如何使用 Pandas 显示数据框中的所有行
在本文中,我们将讨论如何在Python中使用 Pandas 显示数据框中的所有行。
当您尝试打印超过要显示的预定义行数和列数的大型数据框时,结果将被截断。请参阅以下示例以获得更好的理解。
Python3
# importing numpy library
import pandas as pd
# importing diabetes dataset from sklearn
from sklearn.datasets import load_diabetes
# Loading diabetes dataset
data = load_diabetes()
# storing as data frame
dataframe = pd.DataFrame(data.data, columns=data.feature_names)
# printing data frame
print(dataframe)Python3
# Display all rows from data frame using pandas
# importing numpy library
import pandas as pd
# importing iris dataset from sklearn
from sklearn.datasets import load_iris
# Loading iris dataset
data = load_iris()
# storing as data frame
dataframe = pd.DataFrame(data.data,columns = data.feature_names)
# Convert entire data frame as string and print
print(dataframe.to_string())Python3
# Display all rows from data frame using pandas
# importing numpy library
import pandas as pd
# importing iris dataset from sklearn
from sklearn.datasets import load_iris
# Loading iris dataset
data = load_iris()
# Default value of display.max_rows is 10 so at max
# 10 rows will be printed. Set it None to display
# all rows in the dataframe
pd.set_option('display.max_rows', None)
# storing the dataset as data frame
dataframe = pd.DataFrame(data.data,columns = data.feature_names)
# printing data frame
print(dataframe)Python3
# Display all rows from data frame using pandas
# importing numpy library
import pandas as pd
# importing iris dataset from sklearn
from sklearn.datasets import load_iris
# Loading iris dataset
data = load_iris()
# storing the dataset as data frame
dataframe = pd.DataFrame(data.data, columns=data.feature_names)
# Convert entire data frame as markdown and print
print(dataframe.to_markdown())Python3
# Display all rows from data frame using pandas
# importing numpy library
import pandas as pd
# importing iris dataset from sklearn
from sklearn.datasets import load_iris
# Loading iris dataset
data = load_iris()
# storing the dataset as data frame
dataframe = pd.DataFrame(data.data, columns=data.feature_names)
# The scope of these changes
# are local with systems to with statement.
with pd.option_context('display.max_rows', None,):
print(dataframe)输出:
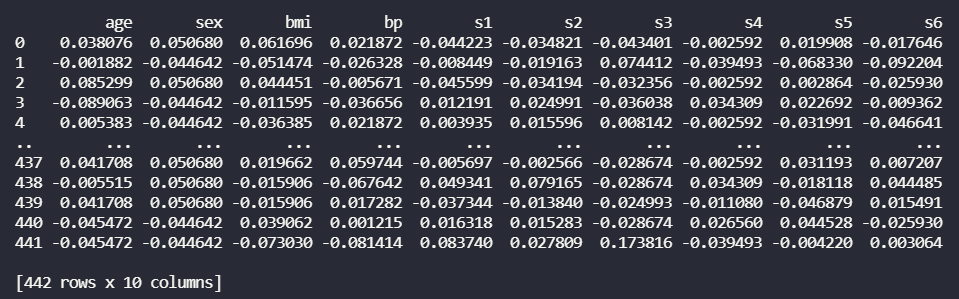
在上面的输出中,您可以看到总行数为 442,但它只显示了 10 行。这是由于 pandas 库中的默认设置仅为 10 行(默认行数可能会因系统而异)。现在我们将看到如何使用 pandas 显示数据框中的所有行。
方法一:使用 to_string()
此方法是显示数据框中所有行的最简单方法,但不建议用于非常大的数据集(以百万计),因为它将整个数据框转换为单个字符串。尽管这适用于大小为数千的数据集。
句法 :
DataFrame.to_string()代码:
Python3
# Display all rows from data frame using pandas
# importing numpy library
import pandas as pd
# importing iris dataset from sklearn
from sklearn.datasets import load_iris
# Loading iris dataset
data = load_iris()
# storing as data frame
dataframe = pd.DataFrame(data.data,columns = data.feature_names)
# Convert entire data frame as string and print
print(dataframe.to_string())
输出:

在这里,在输出中,您可以看到它显示了数据框中的所有行。但是这种方法不适用于大数据帧,因为这会将整个数据帧转换为字符串,因此可能会出现任何内存错误。
方法二:使用 set_option()
Pandas 提供了一个操作系统来自定义行为和显示。此方法允许我们将显示配置为显示完整的数据框而不是截断的数据框。 pandas 提供了一个函数set_option() 来显示数据框的所有行。 display.max_rows 表示 pandas 在显示数据框时将显示的最大行数。
max_rows 的默认值为 10。如果设置为“无”,则表示数据框的所有行。将 display.max_rows 的值设置为 None 并将其传递给 set_option ,这将显示数据框中的所有行。
句法 :
pandas.set_option('display.max_rows', None)代码:
Python3
# Display all rows from data frame using pandas
# importing numpy library
import pandas as pd
# importing iris dataset from sklearn
from sklearn.datasets import load_iris
# Loading iris dataset
data = load_iris()
