 300},
{"name": "Microsoft 365", "revenue (bn)": 300},
],
},
]
result = pd.json_normalize(
data, "department", ["company", "tagline", ["management", "CEO"]]
)
result
输出:
