在 PySpark 中合并两个具有不同列数的 DataFrame
在本文中,我们将讨论如何在Python中的 PySpark 中对具有不同列数的两个数据帧执行联合。
让我们考虑第一个数据帧
这里我们有 3 列,分别命名为 id、name 和 address。
Python3
# importing module
import pyspark
# import when and lit function
from pyspark.sql.functions import when, lit
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "kakumanu"],
["2", "ojaswi", "hyd"],
["3", "rohith", "delhi"],
["4", "sridevi", "kakumanu"],
["5", "bobby", "guntur"]]
# specify column names
columns = ['ID', 'NAME', 'Address']
# creating a dataframe from the lists of data
dataframe1 = spark.createDataFrame(data, columns)
# display
dataframe1.show()Python3
# importing module
import pyspark
# import when and lit function
from pyspark.sql.functions import when, lit
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", 23],
["2", 21],
["3", 32],
]
# specify column names
columns = ['ID', 'Age']
# creating a dataframe from the lists of data
dataframe2 = spark.createDataFrame(data, columns)
# display
dataframe2.show()Python3
# importing module
import pyspark
# import lit function
from pyspark.sql.functions import lit
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "kakumanu"],
["2", "ojaswi", "hyd"],
["3", "rohith", "delhi"],
["4", "sridevi", "kakumanu"],
["5", "bobby", "guntur"]]
# specify column names
columns = ['ID', 'NAME', 'Address']
# creating a dataframe from the lists of data
dataframe1 = spark.createDataFrame(data, columns)
# list of employee data
data = [["1", 23],
["2", 21],
["3", 32],
]
# specify column names
columns = ['ID', 'Age']
# creating a dataframe from the lists of data
dataframe2 = spark.createDataFrame(data, columns)
# add columns in dataframe1 that are missing from dataframe2
for column in [column for column in dataframe2.columns
if column not in dataframe1.columns]:
dataframe1 = dataframe1.withColumn(column, lit(None))
# add columns in dataframe2 that are missing from dataframe1
for column in [column for column in dataframe1.columns
if column not in dataframe2.columns]:
dataframe2 = dataframe2.withColumn(column, lit(None))
# now see the columns of dataframe1
print(dataframe1.columns)
# now see the columns of dataframe2
print(dataframe2.columns)Python3
# importing module
import pyspark
# import lit function
from pyspark.sql.functions import lit
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "kakumanu"],
["2", "ojaswi", "hyd"],
["3", "rohith", "delhi"],
["4", "sridevi", "kakumanu"],
["5", "bobby", "guntur"]]
# specify column names
columns = ['ID', 'NAME', 'Address']
# creating a dataframe from the lists of data
dataframe1 = spark.createDataFrame(data, columns)
# list of employee data
data = [["1", 23],
["2", 21],
["3", 32],
]
# specify column names
columns = ['ID', 'Age']
# creating a dataframe from the lists of data
dataframe2 = spark.createDataFrame(data, columns)
# add columns in dataframe1 that are missing from dataframe2
for column in [column for column in dataframe2.columns
if column not in dataframe1.columns]:
dataframe1 = dataframe1.withColumn(column, lit(None))
# add columns in dataframe2 that are missing from dataframe1
for column in [column for column in dataframe1.columns
if column not in dataframe2.columns]:
dataframe2 = dataframe2.withColumn(column, lit(None))
# perform union
dataframe1.union(dataframe2).show()Python3
# importing module
import pyspark
# import lit function
from pyspark.sql.functions import lit
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "kakumanu"],
["2", "ojaswi", "hyd"],
["3", "rohith", "delhi"],
["4", "sridevi", "kakumanu"],
["5", "bobby", "guntur"]]
# specify column names
columns = ['ID', 'NAME', 'Address']
# creating a dataframe from the lists of data
dataframe1 = spark.createDataFrame(data, columns)
# list of employee data
data = [["1", 23],
["2", 21],
["3", 32],
]
# specify column names
columns = ['ID', 'Age']
