毫升 |使用 sklearn 的虚拟分类器
虚拟分类器是一种分类器,它不会对数据产生任何洞察力,并且仅使用简单的规则对给定数据进行分类。分类器的行为完全独立于训练数据,因为训练数据中的趋势被完全忽略,而是使用其中一种策略来预测类标签。
它仅用作其他分类器的简单基线,即任何其他分类器都有望在给定数据集上表现更好。它对于确定类不平衡的数据集特别有用。它基于这样一种哲学,即任何分类问题的分析方法都应该比随机猜测方法更好。
以下是虚拟分类器用于预测类标签的一些策略 -
- 最频繁:分类器总是预测训练数据中最频繁的类标签。
- 分层:它通过尊重训练数据的类别分布来生成预测。它与“最频繁”策略不同,因为它将概率与每个数据点作为最频繁的类标签相关联。
- 均匀:它随机均匀地生成预测。
- 常量:分类器总是预测一个常量标签,主要用于对非多数类标签进行分类。
现在,让我们看看使用 sklearn 库的虚拟分类器的实现——
第 1 步:导入所需的库
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
import seaborn as sns
第 2 步:读取数据集
cd C:\Users\Dev\Desktop\Kaggle\Breast_Cancer
# Changing the read file location to the location of the file
df = pd.read_csv('data.csv')
y = df['diagnosis']
X = df.drop('diagnosis', axis = 1)
X = X.drop('Unnamed: 32', axis = 1)
X = X.drop('id', axis = 1)
# Separating the dependent and independent variable
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 0.3, random_state = 0)
# Splitting the data into training and testing data
第 3 步:训练虚拟模型
strategies = ['most_frequent', 'stratified', 'uniform', 'constant']
test_scores = []
for s in strategies:
if s =='constant':
dclf = DummyClassifier(strategy = s, random_state = 0, constant ='M')
else:
dclf = DummyClassifier(strategy = s, random_state = 0)
dclf.fit(X_train, y_train)
score = dclf.score(X_test, y_test)
test_scores.append(score)
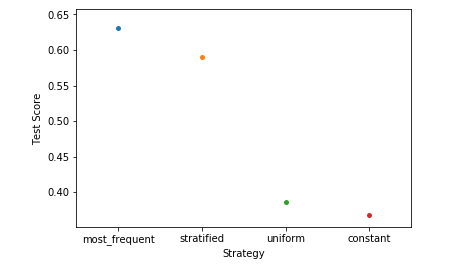
第 4 步:分析我们的结果
ax = sns.stripplot(strategies, test_scores);
ax.set(xlabel ='Strategy', ylabel ='Test Score')
plt.show()
 第 5 步:训练 KNN 模型
第 5 步:训练 KNN 模型
clf = KNeighborsClassifier(n_neighbors = 5)
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))

通过比较 KNN 分类器和虚拟分类器的得分,我们得出结论,KNN 分类器实际上是给定数据的一个很好的分类器。
在评论中写代码?请使用 ide.geeksforgeeks.org,生成链接并在此处分享链接。