使用正则表达式替换 Pandas 数据框中的值
在处理大量数据时,它通常包含文本数据,而且在许多情况下,这些文本一点也不漂亮。通常是非常混乱的形式,我们需要清理这些数据,然后才能对文本数据做任何有意义的事情。大多数情况下,文本语料库是如此之大,以至于我们无法手动列出我们想要替换的所有文本。因此,在这些情况下,我们使用正则表达式来处理这些具有某种模式的数据。
我们在上一篇文章中已经讨论过如何替换数据框中的一些已知字符串值。在这篇文章中,我们将使用正则表达式来替换具有某种模式的字符串。
问题 #1:给您一个数据框,其中包含有关不同城市的各种事件的详细信息。对于以关键字“New”或“new”开头的城市,将其更改为“New_”。
解决方案:我们将使用正则表达式来检测这些名称,然后我们将使用Dataframe.replace()函数来替换这些名称。
# importing pandas as pd
import pandas as pd
# Let's create a Dataframe
df = pd.DataFrame({'City':['New York', 'Parague', 'New Delhi', 'Venice', 'new Orleans'],
'Event':['Music', 'Poetry', 'Theatre', 'Comedy', 'Tech_Summit'],
'Cost':[10000, 5000, 15000, 2000, 12000]})
# Let's create the index
index_ = [pd.Period('02-2018'), pd.Period('04-2018'),
pd.Period('06-2018'), pd.Period('10-2018'), pd.Period('12-2018')]
# Set the index
df.index = index_
# Let's print the dataframe
print(df)
输出 : 
现在我们将编写正则表达式来匹配字符串,然后我们将使用Dataframe.replace()函数来替换这些名称。
# replace the matching strings
df_updated = df.replace(to_replace ='[nN]ew', value = 'New_', regex = True)
# Print the updated dataframe
print(df_updated)
输出 : 
正如我们在输出中看到的,旧字符串已成功替换为新字符串。问题 #2:给您一个数据框,其中包含有关不同城市的各种事件的详细信息。某些城市的名称包含一些额外的细节,括在括号中。搜索此类名称并删除其他详细信息。
解决方案:对于这个任务,我们将使用正则表达式编写自己的自定义函数来识别和更新这些城市的名称。此外,我们将使用Dataframe.apply()函数将我们自定义的函数应用于列的每个值。
# importing pandas as pd
import pandas as pd
# Let's create a Dataframe
df = pd.DataFrame({'City':['New York (City)', 'Parague', 'New Delhi (Delhi)', 'Venice', 'new Orleans'],
'Event':['Music', 'Poetry', 'Theatre', 'Comedy', 'Tech_Summit'],
'Cost':[10000, 5000, 15000, 2000, 12000]})
# Let's create the index
index_ = [pd.Period('02-2018'), pd.Period('04-2018'),
pd.Period('06-2018'), pd.Period('10-2018'), pd.Period('12-2018')]
# Set the index
df.index = index_
# Let's print the dataframe
print(df)
输出 : 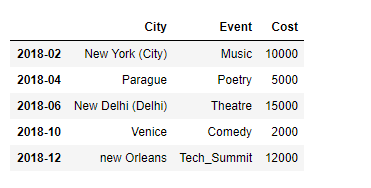
现在我们将编写自己的自定义函数来匹配城市名称中的描述。
# Importing re package for using regular expressions
import re
# Function to clean the names
def Clean_names(City_name):
# Search for opening bracket in the name followed by
# any characters repeated any number of times
if re.search('\(.*', City_name):
# Extract the position of beginning of pattern
pos = re.search('\(.*', City_name).start()
# return the cleaned name
return City_name[:pos]
else:
# if clean up needed return the same name
return City_name
# Updated the city columns
df['City'] = df['City'].apply(Clean_names)
# Print the updated dataframe
print(df)
输出 : 