# creating a dataframe from the lists of data
dataframe2 = spark.createDataFrame(data, columns)
# add columns in dataframe1 that are missing
# from dataframe2
for column in [column for column in dataframe2.columns\
if column not in dataframe1.columns]:
dataframe1 = dataframe1.withColumn(column, lit(None))
# add columns in dataframe2 that are missing
# from dataframe1
for column in [column for column in dataframe1.columns \
if column not in dataframe2.columns]:
dataframe2 = dataframe2.withColumn(column, lit(None))
# perform unionAll
dataframe1.unionAll(dataframe2).show()Python3
# importing module
import pyspark
# import lit function
from pyspark.sql.functions import lit
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "kakumanu"],
["2", "ojaswi", "hyd"],
["3", "rohith", "delhi"],
["4", "sridevi", "kakumanu"],
["5", "bobby", "guntur"]]
# specify column names
columns = ['ID', 'NAME', 'Address']
# creating a dataframe from the lists of data
dataframe1 = spark.createDataFrame(data, columns)
# list of employee data
data = [["1", 23],
["2", 21],
["3", 32],
]
# specify column names
columns = ['ID', 'Age']
# creating a dataframe from the lists of data
dataframe2 = spark.createDataFrame(data, columns)
# add columns in dataframe1 that are missing from dataframe2
for column in [column for column in dataframe2.columns \
if column not in dataframe1.columns]:
dataframe1 = dataframe1.withColumn(column, lit(None))
# add columns in dataframe2 that are missing from dataframe1
for column in [column for column in dataframe1.columns \
if column not in dataframe2.columns]:
dataframe2 = dataframe2.withColumn(column, lit(None))
# perform unionByName
dataframe1.unionByName(dataframe2).show()输出:

让我们考虑第二个数据框
在这里,我们将创建具有 2 列的数据框
Python3
# importing module
import pyspark
# import when and lit function
from pyspark.sql.functions import when, lit
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", 23],
["2", 21],
["3", 32],
]
# specify column names
columns = ['ID', 'Age']
# creating a dataframe from the lists of data
dataframe2 = spark.createDataFrame(data, columns)
# display
dataframe2.show()
输出:
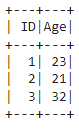
我们不能执行联合操作,因为列不同,所以我们必须添加缺少的列。这里在第一个数据帧 (dataframe1) 中,列 ['ID', 'NAME', 'Address'] 和第二个数据帧 (dataframe2) 列是 ['ID','Age']。
现在我们必须将 Age 列添加到第一个数据帧中,并将 NAME 和地址添加到第二个数据帧中,我们可以使用 lit()函数来做到这一点。此函数在 pyspark.sql.functions 中可用,用于添加具有值的列。在这里,我们将使用 None 添加一个值。
Syntax:
for column in [column for column in dataframe1.columns if column not in dataframe2.columns]:
dataframe2 = dataframe2.withColumn(column, lit(None))
where,
- dataframe1 is the firstdata frame
- dataframe2 is the second dataframe
示例:向两个数据框添加缺失的列
Python3
# importing module
import pyspark
# import lit function
from pyspark.sql.functions import lit
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "kakumanu"],
["2", "ojaswi", "hyd"],
["3", "rohith", "delhi"],
["4", "sridevi", "kakumanu"],
["5", "bobby", "guntur"]]
# specify column names
columns = ['ID', 'NAME', 'Address']
# creating a dataframe from the lists of data
dataframe1 = spark.createDataFrame(data, columns)
# list of employee data
data = [["1", 23],
["2", 21],
["3", 32],
]
# specify column names
columns = ['ID', 'Age']
# creating a dataframe from the lists of data
dataframe2 = spark.createDataFrame(data, columns)
# add columns in dataframe1 that are missing from dataframe2
for column in [column for column in dataframe2.columns
if column not in dataframe1.columns]:
dataframe1 = dataframe1.withColumn(column, lit(None))
# add columns in dataframe2 that are missing from dataframe1
for column in [column for column in dataframe1.columns
if column not in dataframe2.columns]:
dataframe2 = dataframe2.withColumn(column, lit(None))
# now see the columns of dataframe1
print(dataframe1.columns)