# Default value of display.max_rows is 10 so at max
# 10 rows will be printed. Set it None to display
# all rows in the dataframe
pd.set_option('display.max_rows', None)
# storing the dataset as data frame
dataframe = pd.DataFrame(data.data,columns = data.feature_names)
# printing data frame
print(dataframe)
输出:
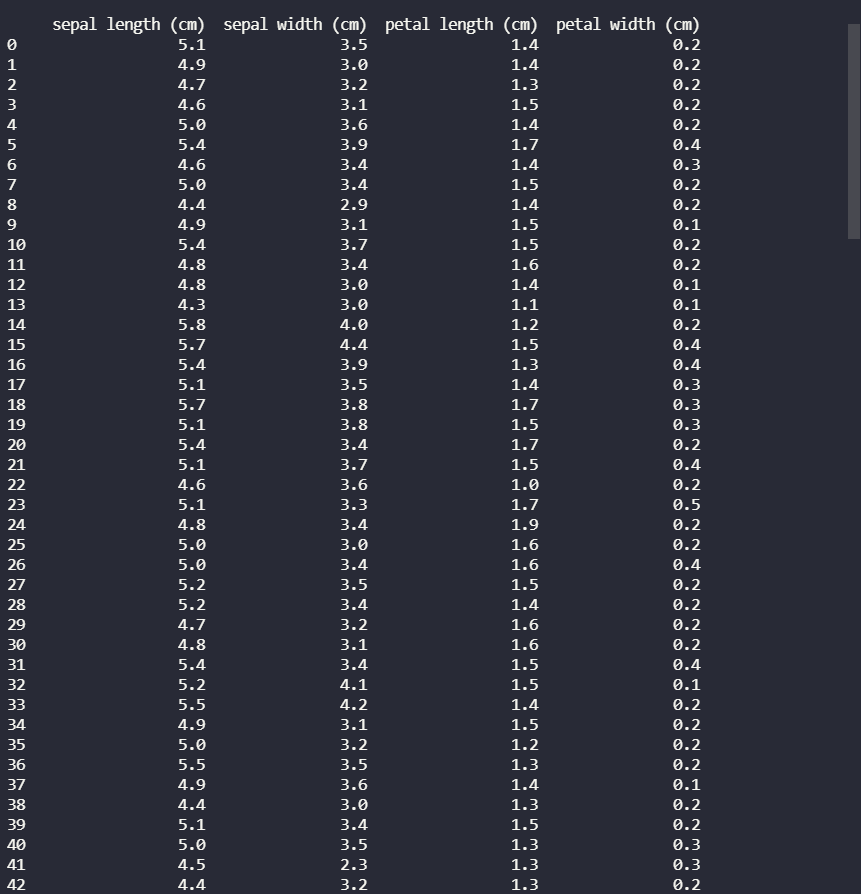
方法三:使用 to_markdown()
此方法将数据框转换为字符串对象,并向数据框添加样式和格式。这与 to_string() 方法相同,但添加了样式和格式。 to_markdown() 将使用样式和格式显示数据框中的所有行。
句法 :
DataFrame.to_markdown()代码:
Python3
# Display all rows from data frame using pandas
# importing numpy library
import pandas as pd
# importing iris dataset from sklearn
from sklearn.datasets import load_iris
# Loading iris dataset
data = load_iris()
# storing the dataset as data frame
dataframe = pd.DataFrame(data.data, columns=data.feature_names)
# Convert entire data frame as markdown and print
print(dataframe.to_markdown())
输出:
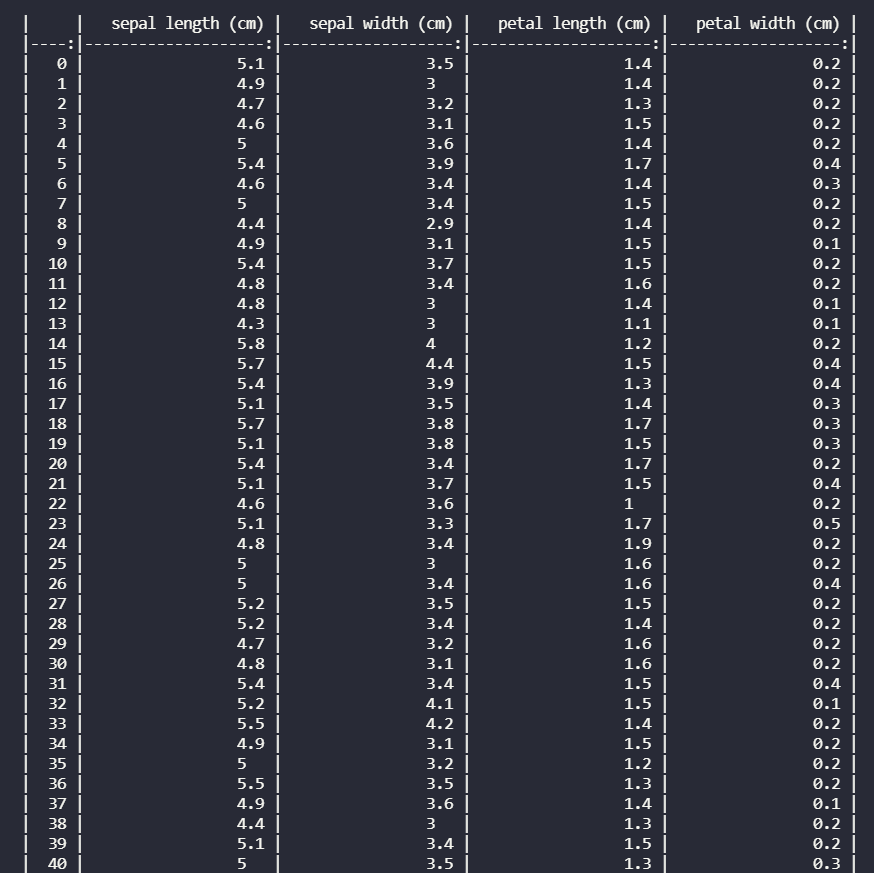
方法 4:使用 option_context()
此方法与 set_option() 方法相同。两种方法都相同,唯一的区别是 set_option() 永久更改设置,而 option_context() 前者仅在其范围内进行。此方法还使用 display.max_rows 作为参数,我们将其设置为 None 以显示数据框的所有行。因此,在将 display.max_rows 的值设置为 None 并将其传递给 option_context 之后,我们将能够看到数据框中的所有行。它的语法与 set_option() 方法相同。
句法 :
with pandas.option_context('display.max_rows', None,):
print(dataframe)代码:
Python3
# Display all rows from data frame using pandas
# importing numpy library
import pandas as pd
# importing iris dataset from sklearn
from sklearn.datasets import load_iris
# Loading iris dataset
data = load_iris()
# storing the dataset as data frame
dataframe = pd.DataFrame(data.data, columns=data.feature_names)
# The scope of these changes
# are local with systems to with statement.
with pd.option_context('display.max_rows', None,):
print(dataframe)
输出:
