SQL-锁表
SQL Server 是一种多功能数据库,它是在许多软件行业中使用最多的关系数据库。在本文中,让我们通过一些实际示例来了解 SQL Server 中的 SQL Lock 表。因为它满足原子性(A)、一致性(C)、隔离性(I)和持久性(D)要求,所以它被称为关系数据库。为了维护 ACID 机制,在 SQL Server 中,维护了一个锁。
通过使用 Azure Data Studio,让我们从创建数据库、创建表、锁定等开始了解 Lock 机制的概念。 Azure Data Studio 适用于 Windows 10、Mac 和 Linux 环境。它可以从这里安装。
数据库创建:
创建数据库的命令。这里 GEEKSFORGEEKS 是数据库名称。
--CREATE DATABASE ; 创建数据库 GEEKSFORGEEKS:
使数据库处于活动状态
USE GEEKSFORGEEKS;
数据库激活后,将在顶部显示数据库名称
将表添加到数据库:
使用主键创建表。这里 ID 是一个 PRIMARY KEY 意味着每个作者都有自己的 ID
CREATE TABLE Authors (
ID INT NOT NULL PRIMARY KEY,
,
..........
); 如果明确指定了“NOT NULL”,则该列应具有值。如果未指定,则默认为“NULL”。

在“GEEKSFORGEEKS”数据库下创建“Authors”命名表
在表中插入行:
会有一些场景,例如我们可以将所有列或少数列值添加到表中。原因是默认情况下某些列可能需要空值。
示例 1:
INSERT INTO (column1, column2, column3, ...) VALUES (value1, value2, value3, ...); 在这里,我们考虑了提到的列,因此上述查询仅插入了它们所需的值。
示例 2:
INSERT INTO VALUES (value1, value2, value3, ...); 这里我们没有指定任何列意味着需要插入所有列的所有值。
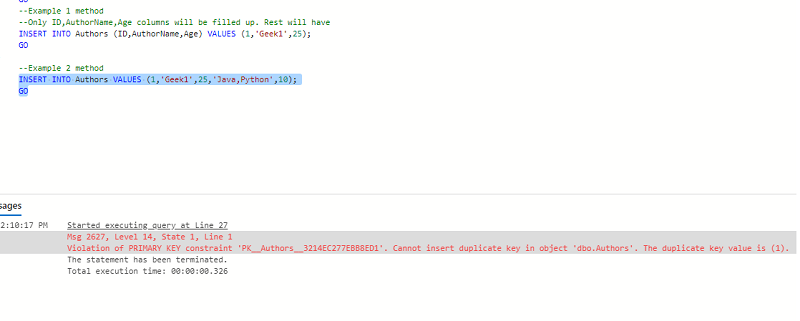
Violation of PRIMARY KEY constraint 'PK__Authors__3214EC277EBB8ED1'.
Cannot insert duplicate key in object 'dbo.Authors'. The duplicate key value is (1).上面截图中出现的上述错误表明“ID”列是唯一的,不应有重复的值
现在,让我们更正并使用以下命令查询表:
SELECT * FROM 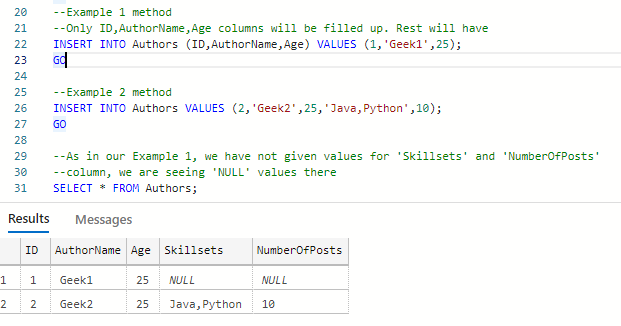
清除应用示例 1 和示例 2 方法的输出
据观察,第 1 行在 'Skillsets' 和 'NumberOfPosts' 列的位置具有 'Null' 值。原因是我们没有为这些列指定值,它采用了默认的 Null 值。
- SQL 锁:
SQL Server 是关系型数据库,数据一致性是一个重要的机制,可以通过 SQL Locks 来实现。 SQL Server 中的锁在事务开始时建立,并在事务结束时释放。那里有不同类型的锁。
- Shared (S) Locks:当需要读取对象时,会出现这种类型的锁,但这并不有害。
- 独占(X)锁:它阻止其他事务,如插入/更新/删除等,因此不能对锁定的对象进行修改。
- 更新(U)锁:或多或少类似于排他锁,但这里的操作可以被视为“读阶段”和“写阶段”。特别是在读取阶段,其他事务被阻止。
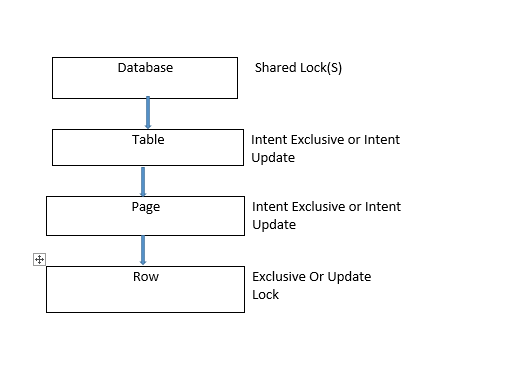
- 意向锁:当 SQL Server 在行上拥有共享 (S) 锁或排他 (X) 锁时,意向锁就在表上。
- 常规意图锁:意图独占(IX)、意图共享(IS)和意图更新(IU)。
- 转换锁:与意图独占共享 (SIX)、与意图更新共享 (SIU) 和意图独占更新 (UIX)。
锁层次结构从数据库开始,然后是表,然后是行。
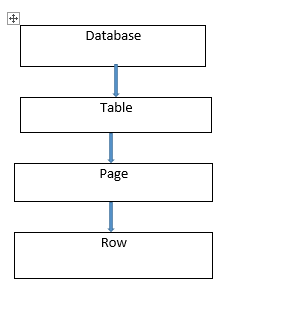
数据库级别的共享锁非常重要,因为它可以防止删除数据库或通过正在使用的数据库恢复数据库备份。
发出“SELECT”语句时发生锁定。

在 DML 语句执行期间,即在插入/更新/删除期间。
通过我们的示例,让我们看看锁定机制。
--Let us create an open transaction and analyze the locked resource.
BEGIN TRAN
Let us update the Skillsets column for ID = 1
UPDATE Authors SET Skillsets='Java,Android,PHP' where ID=1
select @@SPID
select * from sys.dm_tran_locks WHERE request_session_id=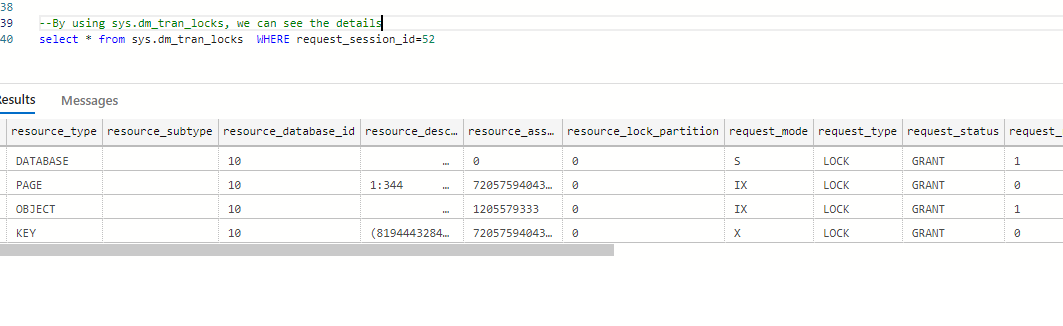
让我们在表中插入更多记录(近 100 条记录),然后使用事务,让我们更新几列并并行应用选择查询
--Let us create an open transaction and analyze the locked resources.
BEGIN TRAN
--Let us update the Skillsets when ID < 20
UPDATE Authors SET Skillsets='Java,Android,R Programming' where ID < 20
--Let us update the Skillsets when ID >= 25
UPDATE Authors SET Skillsets='Android,IOS,R Programming' where ID >= 25
--Other DML statements like Update/Delete. This statement must be taking a long time
--(if there are huge updates are happening) as previous statement itself
--is either not committed or rolled back yet
SELECT * FROM Authors;
select @@SPID
实际上,当较早的命令事务尚未完成时(如果有大量记录,至少有 100 条记录)并且在每一行和完成之前都在进行更新,如果我们正在继续执行另一组命令,例如“选择”
然后状态可能是“等待”(正在执行的查询)和“暂停”(暂停的查询)
如何克服到目前为止运行的过程?
KILL -> Kill the session (或)在事务内部,在每次查询之后,应用
COMMIT -> TO COMMIT THE CHANGES
ROLLBACK -> TO ROLLBACK THE CHANGES通过执行此过程,我们正在强制执行操作以提交或回滚(取决于要求,必须执行)
但是除非我们知道整个过程是否需要,否则我们无法提交或回滚事务。
替代方式:
通过将 NOLOCK 与 SELECT QUERY 一起使用,我们可以克服
SELECT * FROM Authors WITH (NOLOCK);对于使用 sp_who2 命令的 SELECT 语句状态。查询运行时无需等待 UPDATE 事务成功完成并释放对表的锁定,
SELECT * FROM Authors WITH (READUNCOMMITTED);
--This way also we can do结论 :
SQL 锁对于任何 RDBMS 都非常重要。 SQL Server 以上述方式处理它们。