# now see the columns of dataframe2
print(dataframe2.columns)
输出:
['ID', 'NAME', 'Address', 'Age']
['ID', 'Age', 'NAME', 'Address']示例 1:使用 union()
现在我们可以使用 union()函数来执行联合。此函数将连接两个数据帧。
Syntax: dataframe1.union(dataframe2)
例子:
Python3
# importing module
import pyspark
# import lit function
from pyspark.sql.functions import lit
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "kakumanu"],
["2", "ojaswi", "hyd"],
["3", "rohith", "delhi"],
["4", "sridevi", "kakumanu"],
["5", "bobby", "guntur"]]
# specify column names
columns = ['ID', 'NAME', 'Address']
# creating a dataframe from the lists of data
dataframe1 = spark.createDataFrame(data, columns)
# list of employee data
data = [["1", 23],
["2", 21],
["3", 32],
]
# specify column names
columns = ['ID', 'Age']
# creating a dataframe from the lists of data
dataframe2 = spark.createDataFrame(data, columns)
# add columns in dataframe1 that are missing from dataframe2
for column in [column for column in dataframe2.columns
if column not in dataframe1.columns]:
dataframe1 = dataframe1.withColumn(column, lit(None))
# add columns in dataframe2 that are missing from dataframe1
for column in [column for column in dataframe1.columns
if column not in dataframe2.columns]:
dataframe2 = dataframe2.withColumn(column, lit(None))
# perform union
dataframe1.union(dataframe2).show()
输出:

示例 2:使用 unionAll()
Syntax: dataframe1.unionAll(dataframe2)
Python3
# importing module
import pyspark
# import lit function
from pyspark.sql.functions import lit
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "kakumanu"],
["2", "ojaswi", "hyd"],
["3", "rohith", "delhi"],
["4", "sridevi", "kakumanu"],
["5", "bobby", "guntur"]]
# specify column names
columns = ['ID', 'NAME', 'Address']
# creating a dataframe from the lists of data
dataframe1 = spark.createDataFrame(data, columns)
# list of employee data
data = [["1", 23],
["2", 21],
["3", 32],
]
# specify column names
columns = ['ID', 'Age']
# creating a dataframe from the lists of data
dataframe2 = spark.createDataFrame(data, columns)
# add columns in dataframe1 that are missing
# from dataframe2
for column in [column for column in dataframe2.columns\
if column not in dataframe1.columns]:
dataframe1 = dataframe1.withColumn(column, lit(None))
# add columns in dataframe2 that are missing
# from dataframe1
for column in [column for column in dataframe1.columns \
if column not in dataframe2.columns]:
dataframe2 = dataframe2.withColumn(column, lit(None))
# perform unionAll
dataframe1.unionAll(dataframe2).show()
输出:

示例 3:使用 unionByName
我们还可以执行 unionByName,这将按名称连接数据帧。
Syntax: dataframe1.unionByName(dataframe2)
例子:
Python3
# importing module
import pyspark
# import lit function
from pyspark.sql.functions import lit
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [["1", "sravan", "kakumanu"],
["2", "ojaswi", "hyd"],
["3", "rohith", "delhi"],
["4", "sridevi", "kakumanu"],
["5", "bobby", "guntur"]]
# specify column names
columns = ['ID', 'NAME', 'Address']
# creating a dataframe from the lists of data
dataframe1 = spark.createDataFrame(data, columns)
# list of employee data
data = [["1", 23],
["2", 21],
["3", 32],
]
# specify column names
columns = ['ID', 'Age']
# creating a dataframe from the lists of data
dataframe2 = spark.createDataFrame(data, columns)
# add columns in dataframe1 that are missing from dataframe2
for column in [column for column in dataframe2.columns \
if column not in dataframe1.columns]:
dataframe1 = dataframe1.withColumn(column, lit(None))
# add columns in dataframe2 that are missing from dataframe1
for column in [column for column in dataframe1.columns \
if column not in dataframe2.columns]:
dataframe2 = dataframe2.withColumn(column, lit(None))
# perform unionByName
dataframe1.unionByName(dataframe2).show()
输出:
